Project management
A Knowledge-centric approach
Abstract
"All software is simply a representation of knowledge and it is the acquisition of this knowledge that is the real activity of software development." ~ Phillip Glen Armour [8]
The goal of this article is to help the leaders of software development organizations improve their productivity and make developers happy. For that we will put on the lens of Information theory to differentiate between knowledge discovery and knowledge application in defining an effective software development process. The primary purpose of this process is to show us where we have a lack of knowledge. Not only to show us what we know and what we don't know as much as to show us what we don't know we don't know. We acknowledge that the true role of the development process is to acquire knowledge, and the most valuable knowledge is knowledge we do not already have[8]. Armed with the new understanding we'll take an end-to-end view on the way we manage a software development project.
After that, all the way through the project, day by day, we should be investing effort to identify the knowledge gaps about which we feel most perplexed and how that perplexity is hampering our project the most. As software development is a highly cognitive and mentally demanding activity, it's important to understand how to measure the happiness of developers. A state of "flow" is a key indicator of optimal experience and happiness in work.
How could we know if our efforts at increasing our knowledge are successful? By using all the reporting functionality KEDEHub provides us with. We can check the results on a daily basis if needed. The best is to check on a weekly basis and report every Monday.
The Nature of Project Management
The very definition of a project implies a journey into the unknown. At the outset, many aspects of the project's outcome and the work required to achieve it remain undefined and uncertain. Acknowledging that any project will inevitably face knowledge gaps is crucial for effective project management. Addressing these gaps effectively is the largest part of project management and is key to ensuring predictable delivery in software development projects.
Unlike physical resources, knowledge is both the tool and the product of project management. The effectiveness with which a team acquires, applies, and transfers knowledge directly influences the predictability and success of a project. By effectively managing knowledge—understanding what is known, identifying what needs to be learned, and applying this evolving understanding—teams can navigate uncertainties, solve complex problems, and achieve project goals efficiently. Thus, knowledge is not merely an asset but the fundamental driver of project progress and success.
Central to this perspective is understanding the knowledge gap between what a developer knows and what they need to know to effectively complete tasks. Bridging this gap involves discovering and applying new knowledge.
Knowledge gaps can arise because the project team may lack the necessary knowledge and expertise required to address specific technical challenges or industry-specific requirements.
However, it's important to recognize that knowledge gaps also frequently represent opportunities for innovation, where the team must develop novel solutions to meet both business objectives and technological advancements.
Embracing this dual nature of knowledge gaps—as both hurdles to be overcome and as catalysts for creative problem-solving—enables teams to navigate the complexities of software development with a proactive and adaptive mindset.
In project management, we encounter things that we know and things we don't know. What we do know is the knowledge we possess and are cognizant of, serving as the bedrock for our decisions. Simply put, we are familiar with both the questions and their respective answers.
A large part of project management is managing the unknowns. The outcome of the project and the work required to produce the outcome is unknown at the start. We can distinguish between three categories of missing knowledge:
- Known Unknowns: We recognize gaps in our knowledge and actively seek answers. Essentially, we are aware of the questions we need answered. This echoes Socrates’ famous saying: "I know that I do not know."
- Unknown Unknowns: These are the elusive blind spots we are unaware of, often the culprits behind unforeseen challenges. In other words, we're oblivious to both the questions and their answers.
- Unknown Knowns: These represent our subconscious or tacit knowledge—information we know but may not recognize we do. It's often overlooked, yet immensely valuable. Here, we are acquainted with the answers but not necessarily the questions they address.
Dealing with “known unknowns” is the field of risk management. Dealing with “unknown unknowns” is the field of product management.
Once we are aware that each project contains “Unknown Unknowns”, it becomes evident that a process is needed to:
- show us what we know, what we don't know and what we don't know we don't know
- discover these Unknown Unknowns” and turn them either into “Known Unknowns” or “Known Knowns”
We call this process “knowledge discovery”.
Here is a process that will help manage knowledge discovery in a project:
- Understand your project's complexity
- Staff the team with the talent needed to fill most of the knowledge gaps
- Continuously fill the remaining knowledge gaps
- Monitor progress and adapt strategies as needed
This iterative process aims to acquire new and missing knowledge with respect to the project, through experiments and training.
Understand your project's complexity
The traditional view is that project complexity refers to the degree of difficulty, uncertainty, and interdependence involved in managing and completing a project[3][4].
But what does "difficulty" mean in the context of software development projects? Does it imply developers face challenges while typing?
This is where the knowledge-centric approach to software project estimation and management comes in, which focuses on the acquisition of knowledge as the primary activity of software development[8].
The project is a system composed of the people who will deliver (Capability) and the people who define what to be delivered (Client). The Client is responsible for defining "what to do," while the Capability is responsible for defining "how to do the what."
The complexity of a project can be influenced by both Client and Capability. We group the factors into two clusters based on their ownership and influence by either the Client or the project team (Capability). Here's the breakdown:
Client-owned factors influencing project complexity:
- Requirements complexity: The number, degree of uncertainty, and intricacy of project requirements, as well as their potential for change, can impact the knowledge discovery process. In simpler terms, this factor asks whether the client has a clear understanding of what needs to be done. Projects with numerous or complex requirements, or with clients who are less certain about their desired outcomes, may necessitate more knowledge discovery and learning.
- Client collaboration: In addition to the internal characteristics of projects, it is important to consider the contexts in which projects are executed. The performance of the same project team may vary depending on whether the client is a startup or a Fortune 500 corporation, as the level of collaboration with stakeholders can differ significantly. For example, working with a small startup typically implies that questions are answered promptly and communication is more agile. On the other hand, working with a large organization like a bank often involves slower communication and more bureaucratic processes, which can impact the project's overall efficiency and progress.
Capability-owned factors influencing project complexity:
- Technology expertise: This includes the intricacy of the algorithms, technologies, tools, and frameworks used in the project, as well as the overall architectural design. A project with more advanced or unfamiliar technologies will require more knowledge discovery and learning.
- Codebase knowledge: This factor enables project managers to assess the potential risks, challenges, and dependencies associated with building upon an existing codebase or starting from scratch. It plays a significant role in determining project complexity, particularly when the team needs to familiarize themselves with an existing codebase. The time and effort required to understand the existing code, its architecture, and design patterns can slow down the project's progress, especially in the initial stages. Furthermore, dealing with an existing codebase may present additional challenges, such as technical debt, outdated dependencies, or a lack of proper documentation. These challenges can increase project complexity and affect overall project estimation and management processes. On the other hand, starting from scratch might necessitate more time for initial setup, architecture design, and development, but it also provides an opportunity to leverage the team's prior knowledge and expertise, potentially streamlining the development process.
-
Domain Knowledge:
Every software project operates within a specific domain, whether it's healthcare, finance, retail, or any other industry. Domain knowledge encompasses understanding the unique requirements, constraints, and best practices of that industry. Acquiring this knowledge can be particularly challenging for teams working in unfamiliar domains. The lack of domain expertise can lead to misunderstandings, misaligned priorities, and ultimately, a product that does not meet user needs or regulatory standards.
The problem domain or industry the software is being developed for can influence the amount of knowledge that needs to be acquired. For example, a project in the healthcare industry may involve understanding specific medical terminology, regulations, and processes, which adds to the complexity.
- Team collaboration: The individual knowledge, skills, and expertise of team members, as well as the interdependence between teams or groups possessing specific information required for a project to progress, can influence the amount of knowledge that needs to be acquired during a project. For example, a project staffed primarily with junior developers will likely require more knowledge discovery and learning than a project with a more balanced mix of junior and senior developers. Having an experienced architect on the team can provide a valuable knowledge base and guidance, enabling developers to access the information they need more quickly. Furthermore, effective collaboration and communication between different teams or groups are essential for sharing vital information and addressing project challenges efficiently. Additionally, having dedicated QA team members can help ensure that any incorrect knowledge acquired and applied is identified and addressed more rapidly. This faster feedback loop can prevent the propagation of issues stemming from misunderstandings or lack of knowledge, ultimately improving the project's overall efficiency and quality. In this context, the interdependence among team members and groups plays a crucial role in managing project complexity and ensuring successful outcomes.
-
Development process:
The way the discovery of missing information is managed by the project team. When it comes to discovering missing information, Agile and Waterfall development processes handle this aspect differently:
- Agile methodologies embrace change and encourage continuous learning and adaptation throughout the project. The iterative nature of Agile development enables teams to discover missing information and adjust their plans accordingly as the project progresses. By breaking the project down into smaller, manageable tasks, teams can identify gaps in their knowledge and understanding more quickly and address them before they become major issues. Frequent communication and collaboration among team members and stakeholders further facilitate the identification and resolution of missing information.
- In the Waterfall development process, the discovery of missing information can be more challenging due to its linear and structured nature. The process relies heavily on upfront planning, with the assumption that all requirements and information are gathered and documented before the project begins. As a result, discovering missing information later in the development process can lead to delays, increased costs, and the need for significant rework. Teams following the Waterfall process may find it more difficult to adapt to change and acquire missing information, as doing so may require revisiting earlier stages in the project lifecycle.
It's important to note that while these factors can be categorized based on ownership and influence, there will still be some degree of interdependence between them. Collaboration and communication between the client and the project team (Capability) are crucial in managing project complexity effectively.
In this article we explore how to estimate project complexity using a knowledge-centric approach.
Understand your project's knowledge gaps
The main tool in understanding our project's complexity is the Complexity Profile (CP), detailed further here.
The Complexity Profile (CP) is a tool that categorizes knowledge into three types that the project team must discover to complete a task, user story, or epic:
- Knowledge to be discovered on what to do: This pertains to the overall definition of the task, user story, or epic.
- Knowledge to be discovered on how to do it: This involves the specific steps or methods required to complete the task, user story, or epic.
- Knowledge to be discovered on what to do and how to do it: This encompasses both the overall definition and the specific steps or methods needed to complete the task, user story, or epic.
Project complexity is influenced by both Client and Capability factors, including requirements complexity, client collaboration, team collaboration, technology expertise, domain expertise, and the development process. By considering these factors and assigning a quantity to each quadrant, the CP provides an idea of how much knowledge is required for each aspect of the project.
The need to know a project's complexity arises in two instances: before starting it and once execution begins.
Before Starting the Project
Before commencing work on a new project, we can comprehend its complexity using the process detailed here.
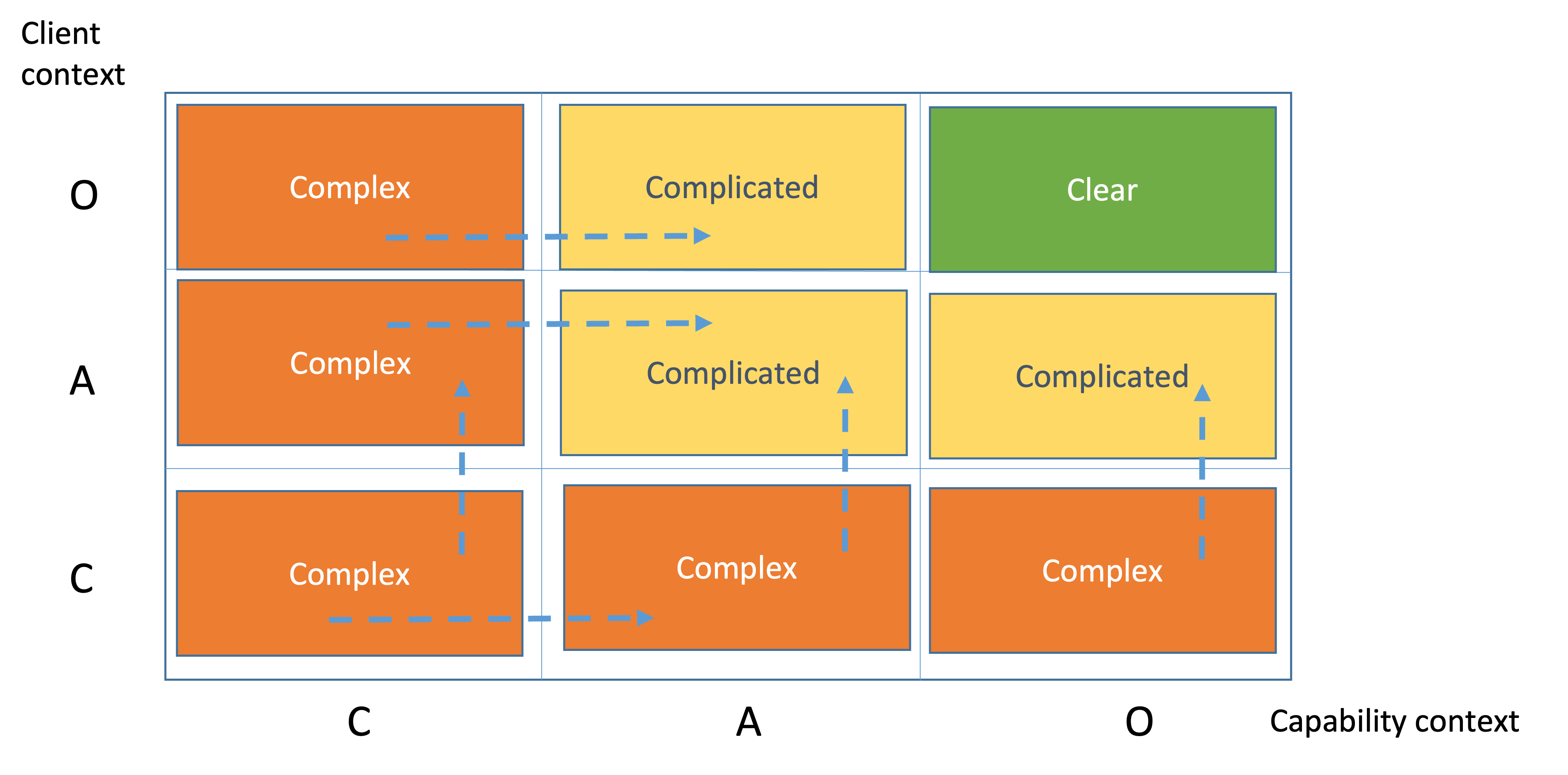
Figure 1 presents the initial Complexity Profile (CP) of our project, representing the perplexity of both Capability and Client about the project as a whole.
Upon establishing the initial complexity profile of our project, we can manage the project's complexity (knowledge gaps) through the following steps:
- Identify knowledge gaps: Determine areas where Client or Capability may lack expertise or where knowledge gaps may exist. This facilitates planning for additional training, research, or external support to bridge these gaps.
- Compare with past projects: Review completed projects with similar complexity levels and identify patterns or commonalities. This helps better understand potential challenges, risks, and opportunities your team may encounter during the project and how to address them.
Starting the Project
For continuously understanding knowledge gaps during our project's execution, we will use the process explained in detail here.
At the end of the first iteration of this process, we will have a detailed operational complexity profile. Figure 2 presents the operational Complexity Profile (CP) of our project, representing the perplexity of both Capability and Client about the user stories.
Filling the knowledge gaps
"Lack of knowledge…that is the problem. You should not ask questions without knowledge. If you do not know how to ask the right question, you discover nothing." ~ W. Edwards Deming
An operational complexity profile is a maneuverable space. Each movement is a clarification. Clarification is a knowledge discovery process. All possible movements between domains are presented below.
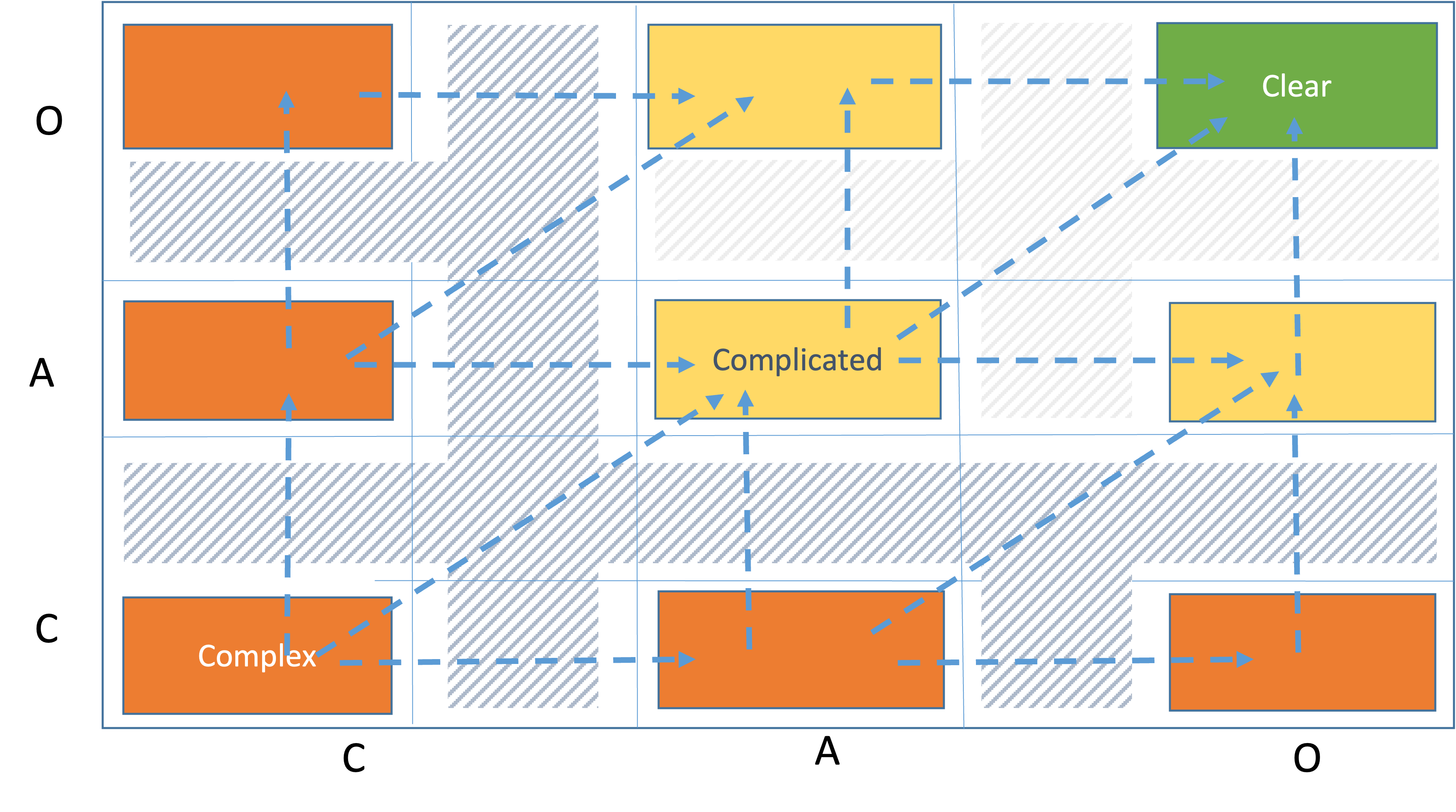
For example, if we want to move a user story from cell CC to cell AA we have several alternative routes:
- Linearly CC -> CA -> AA which means we clarify first from capability then from client perspective
- Linearly CC -> AC -> AA, which means we clarify first from client then from capability perspective
- Diagonally from CC to AA, which means we clarify both from capability and from client perspectives
We also see the transition states between the cells. They are presented in stripes. An user story is in a transition state when it has left a cell but hasn't got into a new cell yet. That means work is being done to clarify the user story.
To clarify a complex user story we employ numerous experiments in parallel which will provide the missing information we need.
Each experiment should be:
- Coherent - to the individual and not the group as a whole, although the group must accept that it is a valid view point.
- Safe-to-fail. That means if it fails we'll be able to recover.
- Finely grained, tangible
As an example, here is a set of axes for experiments that could provide enough knowledge for both Client and Capability perspectives:
- The particular technologies to be used. That is very common in software development where technologies are constantly changing and maturing.
- The way of articulating the problem to be solved — a better model could make the solution obvious.
- The people from the client company to build relationships with.
- The people in the team — their aspirations or fears, their motivation, their relationships with one another and out into the wider organization.
- The client company's organizational constraints i.e. policies, rules, procedures.
- The culture of the client company.
- The third party dependencies and associated risks.
For example, if from a Capability perspective a user story is complex we may decide to do a Proof of Concept (PoC). We do that by preparing a concept with a couple of alternatives. Then the card will follow CC -> AC, and stay in transition until the PoC provides some missing information. If the results from the PoC have narrowed the perplexity we have made the user story complicated and the card will make AC -> AA. Another example, if a user story is complex from client perspective then the Capability could work with the Client by presenting alternatives. This is what software development experts do - provide alternatives not only about how to do but also what to do. When providing alternatives to the client about what to be done we have the chance to move the work through the CP in a direction that best suits our capabilities. One may say that clients who don't know what they want are the best!
Staff the team with the talent needed to fill most of the knowledge gaps
Understanding your project's complexity would show the expertise you need to acquire certain knowledge areas. Each of these areas presents unique challenges that must be addressed to ensure project predictability.
In general, the team should include professionals with strong technological proficiency, who stay updated with the latest technologies, programming languages, and frameworks, through regular training and hands-on experimentation. Domain experts are crucial for understanding industry-specific requirements and constraints, ensuring the project aligns with industry standards. Business analysts or stakeholders with business acumen are needed to align the project with business goals, target audience needs, and market dynamics. Integration specialists are essential for seamlessly integrating new solutions with existing systems, maintaining compatibility and data integrity. Compliance experts are necessary to navigate legal and regulatory requirements, conducting regular audits and ensuring adherence to standards. Finally, security professionals are vital for implementing robust security measures, performing regular audits, and staying ahead of potential threats. By assembling a team with these diverse skills, project managers can effectively address knowledge gaps and enhance the predictability of software development projects.
We need different people to work on different knowledge gaps. The difference is the level of perplexity they can handle both from Capability and Client perspectives. For instance:
- If the problem is clear then we need a junior person, who can read a recipe book and follow it. She will need stable requirements and all the exact tools and technologies from the book.
- If the problem is complex we need a senior person, who can cope without a recipe, with changing requirements and with whatever is available in terms of tools and technologies.
When we need to adapt we need more diversity in the system because then we've got more evolutionary capacity. It's not a coincidence that for the living organisms the mutation rates increase under stress - more diversity more, adaptability. The requisite diversity is the optimal level of diversity for the context we are in. Diversity means inefficiency an organization needs to have. If overfocused on efficiency the organization loses adaptive capacity.
Diversity can help us answer the question posed by Brooks' Law[9]. The question is, "if I have a project that is running late, should I add people to it to speed it up?" Our answer is, "it depends on how you manage knowledge discovery." If the project scope is partitioned into work items classified using the Complexity Profile explained here, then you'll have Clear and Complicated work that can be given to the newcomers. That will free up your present developers to do more Complex work clarifying. Then the answer is "yes." The answer would be "No" if the addition of people will require that your current staff take time away from being productive to instruct the newcomers, resulting in a net drop in productivity. Hence, Brooks' Law: adding manpower to a late project makes it later.
Knowledge discovery funnel
"The organization and the people within it need to discover a quantity of knowledge that they do not have, and factor that knowledge into something that works." ~ Phillip Glen Armour[8]
We see that the complexity profile serves us as a map to show how we can move to reach our target level of perplexity. It helps us act in order to move toward reduced perplexity.
This dynamic can be presented in a simpler way as a movement through a funnel as shown on Figure 4.
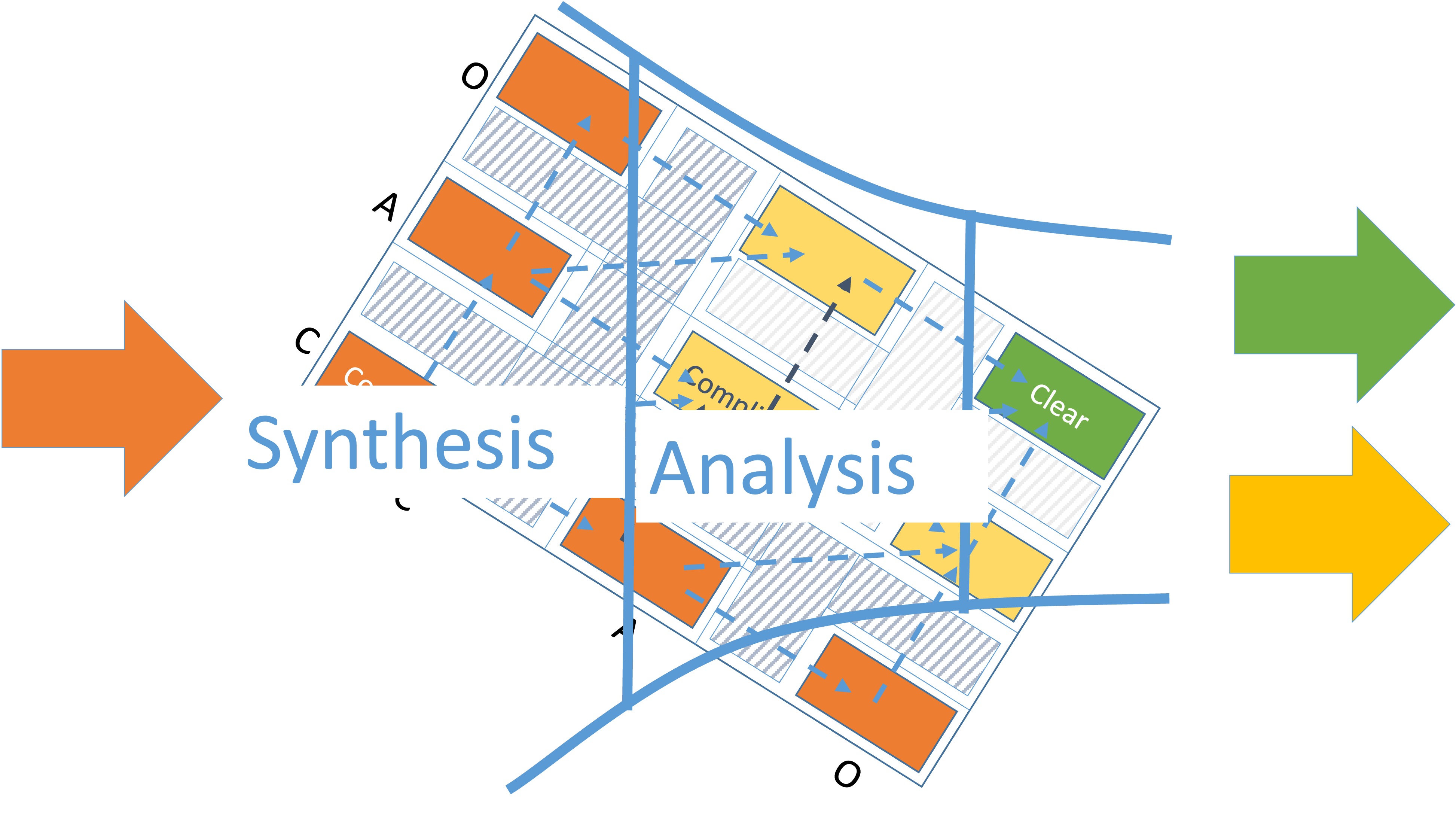
We have rotated the complexity profile 45 degrees so that the lines of movement from complex to complicated and from complicated to clear are horizontal.
Clear stories let delivery to focus on capturing and codifying prior knowledge.
The flow through the funnel should not be in a rush. Especially if the knowledge gaps are numerous, complex, and interrelated. It must enable efficient and effective learning to close the identified knowledge gaps. Otherwise, bad decisions would be made and cause rework that would be very costly to the project. Delaying decisions will help you deal with making critical decisions with insufficient knowledge and simultaneously keep multiple options open until knowledge gaps are closed.
Synthesis
In philosophy, synthesis refers to the process of combining different concepts to create a new, more comprehensive understanding of reality.
- Objects (substances) refer to the basic building blocks of reality. They are independent entities that exist and persist through time, and have properties that determine their nature and identity.
- Properties, on the other hand, are qualities or attributes that belong to objects. They are what make objects what they are and distinguish them from other objects. Examples of properties include color, shape, size, and texture.
- Relations refer to the ways in which objects are connected to one another. Relations can be between objects or between objects and properties. Examples of relations include causality, spatiotemporal proximity, and functional dependency.
By considering the objects, properties, and relations that exist in the problem domain, software developers can synthesize a more comprehensive solution that better captures the underlying reality of the problem.
In the first step of synthesis we take the thing we want to understand as a part of a larger whole, hence it is put together with other things, not taken apart. We need to consider the parts not on their own, but in relation to the whole. We need to identify the contours of a system.
“Matter tells space how to curve, and curved space tells matter how to move.” ~ John WheelerWe describe the space itself, not its features. Features of the system will emerge from the space if you did this. In the second step of synthesis, we explain the behavior of the larger whole. So if we are trying to understand a business, we have to first explain the market system the business is a part of. In the third step of synthesis, the behavior or properties of a part is explained by revealing its role or function in the system that contains it.
As an example, consider the problem domain of a new e-commerce web site. The objects in this domain include products, customers, orders, and payment methods. These objects have properties such as product name, price, quantity, customer name, address, payment type, and so on. The relations between these objects include:
- Products and customers: A customer can purchase one or more products.
- Products and orders: An order contains one or more products.
- Orders and customers: An order is made by a customer.
- Orders and payment methods: An order requires a payment method to be completed.
By considering the objects, properties, and relations in this problem domain, a software developer can synthesize a new e-commerce web site that better captures the underlying reality of the problem. For example, the developer may decide to implement a feature that allows customers to easily view their purchase history, based on the relation between orders and customers. Or the developer may decide to implement a feature that displays related products, based on the relation between products.
Analysis
Analysis is a systematic and detailed examination of a subject or issue, with the aim of breaking it down into its component parts, understanding their relationships and interconnections, and examining their properties and characteristics. The goal of analysis is to gain a deeper understanding of the subject being studied and to identify patterns, structures, and relationships that are not immediately apparent.
In the context of software development, analysis refers to the process of evaluating and breaking down a problem or system into its component parts in order to understand its requirements, constraints, and design considerations. This information can then be used to inform the design and development of a new system or solution that better meets the needs and requirements of the problem domain.
Analysis means obtaining answers to known questions.
Let's consider the objects "Products" and "Customers" in the problem domain of an e-commerce web site, and the relation between them, which is "A customer can purchase one or more products."
To analyze these objects and their relation, we can start by asking questions about their properties and the ways in which they interact. For example:
- What properties do products have? Some properties may include name, description, price, image, category, brand, and so on.
- What properties do customers have? Some properties may include name, email, address, payment information, purchase history, and so on.
- How does the relation between products and customers affect the design of the e-commerce web site? The relation between products and customers may influence the way that the site is structured, the features that it provides, and the information that is displayed to users.
Based on this analysis, we can synthesize a solution that better captures the underlying reality of the problem domain. For example, the solution may include features such as:
- A product catalog that allows customers to easily browse and search for products.
- A customer account system that stores and manages customer information, such as purchase history and payment information.
- A checkout process that allows customers to purchase products and manage their orders.
By considering the objects, properties, and relations in the problem domain, and synthesizing a solution based on this analysis, we can create an e-commerce web site that provides a better experience for customers and meets their needs more effectively.
Synthesis vs. Analysis
Analysis yields information about the structure of a system, and how it works. That's knowledge, know-how, not understanding. If we apply analysis to a system, we begin by breaking it apart and we lose all of its essential properties. We cannot explain the behavior of a system by analysis. Analysis cannot produce understanding of systems. We cannot examine a system by looking at its parts, you must look at it as a part of a larger whole. We can reveal its structure and all individual actions, but we can't say why it works the way it does. Explanation never lies inside the system, it lies outside.
Unfortunately, analysis and thought are frequently treated as synonyms, but analysis is only one way of thinking; synthesis is another. We should use the synthesis to achieve a whole system's perspective. Synthesis does not mean “studying a whole as a synthesis of its parts” but “studying a whole as part of a larger system.” Synthesis yields understanding, analysis yields knowledge, and it was that distinction that was critical for the emergence of the systems thinking. It uses both, but to understand systems, particularly those that involve people, synthetic thinking is required.
Standardization
How to reduce variability and increase certainty about your project’s delivery time and/or functional expectations? By improving your project’s knowledge discovery efficiency!
How to do that? By using standard, routine, boring of-the-shelf components for the standard, routine and boring functionalities.
Most of the software being developed today is reinventing the wheel due to lack of knowledge about existing solutions and boredom on the side of the tech professionals when using existing solutions. Software development projects must use standard, routine, boring but very robust components. That would reduce uncertainty and mitigate security risks. That would also allow junior people to be trained and realize their talent on implementing the standard, routine and boring functionalities.
For instance - your team needs to implement a very common functionality - authentication and authorization. Authentication is the process of verifying who someone is, whereas authorization is the process of verifying what specific applications, files, and data a user has access to. Imagine that instead of using an existing component like Keycloak they decide to develop one such server from scratch. They will need a lot of new knowledge to discover - thus very inefficient in terms of knowledge discovery.
It is about talent, so effective talent usage would mean: develop what was needed. Efficient talent utilization is: develop what was needed with as little new knowledge required as possible.
Flow
“A bad system will beat a good person every time.” —W. Edwards Deming
Software development is a process of going from 0% knowledge about an idea to 100% knowledge of a finished product ready for delivery to a customer. In its simplest form, the job of software development is to reduce the number of unknowns to zero by the time the system is delivered. It is a process of knowledge acquisition and ignorance reduction[8]. HThen, we can model the software development process as a knowledge discovery process. The goal is to iteratively identify knowledge gaps, reduce our perplexity, increase our knowledge and close the identified knowledge gaps.
It is also a continuous process rather than a punctuated process. This means that moment by moment on the project, ignorance is identified, questions are asked, answers are obtained and validated, and knowledge is discovered[8]. We need to find the knowledge to be discovered for each user story. That knowledge is the difference between the missing information and our prior knowledge.
Quite commonly, we underestimate how much knowledge we have to discover to deliver the functionality to the customer, or overestimate our prior knowledge, which is the same thing.
People in general and software developers in particular are happy when working in a state of Flow. Flow experiences lead to an increase in productivity. When the flow conditions have been met they create a flow loop between action and feedback that allows for continuous and effortless tuning of performance while taking action. Flow loops make an activity worth doing for its own sake[2].
Entering flow depends on establishing a balance between perceived individual skills and perceived task challenges. Said in another way - capability should match work complexity.
After that the developer must receive immediate feedback that allows them to continuously adjust their performance as they tackle these challenges. This kind of feedback communicates how well they are performing and how they can improve their performance.
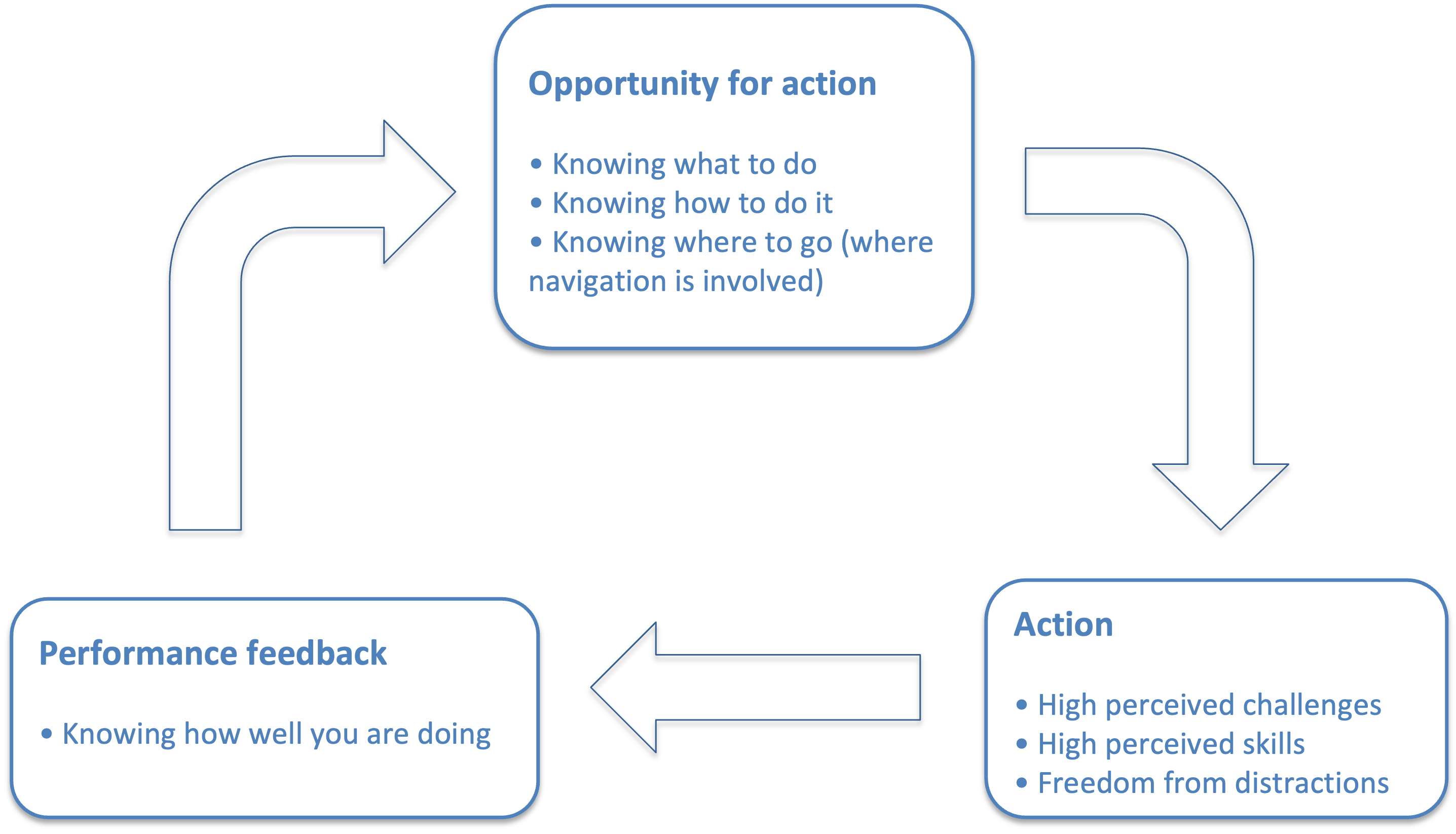
By measuring how well project policies and processes meet the flow conditions we can engineer a project organization that facilitates flow.
From a project management perspective there are two areas we need to create.
- Conditions for flow. That means breaking down the project into disjoint units of work. For each task the three flow conditions should be in place.
- Action and performance feedback. Tasks distribution so that each of the developers has a proper challenge for their skills. A feedback mechanism should be in place to tell developers how well they are doing.
Creating conditions for Flow
“The goal is to make full use of the workers' capabilities by building up a system that will allow the workers to display their full capabilities by themselves.” ~ Y. SUGIMORI, K. KUSUNOKI, F. CHO & S. UCHIKAWA (1977) Toyota production system and Kanban system
In order to have conditions for flow for each user story we need to find a balance between their perceived individual capabilities and the complexity. This balance should be tailored to the individual developer, with a slight preference for challenging tasks. To determine this balance, an assessment of the developer's individual capabilities and the complexity of the task is necessary. This assessment requires accurate and reliable information about both of these factors.
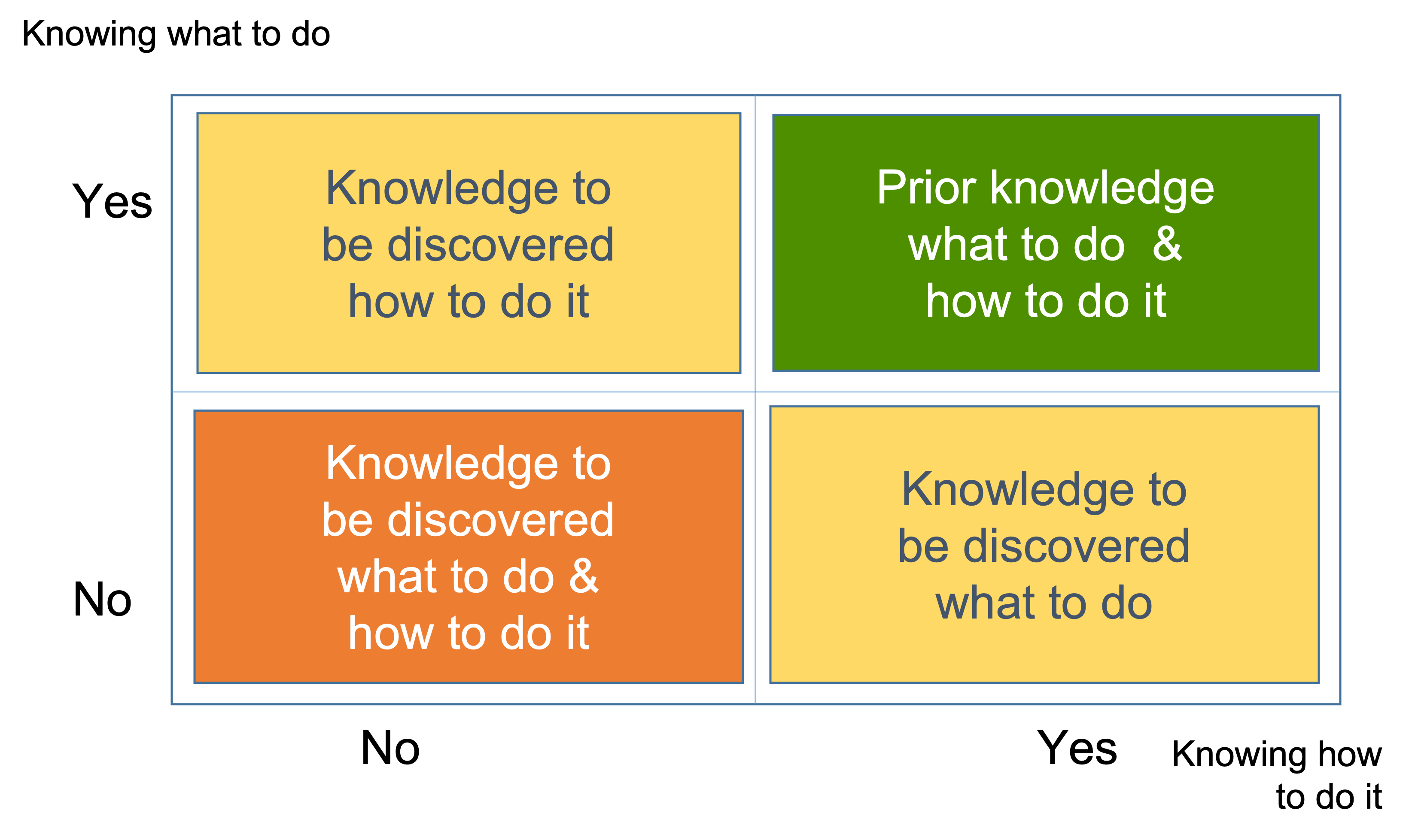
There are two types of knowledge that a software developer must discover in order to complete a task:
- Knowledge to be discovered on what to do: This refers to understanding the task and its objectives
- Knowledge to be discovered on how to do it: This refers to knowing the methods and having the skills needed to complete the task
We refer to the developer's perception of the task complexity as "required knowledge." Bear in mind that the perception of knowledge to be discovered may vary among developers and could evolve over time for a single developer as they refine their skills and task understanding. It is also important to recognize that a developer's perception of required knowledge may not always align perfectly with the actual requirements of the task, and it may be necessary to provide additional training or support to bridge any gaps.
Prior knowledge on what to do and how to do it has already been discovered. This "prior knowledge" provides a starting point for the software developer, but additional knowledge must still be acquired in order to complete the task.
It is more convenient to represent the four combinations of required and prior knowledge in order to complete a task in a matrix, which we will refer to as Complexity Profile (CP), which is explained here.
The diagram is intended to help visualize the balance between individual capabilities and work complexity that is necessary for a developer to be in a state of flow when working on a task. Each of the four subspaces in the diagram represents a combination of required and prior knowledge, which we refer to as knowledge to be discovered, or the information the developer needs to gain in order to complete a task.
To achieve a balance that is on a personal, individual level, with a slight tilt towards challenges, the developer needs to pick a task with a required-prior knowledge combination from one of the yellow quadrants that has a missing information between 2 and 4 bits. That means, there are up to 16 alternatives and it requires at least 1 and up to 4 questions asked in a row, in sequence, linearly.
Action and performance feedback
After a clear goal for a user story has been established i.e. what to do and how to do it, it is important to ensure that each individual developer has a balance between their abilities and the complexity of the user story. This balance should be on a personal, individual level, with a slight tilt towards challenges. To achieve this, we aim to have a missing information between 2 and 4 bits, which corresponds to user stories that are considered "complicated" and require some analysis by the developers.
To ensure that the balance is achieved, it is important to have a way to measure the complexity of a user story and personal abilities using bits of information. However, measuring the perplexity a developer feels when looking at a user story is difficult, if not impossible.
One way to evaluate whether a developer's abilities and work complexity were in balance is by measuring the Knowledge Discovery Efficiency (KEDE) after the work has been completed, as explained here By analyzing KEDE, we can determine whether the project management process is making developers happy. If it is not, we can make changes to our process accordingly.
Initial vs. Continuous Discovery
The Initial Knowledge Discovery runs without Delivery i.e Knowledge application. It may result in a Product Vision, Product Strategy, and initially validated Business Model that has a chance of achieving the Product-Market Fit. The Initial Knowledge Discovery can serve as a base for investment decisions.
After the Initial Knowledge Discovery we establish a regular feedback loop to continuously revisit and update the categorization of the user stories in progress and categorize the newly added user stories.
It needs to be emphasized that we don't get a full process specification, and analyze it all before starting delivery. Instead, we do the Initial Knowledge Discovery oly to have the categories for the project defined. For that we need a small subset of the requirements for the project. After that we run a continuous iterative process that flows through Knowledge Discovery and Delivery user stories in small batches.
If the project team is a Scrum team then the batch could be a Sprint backlog.
Product management
The Knowledge Discovery can be run by Product managers and Product owners. Then it can be called Product Discovery.
For each option in the Product Options part of the End-to-end board the following questions need to be asked.
- Value. Will it create value for the customers?
- Usability. Will users figure out how to use it?
- Viability. Can our business support it?
- Feasibility. Can it be done?
- Ethic. Should we do it?
Dual-Track Agile
Jeff Patton and others in the Agile product space have been big proponents of an approach called Dual-Track Development or Dual-Track Agile[6]. In that setup, there are two streams that run in parallel:
- Product Discovery - to discover the product to build
- Product Delivery - to deliver that product to the market
The difference with the approach presented in this article is that here we don't have two activities in parallel. Instead we have two activities Discovery and Deliver running sequentially, but at their own pace and with their own variation.
Works Cited
1. Bakardzhiev, D. (2016). Adaptable or Predictable? Strive for Both - Be Predictably Adaptable! InfoQ. https://www.infoq.com/articles/predictably-adaptable/
2. Schaffer, O. 2013. Crafting Fun User Experiences: A Method to Facilitate Flow. Human Factors International Whitepaper. Retrieved from: https://scholar.google.com/scholar?cluster=9760324565241258858
3. L.-A. Vidal and F. Marle, “Understanding project complexity: implications on project management,” Kybernetes, vol. 37, no. 8, pp. 1094–1110, 2008. View at: Publisher Site | Google Scholar
4. José R. San Cristóbal, Luis Carral, Emma Diaz, José A. Fraguela, Gregorio Iglesias, "Complexity and Project Management: A General Overview", Complexity, vol. 2018, Article ID 4891286, 10 pages, 2018. https://doi.org/10.1155/2018/4891286
5. Q&A with Claudio Perrone on PopcornFlow
6. Dual Track Development is not Duel Track
7. The Mindset That Kills Product Thinking
8. Armour, P.G. (2003). The Laws of Software Process, Auerbach
9. Brooks, F. P. (1995). The mythical man-month: Essays on software engineering. Addison-Wesley
How to cite:
Bakardzhiev D.V. (2022) Project management : A Knowledge-centric approach https://docs.kedehub.io/kede-manage/knowledge-discovery-management.html
Getting started


