Forecasting how big is your project
Using Randomized Branch Sampling (RBS)
Abstract
Randomized Branch Sampling (RBS) is a multi-stage unequal probability sampling method originally designed for efficiently forecasting the total number of fruits in a tree canopy. In the context of software development, RBS can be applied to estimate the missing information at the beginning of a project by mapping a product backlog to a branching system. The project scope is divided into epics, which are further broken down into user stories. The RBS method leverages conditional selection probabilities and unbiased estimators to estimate the total missing information in bits for the project.
The application of RBS for forecasting missing information in bits in a new software project offers a unique approach that goes beyond what traditional methods typically cover.
However, applying RBS to software projects requires an accurate and comprehensive initial understanding of the project's scope, as well as a consistent methodology for managing requirements, breaking down the product into stories, and sizing a story. Additionally, the dynamic nature of software development necessitates continuous re-evaluation and refinement of project size estimates using RBS as the project progresses and requirements change. When applied correctly, RBS can provide valuable insights into the missing information at the outset of a software project and aid in project planning and management.
Randomized Branch Sampling (RBS)
Randomized branch sampling (RBS) is a multi-stage unequal probability sampling method that was first proposed by Jessen[1][3][4]. It is designed to efficiently estimate the total number of items (such as fruit on a tree) without having to count them all. Instead, the technique focuses on counting the items on select branches, providing unbiased estimates at the tree level. RBS does not require prior identification of all branches, and provides the sampler with unbiased tree level estimates.
RBS works by selecting branches along a pathway that starts at the base of the tree and travels upwards. At each fork, selection probabilities are calculated proportional to the size of each limb emanating from the fork. A random number is generated to determine which limb the path continues along. This process is repeated until a terminal branch is selected, which is small enough for the number of items to be easily counted. By combining the number of items on the terminal branch and the associated probability with which that particular branch was selected, an overall tree-level estimate is derived.
One of the main advantages of RBS is that it doesn't require the user to have prior knowledge of or take measurements on all branches in the crown. This makes it an efficient and effective sampling scheme in the field.
RBS applied in software development
RBS was designed to efficiently estimate the total number of fruit found in the canopy of a tree while only having to count the fruit on select branches. With RBS, branches are selected from the tree by creating a pathway which starts at the base of the trunk and travels upwards. In order to apply RBS for sizing a software project we will represent a product backlog as a branching system.
The product backlog is the work that needs to be accomplished to deliver a product with specified features and functions. The features and functions are called requirements and are presented and managed using vehicles such as epics and user stories. Epics are the highest-level requirements artifact. Epics are not implemented directly but are broken into user stories, which are the work items used for planning purposes. Epics are not directly testable. Instead, they are tested by the acceptance tests or scenarios associated with the user stories that implement them. Even for a quality related requirement such as “the system should scale horizontally” we need to have a user story. Each one of the user stories should represent independent customer value and could be delivered in any order following the INVEST mnemonic.
Mapping of three to backlog
| Product | Trunk |
| Epic | Branch |
| User Story | Terminal Shoot |
| Bits per story | Number of Fruit on the Shoot |
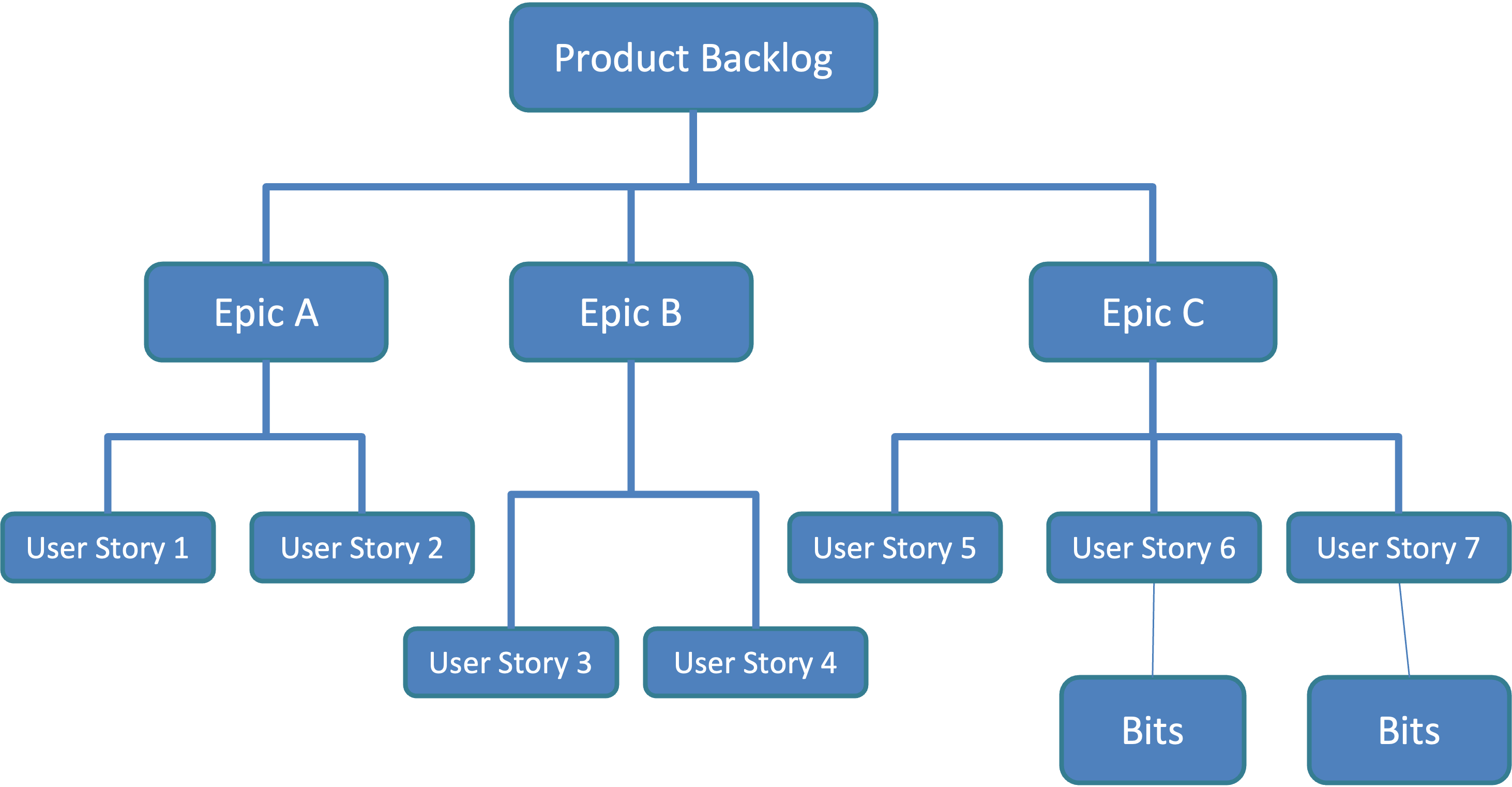
In Fig. 1, we have a fictitious product backlog that is divided into three epics A, B, and C.
In RBS a Horvitz-Thompson estimator[5] is used to derive an unbiased estimate of the total amount of missing information in the the product backlog. It is obtained by dividing the size (x) of a selected user story (i) by its associated unconditional probability Pi with which that particular user story was selected.
where Hi is the missing information in bits of a selected user story (i) and Pi is associated unconditional probability for the same user story (i).
An unconditional selection probability Pi is obtained using the formula:
where pj is the selection probability of the jth epic and pi is the selection probability of the ith user story in the jth epic.
An unconditional selection probability Pi is obtained from the conditional selection probability of the user story when considering the conditional probabilities of the product backlog and the epic the story belongs to. Since there is only one product backlog, its conditional selection probability is 1.
We need to know the total number of epics, but there is no requirement to know the total number of user stories in the product backlog. We break down only the epics that are randomly selected into user stories. We use the total number of epics to calculate the conditional probabilities at the epic level and the total number of user stories per selected epic to calculate conditional selection probabilities at the story level. For example, in Fig.1, since there are 3 epics in total in the product backlog, each epic's selection probability is 1/3.
The total number of missing information (knowledge discovered) in bits for the project is calculated using the formula:
wehere H is an unbiased estimator of the total missing information in bits for the project and m is the number of estimates performed.
We will determine the conditional selection probabilities using PPN (probability proportional to number). PPN is a sampling technique in which the probability of selecting an item is proportional to its size (in this case, the number of user stories within an epic). In this scheme, we need to know the total number of epics, but there is no need to know the total number of user stories in the product backlog.
To apply RBS for forecasting the missing information in a software project using the proposed mapping of a tree to a product backlog, follow these steps:
-
Start at the product level (trunk) and divide the project scope into epics.
For example, in Fig.1, the product backlog contains 3 epics in total.
- Randomly sample one of the epics. Duplicates are allowed.
-
Break the sampled epic into stories.
Number the stories sequentially starting from 1.
For example, in Fig.1:
- Epic A splits into two user stories 1 and 2, hence they both have a selection probability of 1/2.
- Epic B splits into two user stories 3 and 4, hence they both have a selection probability of 1/2.
- Epic C splits into three user stories 5, 6, and 7, hence they all have a selection probability of 1/3.
- Randomly sample one of the stories from the epic from step 2.
- Repeat steps 2-4 between 7 and 11 times.
After completing the sampling process, you should have equal numbers of epics and user stories selected. Then, follow these steps:
- Estimate the missing information in bits for each of the selected user stories. You can find detailed explanations on how to do this here.
-
Using formula (2), calculate the conditional probability for each of the selected user stories.
For example, in Fig.1, we obtain the unconditional selection probability P1:
- for story 1, 1/3x1/2=1/6;
- for user story 4, 1/3x1/2=1/6;
- for user story 7, 1/3x1/3=1/9 etc.
- Using formula (1), calculate one estimate of the total bits for the project.
- Using formula (3), calculate the total amount of missing information for the project.
Why RBS works?
RBS is an unbiased estimation technique, which means that if you were to perform the sampling process many times and average the results, you would expect the average to be close to the true value of the parameter you're trying to estimate — in this case, the missing information in a software project.
The unbiasedness of RBS is one of its strengths, as it helps to reduce systematic errors in the estimation process. However, it is still important to consider other factors that can influence the accuracy of the estimates, such as the representativeness of the samples and the assumptions made about the distribution of missing information within the project.
The number of fruit found in the canopy of a tree has an inherent, abstracted from its interpretation, objective value. Counting all the fruit should always produce the same number plus or minus some counting error. When we apply RBS to find the number of fruit the fruits are already there.
The size of a software project has no objective value. It is intangible - a proxy for all the capabilities (features and functions) the final product is required to offer when delivered to the customer. But requirements on a software project change over time and for a good reason. We are learning as we work on the project. We will discover new requirements and decide others are no longer valid. Hence at the beginning of a project when we apply RBS to forecast its size the user stories are not available yet. The full set of user stories will be there when we finish the project. That leads to the question - from what universe of user stories we sample using RBS?
The assumption behind using RBS for software development is that project size depends on the context - the customer, the people developing the product and the methodology they use for managing the requirements, breaking down the product into stories and sizing a story. It doesn't matter what the methodology is. What is important is the methodology to be cohesive, explicit and to be consistently applied during project execution when we slice the requirements into user stories.
Here are a few important points:
- We emphasize that RBS, when applied to software projects, operates under the assumption that the initial set of user stories and epics are representative of the project scope. While it's true that requirements may change over time, the RBS method's effectiveness depends on having a reasonably comprehensive and accurate initial understanding of the project's scope.
- The methodology used for managing requirements, breaking down the product into stories, and sizing a story should be cohesive, explicit, and consistently applied. This is an important point, as inconsistencies in these processes can affect the accuracy and reliability of the RBS estimates.
- It's worth mentioning that RBS, when applied to software projects, may require additional iterations and adjustments as the project progresses and new requirements are discovered or existing ones are modified. RBS can be used as a tool for continuous re-evaluation and refinement of project size estimates.
The step-by-step process we've outlined provides a structured approach to breaking down the project into epics and user stories, sampling them, and forecasting the missing information. By repeating the process several times, you can minimize potential errors in the estimation and get a better understanding of the overall project scope.
However, keep in mind that this method, like any other estimation technique, has its limitations and assumptions. It assumes that the sampling process is unbiased and that the distribution of missing information within the project is relatively consistent. It is also essential to consider other factors, such as team expertise, project history, and stakeholder input, when forecasting the missing information in a software project.
In summary, while RBS can be applied to software projects, it is essential to acknowledge the dynamic nature of software development and the need for consistent methodologies in managing requirements, breaking down the product into stories, and forecasting the missing information for a story. The success of RBS in this context largely depends on the initial representation of the project scope and the adaptability of the method as the project evolves.
Appendix
Traditional methods for size estimation
Traditional methods focus on forecasting size, effort, or duration and provide a foundation for understanding the broader context of estimation in software projects. Traditional methods often prioritize quantifiable measures such as story points or man-hours.
Some of the traditional ways for forecasting the size of a new software project include:
- Expert judgment: Experts in the domain or team members with relevant experience provide their best estimates for project size, effort, or duration based on their knowledge and past experiences.
- Analogy-based estimation: This technique compares the new project to similar, completed projects to derive estimates. By identifying the similarities and differences, estimators can adjust the size, effort, or duration estimates accordingly.
- Parametric estimation: This approach uses mathematical models and historical data to estimate project size, effort, or duration based on specific project attributes or parameters. Examples of parametric estimation methods include COCOMO (Constructive Cost Model) and SLIM (Software Lifecycle Management).
- Bottom-up estimation: The project is broken down into smaller components or tasks, and each component is estimated individually. The estimates for these smaller components are then aggregated to calculate the overall project estimate.
- Top-down estimation: An initial high-level estimate is made for the entire project based on the project's overall scope and requirements. This estimate is then refined and broken down into smaller components or tasks, and their estimates are calculated accordingly.
However, some aspects of traditional methods can indirectly address missing information. For example, risk analysis and gap analysis can help identify areas of uncertainty and knowledge gaps, but they don't necessarily provide a quantifiable measure in bits.
- Knowledge acquisition techniques: Techniques such as interviews, workshops, brainstorming sessions, and document analysis can be employed to discover missing information at the beginning of a project. By assessing the knowledge gaps and refining requirements, you can estimate the amount of missing information in bits.
- Gap analysis: Identify the differences between the current knowledge state and the desired state of a project. This analysis can help in forecasting the missing information in bits by assessing the extent of knowledge gaps that need to be filled.
- Risk analysis: Perform risk assessments to identify potential uncertainties and unknowns in a project. By analyzing these uncertainties, you can estimate the amount of missing information that needs to be discovered.
While these approaches don't provide a direct quantification of missing information in bits, they can help provide insights into the level of unknowns in a project.
Works Cited
1. Jessen, R. (1955). Determining the Fruit Count on a Tree by Randomized Branch Sampling. Biometrics 11, 99–109.
2. Bakardzhiev, D.V.. (2016). Probabilistic Project Sizing Using Randomized Branch Sampling (RBS) InfoQ. https://www.infoq.com/articles/probabilistic-project-sizing/
3. Good NM, M. P. (2001). Estimating Tree Component Biomass Using Variable Probability Sampling Methods. Journal of Agricultural, Biological, and Environmental Statistics, pp. 258–267.
4. Timothy G. Gregoire, H. T. (1995). Sampling Methods to Estimate Foliage and Other Characteristics of Individual Trees. Ecology, Vol. 76, No. 4, 1181-1194.
5. D. G. Horvitz & D. J. Thompson (1952) A Generalization of Sampling Without Replacement from a Finite Universe, Journal of the American Statistical Association, 47:260, 663-685, DOI: 10.1080/01621459.1952.10483446
How to cite:
Bakardzhiev D.V. (2023) Estimating how big is our project? https://docs.kedehub.io/kede-manage/kede-manage/kede-rbs.html
Getting started


