Frequently Asked Questions
About KEDE and KEDEHub.
Related Articles
What is KEDE?
Work comprises cognitive and manual labor. Manual labor involves physical effort to produce tangible results, while cognitive labor requires thinking and decision-making to address the essential questions of "what," "how," and "why" a task is performed.[2]:
- What needs to be done?
- How should it be done?
- Why is it being done?
Each of these questions can be broken down into increasingly detailed sub-questions. This process continues until a clear understanding is reached, enabling the individual to proceed with manual labor. Importantly, cognitive labor always precedes manual labor because tasks require planning, decision-making, or problem-solving before execution.
For each task, Required Knowledge represents the complexity of the task, i.e. what must be known to complete it, while Prior Knowledge refers to the skills, experience, and understanding an individual already possesses. The gap between these two is the Knowledge to Be Discovered. It represents what the individual thinks they don't know, given what they think they do know. Any uncertainty or need for additional clarity about a task implies the existence of some form of a knowledge gap - even if it is small or subtle.
Questions are the cognitive tools we use to close knowledge gaps. Questions arise only when there is Knowledge to Be Discovered. The existence of any question implies a perceived gap in knowledge, understanding, or certainty. Whether the gap is large (fundamental knowledge is missing) or small (details need confirmation or alternatives are being explored), the act of questioning reflects the Knowledge work i.e. the effort to bridge that gap. Conversely, if an individual believes they know everything necessary about a task, there is no uncertainty, and no questions arise.
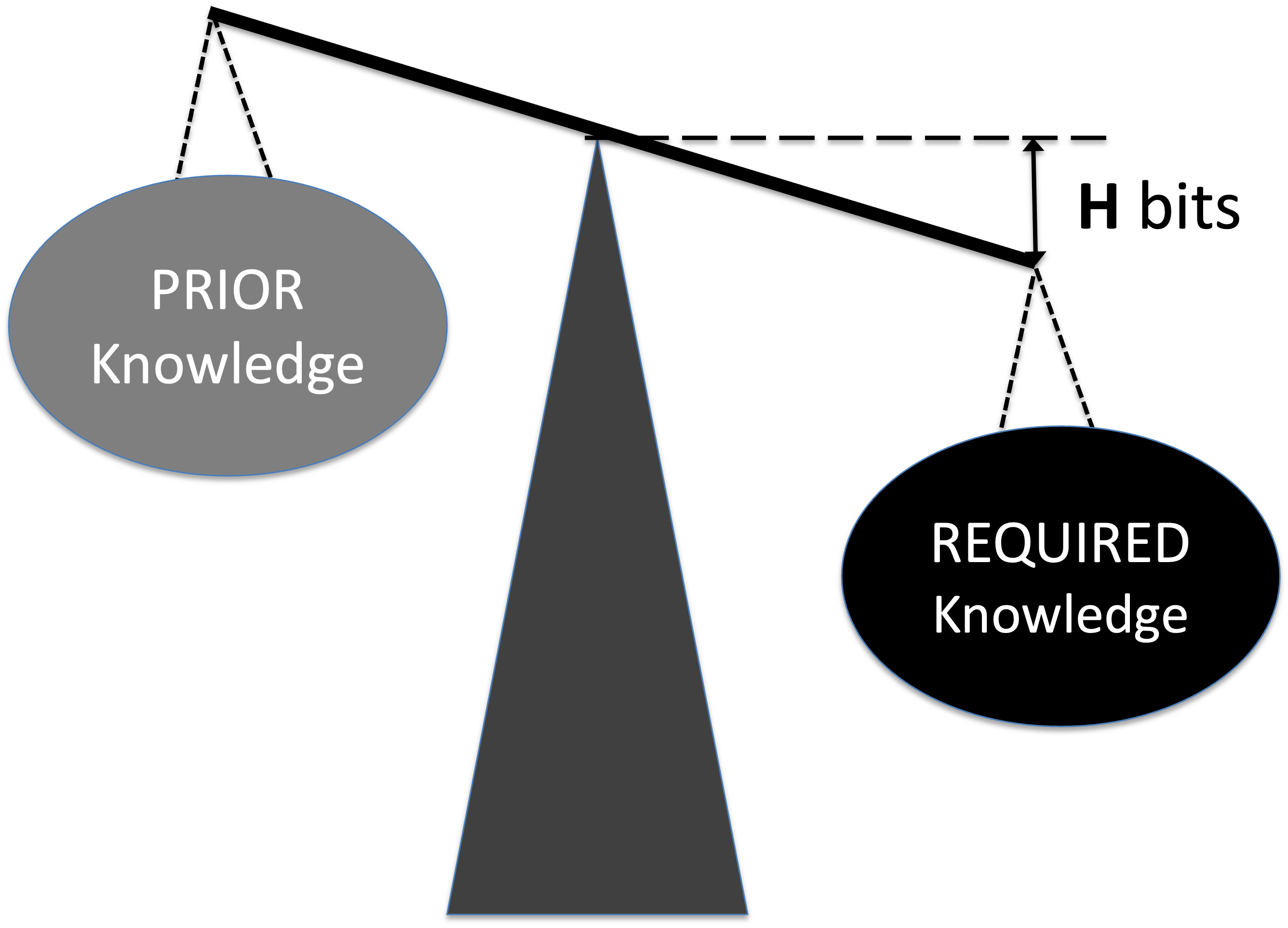
- Imagine a scale: on one side is the required knowledge and on the other is the prior knowledge.
- They will be balanced if they are equal, implying that the knowledge to be discovered equals zero.
- When balanced, no further knowledge is needed; when imbalanced, knowledge acquisition is required.
- The gap H between required and prior knowledge is the Knowledge to Be Discovered.
The Knowledge to Be Discovered is measured in bits of information and can take values between 0 and infinity. That is difficult to use for comparing efficiency in different contexts. Using mathematics we convert the bits of information H into an efficiency index and define Knowledge Discovery Efficiency or KEDE with values in the range between 0 and 1. KEDE is pronounced [ki:d].
KEDE is calculated using:
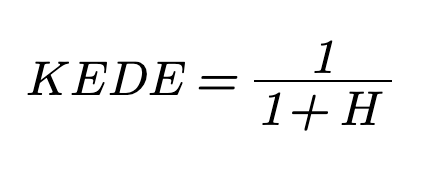
Where H is the average missing information as per the relationship of Shannon:
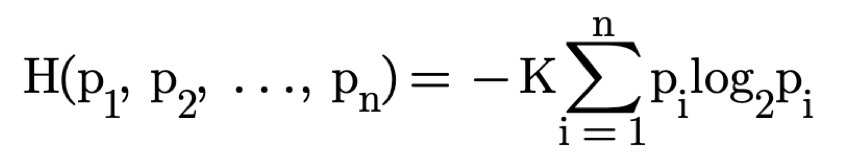
Below is an animated example of calculating KEDE when we search for a gold coin hidden in 1 of 64 boxes.
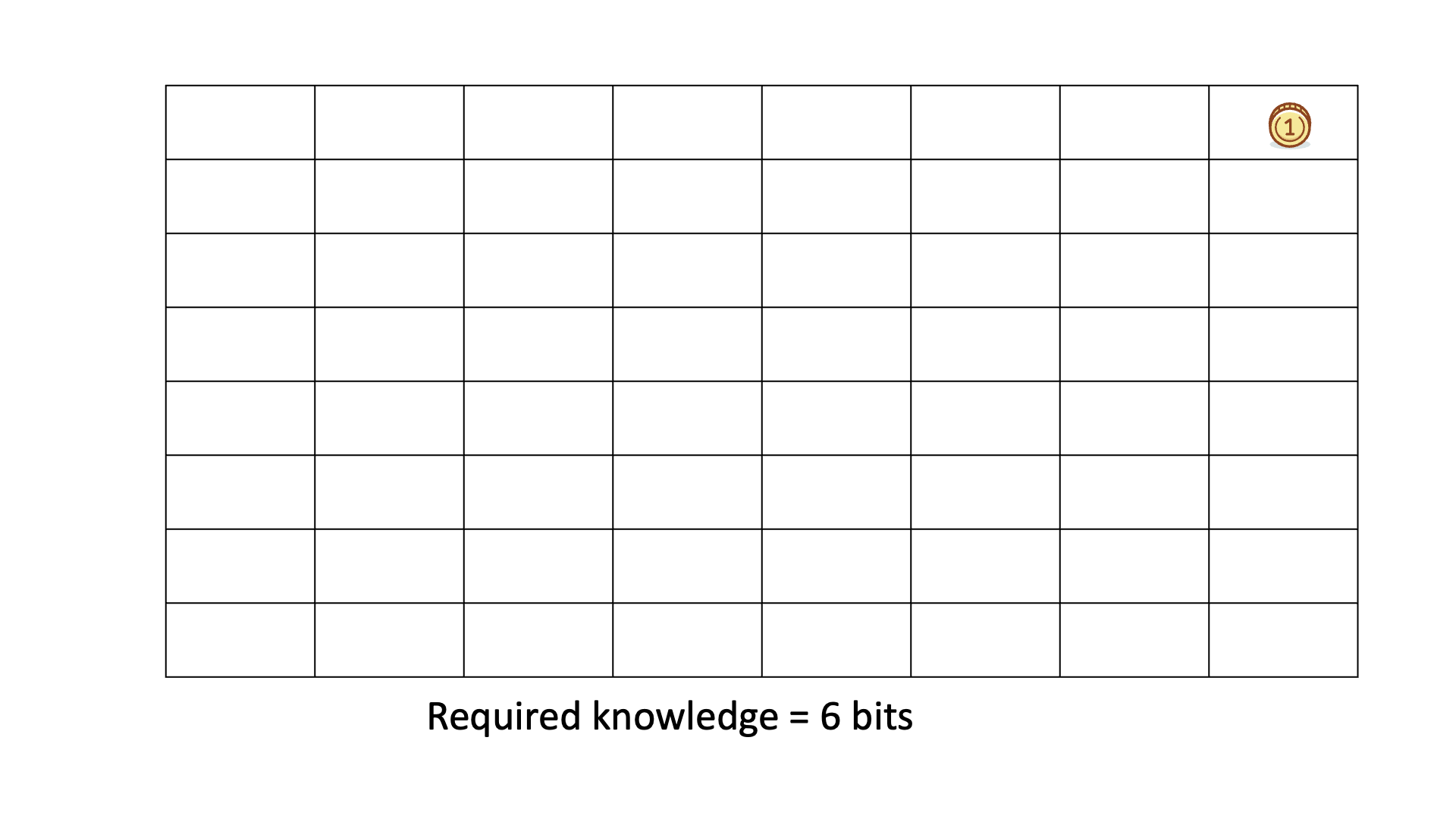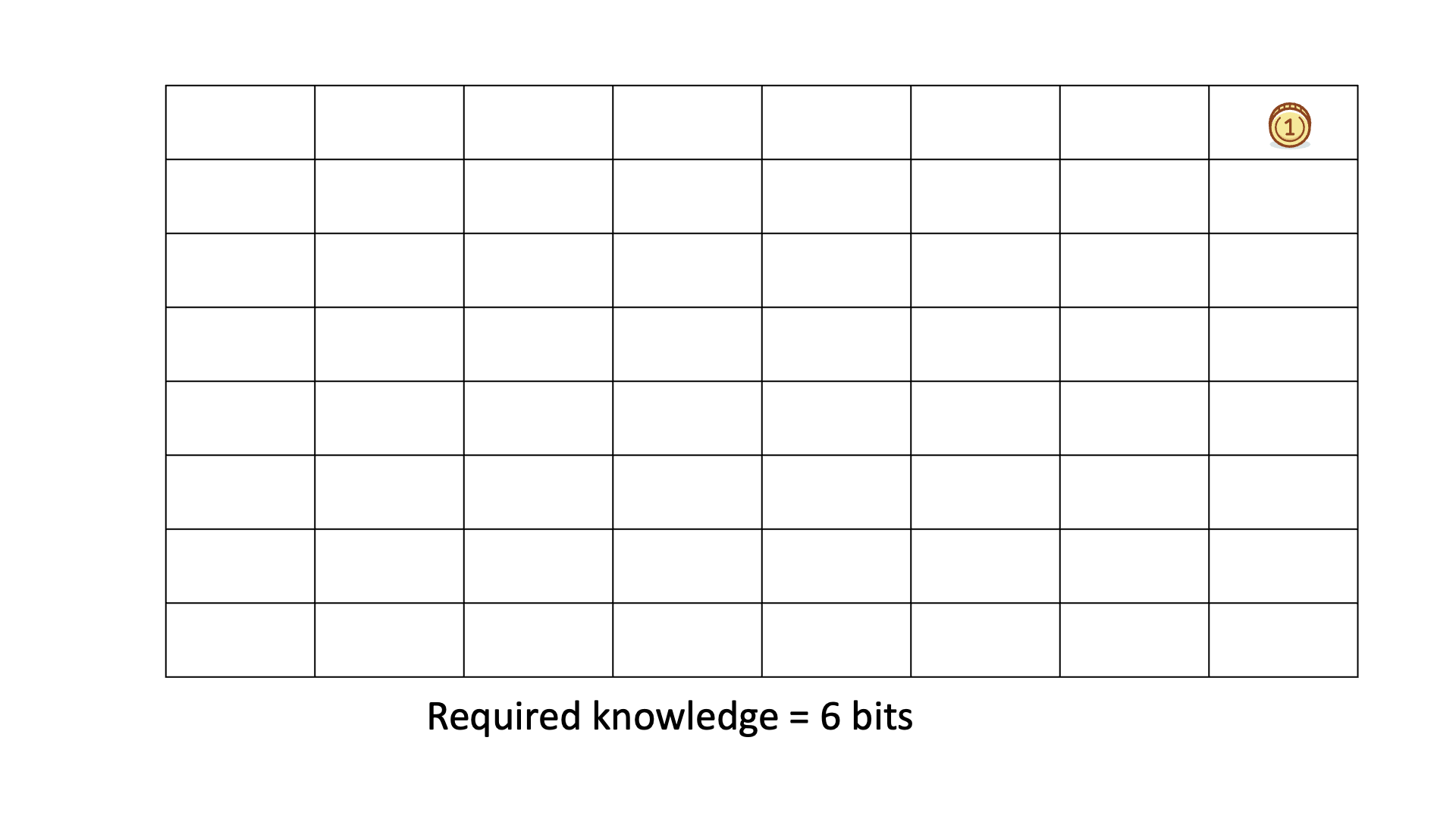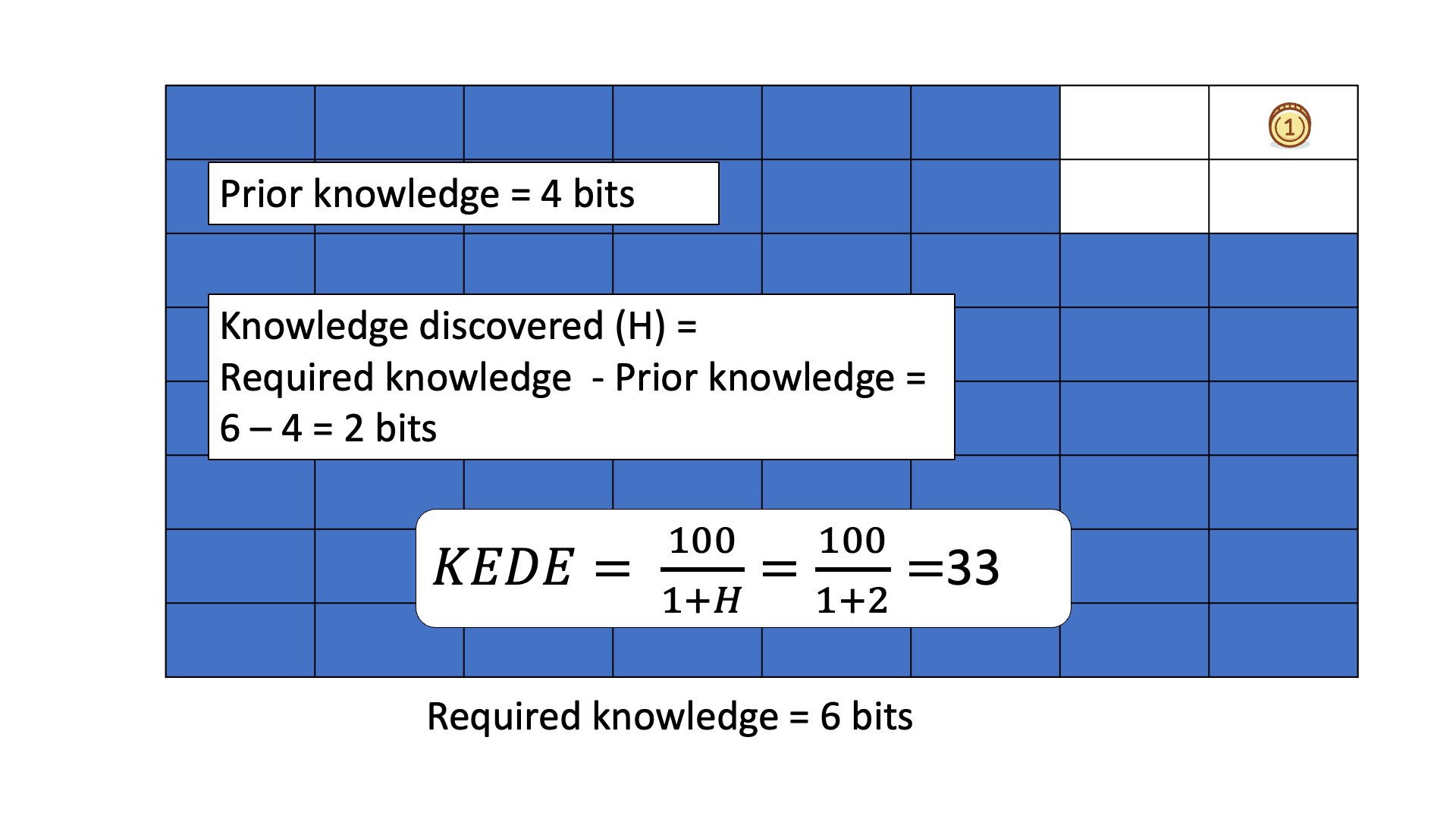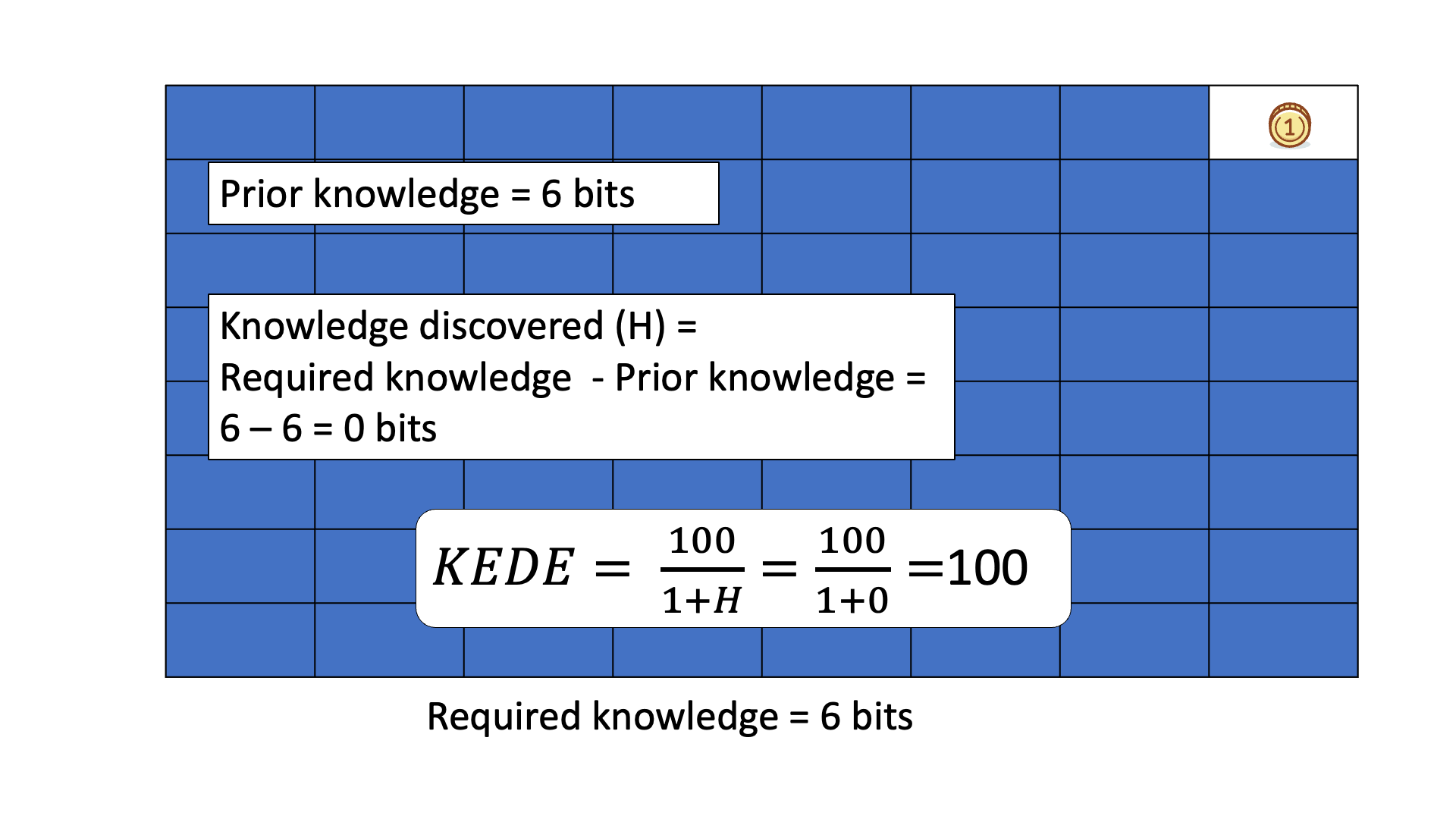
Prior knowledge is the easiest and the fastest to discover - it is in the human head, one just applies it. In other words, when prior knowledge is applied then there is the most efficient knowledge discovery. Conversely, when a lot of knowledge is missing then the knowledge discovery is less efficient. The more prior knowledge was applied i.e. the less knowledge was missing the more efficient a Knowledge Discovery Process is.
The math definition of KEDE is available here.
What is the maximum KEDE value?
The math underlying KEDE dictates that the minimum KEDE value is 0 and the maximum value is 100.
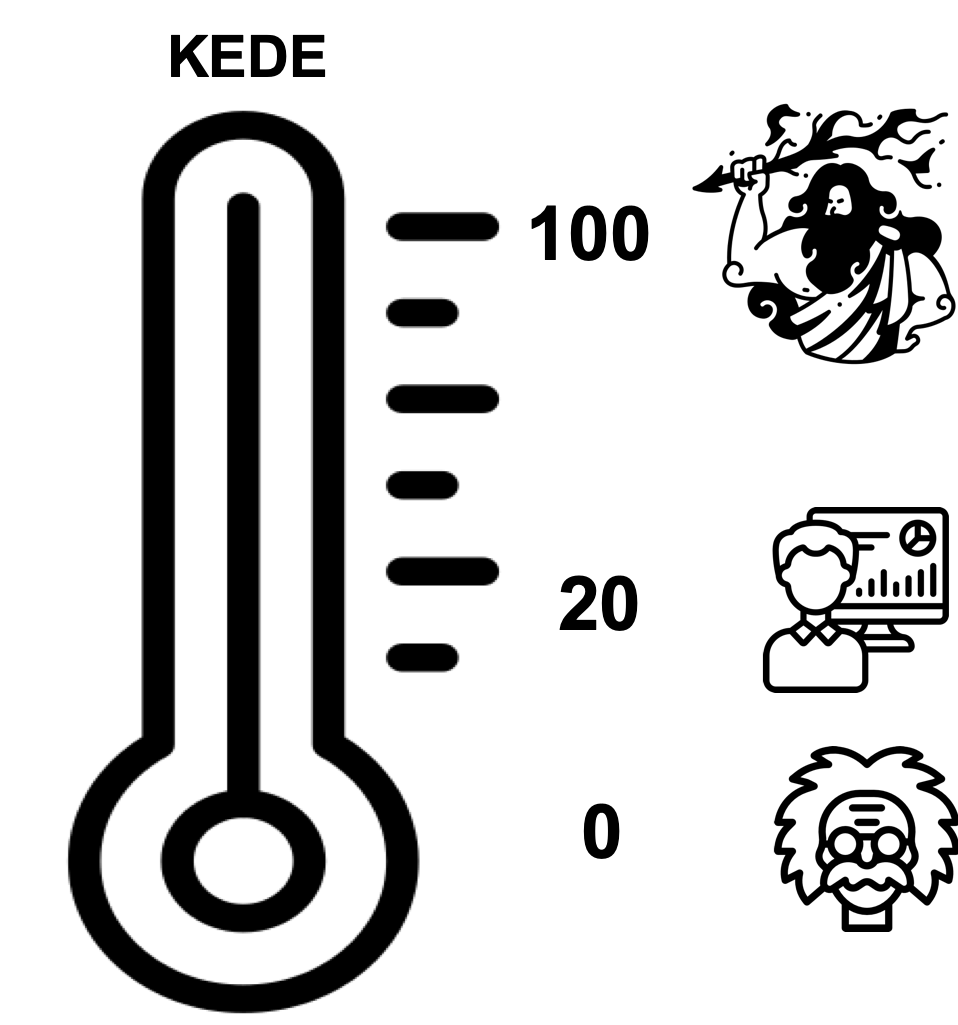
- Minimum value of 0 and maximum value of 100.
- KEDE approaches 0 when the missing information is infinite. That is the case of humans creating new knowledge. Examples are intellectuals such as Albert Einstein and startups developing new technologies such as Paypal.
- KEDE approaches 100 when the missing information is zero. That is the case of an omniscient being...like God!
- KEDE will be higher if you don't spend time discovering new knowledge, but just applying prior knowledge.
- KEDE is anchored to the natural constraints of maximum possible typing speed and the capacity of the cognitive control of the human brain, which allows for comparisons across contexts, programming languages and applications.
We would expect KEDE of 20 for an expert full-time software developer, who mostly applies prior knowledge, but also creates new knowledge when needed.
How is KEDE calculated?
In order to calculate KEDE for software developers we use the below theorem:
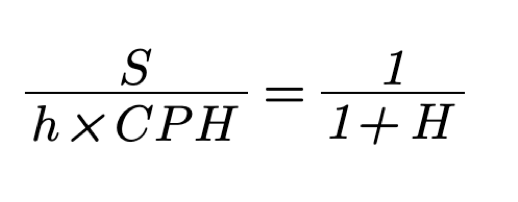
Where:
- S is the number of added symbols in a day;
- h is the number of working hours in a day;
- CPH is the maximum number of characters that could be contributed per hour;
-
H is the amount of missing information as per the relationship of Shannon:
The proof of the theorem is available here.
Using the above theorem KEDE values are calculated with the formula:
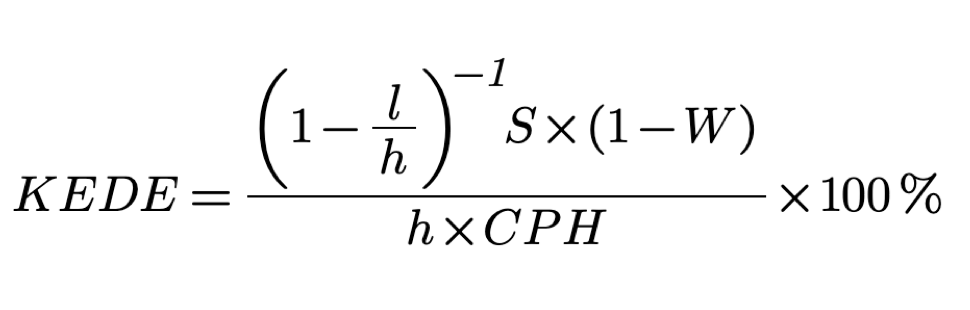
Where:
- S is the number of added symbols in a day;
- h is the number of working hours in a day;
- CPH is the maximum number of characters that could be contributed per hour;
- l are the hours wasted on non-productive activities;
- W stands for the waste probability.
The above formula means that individual KEDE is:
- Inversely proportional to the difference between the level of knowledge the individual has and the level of knowledge required to do a job;
- Inversely proportional to the amount of waste the individual removes while doing the job;
- Inversely proportional to the amount of time wasted on non-productive activities;
KEDE is measuring how fast people type! How could that be trusted?
Short Answer: While it may seem that KEDE is simply measuring typing speed, it's actually much more nuanced. KEDE infers the number of questions asked using the number of symbols of source code contributed according to this math theorem.
Long Answer: There is no way to get inside a human's head and count the questions asked while discovering knowledge. The process of discovering knowledge is a black box. We pragmatically adopt the positivist credo that science should be based on observable facts, and decide to infer the number of questions asked solely from the observable quantities we can measure. In reality the only thing we can measure is the tangible output. Hence we have to use the number of symbols of source code created to infer the number of questions asked.
Below is a short video that demonstrates how by counting the symbols of source code created we can estimate the number of questions asked.
This is how symbols of source code are used in calculating KEDE. The developer who created the most symbols of source code per unit time, had fewer questions about what to do and how to do it - thus was most efficient in discovering and applying knowledge.
An analogy:
Joe is a novice driver, who has just received his driving licence. Joe has a total of 20 hours experience driving a car. Next to him is Don, who had received his driving licence 25 years ago. It is not clear how many hours Don spent driving a car, but it is in the thousands. Let's imagine Joe and Don take part in a car race. The race track features short straights that climb sharply uphill for a short time, then suddenly drop downhill and very fast left and right turns. In short - it is a challenging track. Drivers need to make only one lap - from Start to Finish. They are given the same car model to drive on the same racetrack - hence, they are on an equal footing. We are watching the race, but we are not aware which is Joe's car and which is Don's car. It is like a black box to us. Our goal is to tell which car is Joe's and which car is Don's. How can we tell? Well, if the track is the same and the cars are the same, then the best driver will finish first. Finishing first means less time to get from Start to Finish i.e. more meters per unit time.Why would the best driver finish first? The best driver is more capable because he knows when to use the clutch, what gear to use in order to climb or to go downhill. In short he is more capable of driving fast because he is knowledgeable.
This is how symbols of source code createdd are used in calculating KEDE. The developer who created the most symbols of source code per unit time was most knowledgeable.
Some may say - but the race track is never the same in software development! That is not correct - the race track is the keyboard and it is always the same. Some others may say - but what if the driver is faster, but finishes in the wrong place? The Finish is set not by KEDE, but by customers, Product Owners and QAs. As explained here KEDE doesn't replace all useful metrics you use for looking into your organization as a white box.
Another analogy:
Let's imagine in front of us are two people who assemble a different model of IKEA furniture. We are told their names are Joe and Don. We are also informed that Don is a professional furniture assembler and Joe is a real novice assembling his first furniture. Our task is to tell who is Joe and who is Don just by looking at them assembling furniture.Many of us have the frustrating experience of assembling a Billy. You know how the furniture arrived at your house, all neatly packed in a box? Yeah, that doesn't last long. Within minutes of opening the box, the contents seem to have multiplied. Suddenly, there's not enough space to stack all the pieces, and you're struggling to keep all those screws and fasteners in a neat, little pile. You pick up the instructions printed without words, using only simple illustrations, and suddenly the lack of text makes you feel extremely perplexed.
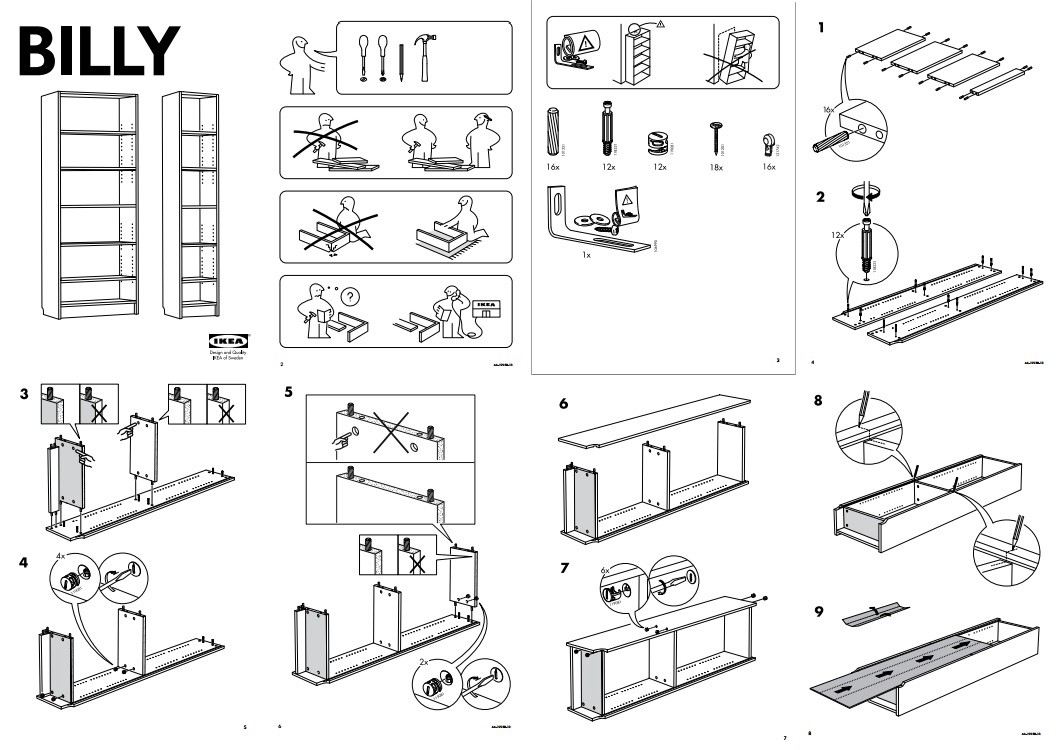
The first few steps are done and nothing can stop you. Except the next step you are doing it totally right but it's not fitting together. So you read, and then you re-read, and then you pick up the screws and try again. It's still not working. Then it's working! Nope, still not working. You hang up and look around. Your room is in shambles and random screws are rolling everywhere. Finally, the pieces screw in. It's coming together. And then you realize, on the very last step, that you're one screw short. For 10 minutes, you're on your hands and knees, going through the garbage, trying to locate the missing screw. And then you spot it. The last screw. Your key to freedom. You're sore and tired and your brain hurts, but you're done. You expected to have all your questions answered by the manual. And yet, you spent time asking yourself many more additional questions.
Having our past experience in mind while looking at the two men we can easily tell who is finding the manual informative enough, and who is asking himself many more additional questions. The former should be Done, because his training has provided him with all the knowledge needed to assemble furniture. The latter should be Joe, because he's spending a lot of time sitting on the floor with an allen wrench in one hand and the manual in the other.
Can we tell Joe or Don without looking at them while the men worked? Yes, because asking questions takes time. Prior knowledge takes less time to discover because it is in our heads. Hence, per unit time the professional should fix more screws, barrel bolts, and dowels(tacks) than a novice. Thus, by just counting at the screws two men fixed per unit time we can tell who's more efficient in discovering and applying their knowledge about assembling furniture.
Why should we trust KEDE? Is there any proof that it works?
KEDE is based on well-established principles from Information Theory and cognitive psychology. It's a patented technology that has been tested and validated in various settings. We also provide case studies demonstrating how it has successfully measured software development practices in different organizations.
Our developers are concerned about privacy and surveillance. Does KEDEHub intrude on their work?
KEDE respects developer privacy. It measures knowledge discovery at a high level, without tracking individual actions or keystrokes. The goal is to understand knowledge flow and growth, not to monitor individual activities.
We already have agile processes and project management tools in place. How does KEDE add value?
KEDE doesn't conflict with Agile, Kanban, or any traditional management methodologies. KEDE can be seen as a complement rather than a replacement to your existing practices. While agile processes and project management tools are good for managing tasks, KEDE specifically quantifies knowledge discovery, something not explicitly captured by these methods. Understanding how knowledge flows and grows within your teams can help optimize productivity and enhance developer happiness.
What is waste?
In software development, 'waste' often refers to unneeded features. However, from a knowledge-centric viewpoint—where just as a car operates on fuel, software development operates on knowledge—'waste' takes on a new meaning. We can define 'waste' where a piece of existing knowledge (akin to laying bricks) is replaced with new information. Waste is primarily due to rework. There are two types of rework:
- Changes to 'What' should be built, like altering or removing features, which alters code and user-facing functionality.
- Changes to 'How' to build the 'What,' or refactoring, which alters code without affecting user-facing functionality.
Such rework is distinct from design iterations performed for rapid learning, where the design decisions are understood to be experimental and subject to change. It is also distinct from establishing rapid project cycles to accelerate customer feedback. However, rework may occur within a design iteration or rapid project cycle if a poor decision would otherwise result in the iteration or project cycle failing to achieve its goals.
So, reducing waste essentially means minimising the work needed to gain the knowledge required for software production. In other words, "minimizing waste" equals "maximizing the work not done."
What is Capability?
In the context of Quality Control, process capability is defined as a statistical measure of the inherent process variability of a given characteristic. A "characteristic" refers to any measurable feature of a product or process. The aim is to ensure that the process is capable enough to keep the variations of these characteristics within acceptable limits, thereby assuring the quality of the output.
For quality control purposes in manufacturing or similar processes, characteristics are typically physical or performance measures that can be precisely measured and statistically analyzed. In knowledge work, however, we adapt this concept to more abstract aspects. We use "Knowledge Discovery Efficiency" (KEDE), which quantifies the balance between individual capability and work complexity.
Thanks to KEDEHub, a specialized platform for assessing software development processes, we have a reliable and repeatable method to quantify KEDE. This approach enables organizations to apply statistical tools to assess how well their processes balance the capabilities of individuals and teams in relation to work complexity.
Is KEDE applicable to product development companies?
Context: We are not the typical outsourcing software development company that primarily writes code. Over time, we've nurtured robust partnerships that place us on par with product companies. Consequently, our process embraces a holistic product creation approach, leveraging experts from design, architecture, coding, QA, to maintenance and support.
Short Answer: Yes, KEDE is applicable to product development organizations.
Long Answer: Even if organizations primarily sell software products, they remain, at their core, software development entities. Roles like designers, architects, and QAs might not directly code, but they play a pivotal role in aiding developers to craft software that aligns with customer needs. It's crucial to understand that the source code is like the footsteps left on a trail – it's a visible trace of the journey, but not the journey itself. The true journey is the process of knowledge discovery, a tapestry of collective insights and expertise that culminates in the production of that code. It's a misconception to solely attribute Knowledge Discovery Efficiency (KEDE) to the knowledge of individual developers. Much of it is determined by the system they operate in. Knowledge is an amalgamation, encompassing the developer's insights and that of their peers, the Product Owner, architect, QA, support, available documentation, and even external resources like StackOverflow.
Can KEDE replace all different metrics we use at present? Is it a one-size-fits-all solution?
Good question. KEDE is a unique and powerful metric, but it's not intended to replace all other metrics. It's more like a thermometer for your organization.
Consider this analogy: When a person has a fever, a thermometer is used to gauge the body temperature. If the temperature is above the normal range, a physician will need to investigate further. They might conduct additional tests, collecting more detailed metrics to locate the source of the inflammation and diagnose the cause.
Similarly, KEDE measures the overall health of your organization, treating it as a black box. The thermometer can provide a reading of your organization's "temperature," but not diagnose the reason for a fever, so to speak. To understand the cause, organizations need a physician - someone who can delve inside the black box, like a manager or coach. Therefore, just like a physician is crucial for diagnosis and treatment, agile coaches and engineering managers are key for interpreting the readings and implementing beneficial changes.
So, while KEDE is an invaluable tool for understanding the overall efficiency of knowledge discovery in your organization, it doesn't replace the need for other metrics. And it certainly doesn't replace the need for management approaches like Lean, Agile, and Kanban. KEDEHub provides the thermometer, but you still need to be the physician for your organization.
Is KEDEHub designed to lay off engineers?
Absolutely not. KEDEHub goes beyond simply gauging developer productivity through metrics like features delivered or lines of code committed. Instead, it zeroes in on the developer experience, measuring it through Knowledge-Centric metrics like Collaboration, Cognitive Load, and even the joy developers find in their work, particularly when they're deeply engrossed, or "in the zone". The objective? Speed up knowledge acquisition and application in the entire software development process not only the individual developers .
In the realm of software development, knowledge isn't an isolated entity possessed by coders alone. It's a shared treasure, with Designers, architects, and QAs - even if they aren't directly coding - contributing their unique insights into the melting pot. We often get ensnared by the idea that Knowledge Discovery Efficiency (KEDE) is the fruit of individual brilliance, sidelining the vast systemic environment that nurtures it. Inefficiencies within a company point to managerial shortcomings, not the engineers. It's up to management to foster an environment where engineers can thrive, collaborate, and access the resources they need.
KEDEHub provides valuable guidance on refining organizational structures and practices from a knowledge-centric perspective, ensuring organization's capabilities are maximized and productivity is enhanced.
What is the value of knowing KEDE?
Knowing your KEDE score offers valuable insights into human capital of your organization, and it can help you gauge the happiness, productivity of and collaboration levels among your knowledge workers.
Here are a few practical ways you can utilize KEDE to gain a competitive edge:
- Comparative Analysis: KEDE enables you to compare your company's capabilities with industry averages, and even among different functional areas within your company.
- Impact Analysis: KEDE helps in evaluating the effectiveness of significant changes within your organization. Wondering whether the latest reorganization increased your company's capability? Or if the new recruits have actually boosted the capability of your team? KEDE can give you objective answers.
- Transformation Analysis: If your team has recently undergone an Agile transformation, KEDE can help you measure if the transformation has actually increased your team's capability.
In essence, KEDEHub provides you with clear guidance on what needs to be changed in a knowledge worker organization in order to elevate and exploit its capability, and consequently improve productivity.
If our developers understand we measure KEDE will they leave us for another company?
Firstly, there's no need to tell developers you measure the KEDE of the organization. Knowledge discovery efficiency of individual developers is determined by the system they operate in. Knowledge is a property of the system the software developer operates in. If a company is not efficient, it's not the engineers' fault. It's their managers'. The managerial job is to create a system where the engineers can flourish, a system where expertise, solutions to problems and ideas are shared. The system must provide them with training, with enough information on a timely basis, with everything they need.
Secondly, only a few companies are mature enough to measure their capability objectively. Yours is such a company if it provides a safe environment and has the courage to see the information that KEDE Hub will reveal. That's not a small thing!
How can companies get ahead of the software engineer talent shortage?
By becoming more efficient in the utilisation of their existing talent.
How could KEDEHub improve the productivity of my company?
While KEDEHub isn't an instant solution, it offers valuable metrics to gauge developer experience, aiding in productivity enhancement. Essentially, it sets a foundation or starting point for your improvement strategies.
The principle “What gets measured gets managed” is often credited to Peter Drucker. Yet, V. F. Ridgway, in his 1956 paper, warned against over-reliance on measurements. Despite this, we're confident that by assessing developer experience through metrics—like cognitive load, happiness, collaboration, and information loss rate—organizations can proactively refine it.
But remember, KEDE isn't a physician—it can't diagnose specific problems or prescribe treatments. That's your role. What KEDE can do is provide you with a reliable, quantifiable measurement of your organization's knowledge discovery efficiency. It's up to you to take that information and use it to drive meaningful change.
Can KEDEHub be used on open source projects?
Context: We are not the typical software development company. An open source project is more like a community. People come and work for free with the idea to make the world a better place. It feels immoral to measure their capability and ask them to do better.
Short Answer: It is not immoral to use KEDE on open source projects.
Long Answer: KEDEHub allows you to group developers into teams. Hence, if your open source project has core contributors who are paid to work on it full time you can arrange them into one or more teams. All other contributors who work voluntarily and not on a regular basis you can group into a separate team and name it say "Volunteers". Then you can analyze all the other teams and never the "Volunteers".
Why is KEDEHub technology patent protected?
Context: Nowadays most of the technologies that want to be widely adopted and have impact on society are made publicly available and open source.
First of all, the math underneath KEDEhub is not patent protected. It is publicly available here and will be published in a peer-reviewed math journal. Secondly, the technology is patented in order to protect the investment in KEDEHub. The patent is available here and it describes at length how to build a machine like the calculation engine of KEDEHub. That means everybody can see how KEDEHub works.
Does identical KEDE scores for two developers indicate they possess the same knowledge level?
Context: Imagine a situation where a junior developer and a senior expert have comparable KEDE scores after being evaluated by KEDEHub. It would seem counterintuitive, right? Wouldn't we expect the senior expert to score higher?
Short Answer: Matching KEDE scores do not suggest equal knowledge levels. Instead, it suggests that both developers are applying or utilizing their respective levels of knowledge to a similar extent.
Long Answer: Expertise" signifies the depth or breadth of an individual's skills and knowledge — their potential. On the other hand, KEDE assesses the knowledge gap between what is required for a task and the knowledge the developer currently possesses. In other words, it gauges how efficiently an individual's potential is being leveraged in real-world tasks. Thus, when two developers share a similar KEDE score, it doesn't mean they possess the same level of expertise. Rather, it indicates that they are applying their unique expertise to similar extents in their respective tasks.
It also suggests that the tasks they were assigned were appropriately matched to their individual expertise levels. Each developer was able to apply their knowledge effectively to the task at hand, despite the difference in their expertise depth.
Example: Imagine two students, Joe (3rd year) and Don (4th year), in an Electrical Engineering course. Each student receives a test tailored to their potential and expected level of knowledge. Joe's test is designed for 3rd-year content, and Don's for 4th-year expertise. Even though Don has an additional year of study, if both students apply their respective knowledge fully within a given timeframe, their efficiency in handling the challenges posed to them can be comparably high, even with the difference in their expertise levels.
Is it possible to compare KEDE across different programming languages?
Context: There's a distinction in programming languages: some are verbose (like Java) requiring many symbols, while others are more terse (like Python) needing fewer symbols.
Short Answer: Yes, KEDE can be compared across different programming languages. Its primary focus is not on the specific symbols of a language, but on the ratio of questions posed in relation to symbols typed. Essentially, a higher KEDE score is indicative of fewer questions per typed symbol.
Long Answer: Consider two hypothetical teams - Team J working with Java and Team P using Python. If both teams, in a day's work, deliver software of identical functionality, Java's inherent verbosity would lead to a code with 10,000 symbols, while Python's succinctness would lead to just 1,000 symbols. Evaluating their daily KEDE: Team J scores a 10, while Team P only a 1. This suggests that Team J achieved a tenfold efficiency in their knowledge discovery process compared to Team P. This doesn't imply Team P did less work. In this context, 'work' corresponds to the tangible deliverable, that is, the functional software.
Here's the critical insight: The fact that Team P, despite typing fewer symbols in the same time frame, reached the same functional outcome as Team J implies that Team P faced more knowledge gaps or questions during the development process. This is evident in their lower KEDE score, showing Team J's superior efficiency in knowledge discovery. In essence, Team J either had a better grasp on what needed development and how to approach it or they were better at bridging their knowledge gaps swiftly.
Pushing the envelope further: If Team P exhibited the same skills in knowledge discovery as Team J, coupled with Python's inherent advantage of requiring fewer symbols, they could have potentially rolled out more features or functionality in the same time frame. This scenario underscores that KEDE reflects the true state of a knowledge discovery process, spotlighting any dormant potential within teams. In this analogy, KEDE unveiled the latent potential that Team P could harness.
For a detailed explanation, please read this article.
Can KEDE values be compared between complex and simple problems?
Context: A frequent notion is that obtaining a high KEDE score might be tougher for intricate challenges, such as crafting software for aircraft avionics, than for seemingly straightforward tasks like website development.
Short Answer: Yes, KEDE values derived from complex issues can be contrasted with those from simpler ones.
Long Answer: Complexity often translates to a larger scope of knowledge. But to suggest that the knowledge needed for website development is inferior or different in nature to avionics software development is a misconception.
Each field or domain has its "Body of Knowledge" (BOK) - a comprehensive compilation of the principles, terminologies, and competencies requisite for proficiency. Understandably, some fields have expansive BOKs, demanding more inquiries to achieve mastery, and might attract higher market appreciation. However, market preference doesn't elevate one BOK over another in terms of qualitative value.
All knowledge is qualitatively the same from the perspective of KEDE. It doesn't discriminate between BOKs with vast scopes and those that are more confined. KEDE's primary focus is the tally of questions posed for each symbol of code written.
Example: Drawing a parallel, if Joe possesses an MSc in Electrical Engineering and Don holds one in Mechanical Engineering, Joe's proficiency in mechanical engineering isn't guaranteed. Yet, both MScs signal to potential recruiters that Joe and Don have achieved comparable mastery in their chosen fields. In a similar vein, KEDE gauges the efficiency of knowledge acquisition and application, remaining agnostic to the domain's intricacies.
Is it feasible to compare KEDE for a junior developer to that of a senior developer?
Context: Imagine a scenario where a junior developer surpasses a seasoned senior developer in KEDE scores. This prompts the question: Is the metric flawed? Shouldn't a seasoned professional naturally exhibit a higher KEDE due to more challenging undertakings?
Short Answer: Absolutely, it's valid to compare the KEDE of a junior developer with that of a senior counterpart.
Long Answer: As previously explained here, KEDE doesn't measure the level of knowledge but the application of knowledge. KEDE focuses on how knowledge is applied rather than the depth of one's expertise Hence, it's entirely plausible for a junior developer to outscore a senior in terms of KEDE. The core determinant of an individual's KEDE is the disparity between their existing knowledge and the expertise required by their assignments. If a senior's KEDE seems subpar, it might imply their task demanded the assimilation of novel knowledge. Conversely, a junior developer could achieve an elevated KEDE when the gap between their existing know-how and task requirements is narrow. Though on the surface this might appear inequitable to the senior developer, from an enterprise-wide lens, the emphasis should be on bolstering the collective productivity, as explained here.
Example: Picturing Joe as an adept senior developer and Don as a budding junior, let's delve deeper. If Don's tasks are neatly aligned with his foundational knowledge, he would naturally attain a robust KEDE score. On the other hand, Joe's extensive expertise may lead him to tackle intricate challenges that necessitate fresh learning, thereby reflecting a reduced KEDE. Though this distribution might seem prejudiced when fixated on individual milestones, from a holistic organizational standpoint, this configuration optimizes productivity by minimizing knowledge gaps and amplifying the average KEDE.
Can we compare KEDE of a developer crafting new code with that of a developer fixing defects?
Context: Visualize two developers – one shaping new features, churning out ample code, and another dedicated to defect resolution, necessitating intricate testing and typically culminating in minor tweaks. In such a setup, the latter's KEDE is seemingly dwarfed by the former's. Does this imply an inherent flaw in the KEDE measurement?
Short Answer: Yes, we can compare KEDE calculated for a developer, who develops new code, with KEDE calculated for a developer, who fixes defects. However, this comparison requires understanding the broader context, especially regarding 'wasted knowledge' and its impact on team-wide KEDE.
Long Answer: As previously explained here, individual KEDE depends not only on the difference between a developer's current knowledge level and the knowledge required for a task. A pivotal factor is also the amount of existing code they amend or remove. Given this, a support developer, often entwined in the intricate process of defect rectification and consequent code adjustments, may naturally register a lower KEDE when compared against a developer generating new code.
Herein lies the crux: the code tweaked or fixed by the support developer represents knowledge once deemed correct, yet subsequently identified as flawed, necessitating rectifications - what we term 'wasted knowledge'. This knowledge, once perceived as accurate, demanded rework once its inconsistencies surfaced. To correct these errors, the support developer embarked on a knowledge acquisition spree to effectively replace the now redundant or errant knowledge.
This might seem unfair to the support developer if we only consider individual knowledge discovery efficiency. However, The 'wasted knowledge' is indicative of an oversight by the collective - the team that was originally at the helm of the now-defective code. This consequential ripple in knowledge, thus, skews the overarching team KEDE. Thus, average KEDE accurately reflects the state of both the individual developer and the organization as a whole.
In light of these nuances, we fervently advocate for a paradigm shift: from an acute focus on individual KEDE scores to a broader, more holistic lens - zeroing in on organizational e.g. team-centric KEDE tracking. Such a vantage point not only mirrors the collective's prowess but also underscores the collaborative fabric of knowledge assimilation and application.
How can I use KEDEHub to improve productivity of my software development organization?
At a high level, software development productivity is a ratio between the outcome produced and the new knowledge discovered to produce that outcome. The outcome can be quantified in various ways, such as revenue or profit.

KEDEHub allows you to measure the amount of new knowledge discovered by your developers. This forms the denominator in the productivity formula.
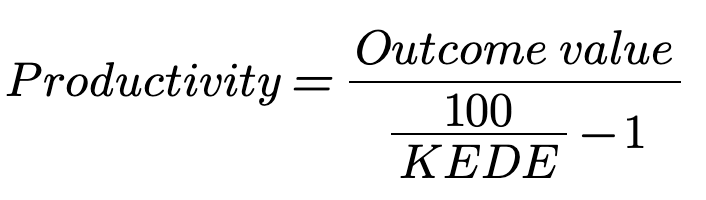
So, if the KEDE you measured is low, it means your developers needed a lot of new knowledge to produce the outcome. This might sound like bad news, but it's actually quite the opposite. It signifies that there's a lot of untapped human potential in your organization.
However, merely measuring missing information isn't enough to improve an organization's performance. You might be wondering how to reduce the missing information in an organization? This is where the analogy of a thermometer and a physician becomes relevant. KEDE functions much like a thermometer for an organization, observing it from the outside, akin to a black box. We disregard whether the black box is operated by senior or junior developers, nor do we question the quality of the software produced - we assume it meets appropriate standards.
KEDEHub can provide a reading of your organization's efficiency, but not diagnose the reason for a fever, so to speak. To understand the cause, organizations need a physician - someone who can delve inside the black box, like a manager or coach. Therefore, just like a physician is crucial for diagnosis and treatment, agile coaches and engineering managers are key for interpreting the readings and implementing beneficial changes.
Once you've identified these areas, KEDEHub can guide you on what needs to change in your organization to uncover and activate this untapped potential. As a result, you'll see an increase in your organization's efficiency, and consequently, its productivity.
We consider knowledge as the primary resource in software development. Thus, to improve productivity, you need to:
- Acquire enough of the primary resource, by recruiting people with knowledge, skills and experience.
- Ensure a match between the level of knowledge each individual possesses and the level of knowledge required to do a job. This would enable even junior developers to contribute on par with seasoned professionals. It's not about the years of experience, but about how efficiently individuals and teams can learn and apply new knowledge to maximize their potential.
- Establish an iterative process that aims to acquire new and missing knowledge through experiments and training.
- Minimize the amount of waste of the primary resource. There are two primary sources of waste - rework and time spent on non-productive activities.
For the organization as a whole, the goal is to minimize the average missing information.
For detailed steps on how to reduce the missing information for a software development project, you can read this article. It provides a wealth of information on ways to improve, from people, culture to engineering practices... what works and not. Here is another article presenting the general approach.
Does the length of the program affect KEDE?
Context: When developing embedded software developers need to optimize for the length of the source code. The less symbols of source code created the better. Some may say this shows KEDE is not applicable to embedded software because KEDE depends on the number of symbols of source code created. Less symbols of source code created will achieve lower KEDE even though it may be very time consuming to achieve that small code size.
Short Answer: A lot of knowledge is required to develop embedded software optimized for all needed system characteristics. If that knowledge needs to be discovered it is expected to have a lower KEDE. That is no different than the case of complex versus simple problems, as discussed here.
Long Answer: For a detailed explanation, please read this article.
How will auto-generated code affect KEDE calculation?
Context: Many IDEs offer class creation wizards which auto-generate not only methods, but also class files, abstract or implemented methods, place the package statement at the beginning of a class and correct imports. Coding tools like OpenAI's Codex, GitHub Copilot and CodeT5, which generate code using machine learning algorithms, have attracted increasing attention. An AI-powered tool takes natural language prompts as input (e.g., “Say hello world”) and generates code for the task it is given. When calculating KEDE we refer to the maximum possible typing speed for a human being. On the other hand, auto-generated code is created much faster than humans.
Short Answer: Auto-Generated code will only augment KEDE if developers channel the time saved into producing additional software.
Long Answer: The impact of digital control on manufacturing is palpable: it simplified the creation of precision components without heavily relying on expert craftsmen. Similarly, AI-assisted programming underscores a pivotal shift in software development. The crux isn't just writing the code, but understanding the core problem to be solved. AI has made this distinction more salient. Knowing the right question is half the battle, suggesting that seasoned professionals will find AI tools more of an aid than a replacement.
All tools that auto-generate code encapsulate knowledge that is readily available to be used and no need to be discovered. If we put on the "knowledge discovery" lens we will see that such AI tools help answer questions about "How" to develop what is needed. The questions about "What" to develop are left to the humans who will have to accurately describe what they need. Yes, humans will have to accurately describe not what they want, but what they need. That is something AI tools cannot do...yet. AI tools that would actually help people know what they need and to communicate it effectively would be a true miracle.
As a result, KEDE is poised to rise, since only the 'What'-related queries will remain unresolved. The rapid generation of code by AI tools far surpasses manual typing speeds, promising significant time savings. If utilized wisely, this saved time could translate to more lines of source code and a tangible increase in functional software output. However, it's worth noting that auto-generated code will only augment KEDE if developers channel the time saved into producing additional software. For a detailed explanation, please read this article.
Will KEDE nudge developers not to refactor?
Context: Some may say that KEDE implies the Refactoring technique should be considered wasteful. That KEDE would nudge developers not to refactor.
Short Answer: From a knowledge discovery perspective refactoring shows that the questions developers asked were not answered properly in the first place. Some more questioning had to take place and after new knowledge was discovered the software was changed accordingly. That is a clear waste, but does not mean it is bad to do refactoring.
The nature of software development requires software developers to constantly improve the knowledge content of the software produced. To do this, they often need to refactor. Therefore, refactoring is not inherently good or bad - it's simply a method that software developers employ to adapt to their ever-changing work environment. And no, KEDE does not say refactoring is bad. It just can quantify how inefficient a knowledge discovery process is. Here comes again the goal to learn as cheaply as possible. Hence refactoring can also be done more efficiently.
Long Answer: For a detailed explanation, please read this article.
How would KEDE reflect the usage of Design Patterns?
Context: Let's have a junior developer, who types very fast correct code that implements the required functionality However, the junior is not aware of design patterns and unknowingly works according to the Unix principle "When in doubt, use brute force". Then we have a senior developer, who knows design patterns and with less code can implement the same functionality. Thus the junior will be less productive than the senior who with less code will get the same effect. How would KEDE reflect that difference in productivity?
Short Answer: Usinage of Design Patterns will increase KEDE only if the developer used the saved time to produce more software.
Long Answer: Patterns explicitly capture expert knowledge and design tradeoffs and make this expertise widely available. There's no need to spend a precious resource (your time) coming up with a new solution for a problem when there are tried and tested methods already available. Thus, they can accelerate the development process, which helps save time. For this saved time there could be some more symbols of source code created and more tangible output i.e. working software produced. Design patterns will increase KEDE only if the developer used the saved time to produce more software.
Example: Let's have the task of printing on a computer screen 1,000 times the sentence "This is a test!". Our junior is so novice in programming that he knows how to print on the screen, but is unaware of what a Loop is and how to implement it in Java. The junior types a line of code that prints the required sentence on the screen, then copies it and then pastes it 999 times. That he ends up with a program of 1,000 lines of code or 16,00 symbols of source code created. Our senior knows both how to print on the screen and how to implement a loop. He types one line for the loop from 0 to 999 and inside the loop one line for printing the sentence on the screen. Thus, the senior ends up with a program of 2 lines of code or 30 symbols. Since as explained here individual KEDE is calculated using the symbols of source code created then at the end of the work day the junior will have much greater KEDE than the senior. And that is correct, because the senior saved time using his knowledge, but did not return it back to the company. If the seniors would have used the saved time to produce more code he might end up with the same KEDE as the junior. Same KEDE, but with a lot more implemented functionality!
As we pointed out here KEDE is not aimed to be the single metric in software development. Thus, even with the same KEDE the senior should be rewarded for producing more functionality than the junior. Actually that's why they call them senior and junior!
Can KEDE be calculated for IT operations teams?
Context: Operations engineers install, configure, operate and evolve common infrastructure such as the network, servers, and external services e.g. the Cloud.
Short Answer: KEDE can be used to measure the capability of IT operations teams if they use Infrastructure as Code (IaC).
Long Answer: Infrastructure as Code (IaC) is the managing and provisioning of infrastructure through code instead of through manual processes. With IaC, configuration files are created that contain infrastructure specifications, which makes it easier to edit and distribute configurations. Version control is an important part of IaC, and the configuration files should be under source control just like any other software source code file. That means KEDE can be used to measure the capability of IT operations teams if they use IaC.
Embracing IaC automates the infrastructure setup, enshrining knowledge and democratizing access to it. Gone are the days when engineers squandered hours on manual server setups, OS configurations, storage adjustments, or other foundational tasks each application iteration. IaC offers a swifter path to infrastructure readiness, conserving valuable time. However, this time-saving translates to an uptick in KEDE only if engineers channel the extra hours into further infrastructure provisioning.
When calculating KEDE do you take into account all of the text developers produce?
Short Answer: KEDEHub will analyze only source code and documentation for it.
Long Answer: The end product of software development is the output the customer pays for. Most of the time it is source code and documentation for it. As part of their work day software developers spend a lot of time answering emails, writing content in bug tracking tools like Jora, commenting on collaboration tools like Slack and Confluence, etc. All such artefacts are means for acquiring the missing information needed to produce the output. However the means might also be oral conversations that never leave a tangible trace like email messages. Customers are not interested in all the artefacts produced as a by-product.
Thus, KEDEHub will analyze only source code and documentation for it.
How does KEDE capture the inventive aspect of software development?
Short Answer: The more new knowledge developers discover, the more resulting KEDE would move towards zero. However, most of the times when developers lack knowledge they just need to consult existing technical guides.
Long Answer: To ensure clarity, it's crucial to differentiate between 'novelties' and 'innovations'. An 'innovation' refers to something introduced to the world for the first time; it's entirely new and unprecedented. On the other hand, a 'novelty' is something that, while new to an individual or a team, may not necessarily be new to the world.
SSoftware development is frequently viewed as an innovative endeavor. This perception stems from the vast array of solutions developers can choose from, spanning various domains, programming languages, platforms, and hardware configurations. This extensive selection is termed " perplexity - a concept referring to the vast array of alternatives available. KEDE offers a metric to gauge the complexity faced by developers during their work.
Yet, high perplexity doesn't always mean innovation. The difference between the requisite knowledge to complete a task and current level of global knowledge serves as a yardstick to assess the degree of creativity or novelty required for their work. Sometimes, when developers face a so-called "creative" challenge, they might just be encountering something new to them (novelty) rather than creating something new to the world (innovation). The solution? They might just need to familiarize themselves with existing solutions, be it through training, manuals, or tutorials.
KEDE's design mirrors how adeptly developers utilize existing knowledge in tackling challenges. When a challenge is groundbreaking, necessitating the birth of new insights, the KEDE reading moves closer to zero. This mirrors scenarios where pioneers, like Einstein, or novel initiatives, like Bitcoin, forged ahead with unmatched ideas.
It's worth noting, though, that developers shouldn't constantly grapple with high perplexity. Ideally, management should curtail this complexity by offering apt training and ensuring developers work on tasks aligning with their expertise. How to deliberately reduce the degree of perplexity is presented in Managed knowledge discovery
How does KEDE reflect the value my organization and I deliver?
Short Answer: KEDE gauges efficiency in delivering value, not the value itself.
Long Answer: Instead of quantifying direct outputs like customer satisfaction or financial gains,, KEDE is used for calculating Knowledge-centric metrics. These include Collaboration or Short Feedback loops, Cognitive Load, Happiness (Flow State) and Rework (Information Loss Rate). By focusing on KEDE, an uptick in its score translates to improved collaboration, reduced cognitive load, increased happiness, enhanced productivity, and decreased waste. Essentially, KEDE provides insight into an organization's operational capability, indicating how efficiently software developers discover and apply knowledge.
An analogy: Imagine having two separate vacations. For each journey, your car consumes an identical amount of fuel. The first trip, a mountain retreat, disappoints due to constant rain. The next month, the same car takes you to a sunlit beach, providing a sublime experience. Regardless of each vacation's quality, the capability and fuel efficiency of your car remain unchanged.
In the realm of software development, envision knowledge as the equivalent of fuel. Think of it this way: Cars run on fuel, while software development operates on knowledge. KEDE serves as the measure, assessing the capability and efficiency of your software processes. It's like the real-world performance of your car versus its advertised potential. With KEDE, the focus is on navigating the knowledge landscape efficiently, not on the inherent value of the destination.
We do innovative work - how could we achieve the highest possible engineering efficiency?
Context Our company is constantly inventing stuff which is patentable. Hence, by default our prior knowledge is always less than the maximum possible. Our KEDE will always be below industry average. That, however, is not fair!
Short Answer: There's no necessity to always compare yourselves to the industry average. You can compare with similar companies or track your own progress compared to previous quarters.
Long Answer: It's true that companies developing innovative, patentable technologies will likely have lower engineering efficiency and KEDE scores. However, not all code for cutting-edge technology is patent eligible. Most likely, much of it is something someone else has already created, and that someone is likely part of the same company. Therefore, if the patented knowledge is properly managed, shared, and applied within the company, the overall engineering efficiency should be stable and may even trend upward.
An analogy: Think of KEDE as a scale. While you might be interested in your absolute weight, the scale is most useful for tracking changes in your weight. If you gain weight, you take action to lose it. Use KEDE the same way - to manage your capability and strive for continuous improvement."
Should we measure the capability of individual developers or of teams?
Context Let's say we have two developers. One is a junior, doing routine, well known work. The other is a senior doing innovative work. The senior will always have a lower KEDE than the junior. And that means KEDE will force us to favour routine over innovative work.
Short Answer: It's not recommended to measure the capability of individual developers. Instead, you should always measure the capability of an organization, whether that be a team, a project, or a company.
Long Answer: It's a common misconception to overestimate how much of the knowledge discovery efficiency is a function of the individual developers' skills and abilities and underestimate how much is determined by the system they operate in. Knowledge is a property of the organization the software developer operates in. This includes the knowledge of the developer, but also the knowledge of their teammates, the Product Owner, the architect, the QA, the support, the documentation available, the applicable knowledge in StackOverflow, and so on.
While it's true that designers, architects, and QAs may not produce code, they contribute significantly to helping developers produce code that meets customer expectations. Therefore, it's not recommended to measure the capability of individual developers. Instead, you should always measure the capability of an organization, whether that be a team, a project, or a company.
So, in short, KEDE is not about favouring routine over innovative work. It's about measuring the efficiency of the knowledge discovery process within the organization as a whole.
How does KEDE account for developers' happiness?
Context KEDE seems to look at software developers as "coding machines'". That feels like KEDE excludes any considerations about job satisfaction and pursuit of happiness.
Short Answer: KEDE can be used to measure developer happiness. That is achieved by assuming happiness at work coincides with a developer being in a state of Flow
Long Answer: As explained here we can measure after the work was finished, the knowledge discovered to finish the work. The knowledge discovered is measured using Knowledge Discovery Efficiency (KEDE). Thus from KEDE we can evaluate whether a developer's abilities and work complexity were in balance.
How is KEDE related to the concept of "Value of information"?
Context It is argued that in the analysis of IT investments we emphasizes development costs. There are a lot of “software metrics” firms that focus on measuring development costs, to the exclusion of measuring value. They say we should take what we would have spent on software metrics and focus it on researching the system's benefits, how quickly people will start using the system, how much it will be used and what the risk of cancellation is. To make the best investment decisions, IT management must learn how to compute the value of information, and start modeling utilization and cancellation in cost-benefit arguments.
Short Answer:
KEDE has no relations whatsoever to the concept of "Value of information".
At the same time KEDE is used in the denominator of the software development productivity formula.
The value delivered by the IT investment is in the numerator of the formula.
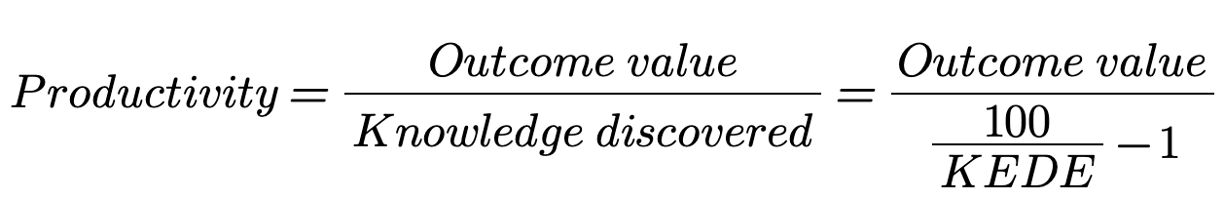
Long Answer: An Epistemic Action is any action aimed at acquiring knowledge from the world. Actions could be any act of active perception, monitoring, checking, testing, ascertaining, verifying, experimenting, exploring, enquiring, giving a look to, etc. Epistemic Actions are directed either to reduce perplexity (one or more of its dimensions) or to evaluate new information. Evaluating new information has been extensively investigated in economics. There it is referred to as "Value of information" in the sense of “how much an agent is disposed to pay for obtaining that information?”. In that approach a way to calculate the value of information is given with respect to utility functions. An example would be, how much you'd pay for the following information: “Each of the houses in this city costs one million dollars”.
Using KEDE we are interested only in epistemic actions directed to reduce perplexity below a given threshold before making a decision or taking action. How much would that cost is the topic covered by "Value of information".
How is KEDE related to the concept of "Lines of Code"?
Context KEDE feels like a fancy name for "Lines of Code" (LoC).
Short Answer: KEDE is not related to the concept of "Lines of Code" (LoC). LoC measures the volume of a software system as if printed on paper[1], while KEDE evaluates the amount of knowledge, quantified in bits of information, discovered during the development process.
Long Answer: The main similarity between KEDE and LoC lies in the act of counting specific attributes of source code. LoC counts lines, whereas KEDE counts symbols in the code.
For instance, LoC takes a string of symbols and divides it into logical groups. Take the string "for each x in list_of_x: x=x+1 print('x=',x)". It can be divided into three logical groups: "for each x in list_of_x:", "x=x+1", and "print('x=',x)". LoC suggests that the number of these groups carries specific significance when measuring developer productivity.
Contrastingly, KEDE approach would take the same string "for each x in list_of_x: x=x+1 print('x=',x)" in its entirety and count the total number of symbols, including spaces. From this count, using the KEDE theorem, we can determine how many bits of information the developer had to acquire to produce this string.
Despite this basic similarity, KEDE and LoC are significantly different in their methodology and what they measure. Let's examine a comparison:
| Lines of Code | KEDE |
|---|---|
|
LoC measures the "size" of a system by counting how many source lines were created. |
KEDE infers the knowledge discovered by counting how many symbols of source code were created, considering the maximum possible typing speed and considering the capacity of the cognitive control of the human brain. |
|
LoC doesn't consider the complexity of the problem solved with the code, |
KEDE aptures the complexity by measuring the knowledge required to solve a problem as expressed in the code. Complex tasks that require a large amount of knowledge to solve will have a lower KEDE. |
|
LoC doesn't support comparisons across contexts, programming languages, and applications. LoC is dependent on the verbosity of the programming language, with verbose languages having more lines of code for the same functionality. |
KEDE supports comparisons across contexts, programming languages and applications. KEDE is language-agnostic. It does not consider the verbosity of a programming language but focuses on the quantity of knowledge discovered. |
|
LLoC doesn't reflect the efficiency of a developer. A developer who writes concise code may have fewer lines of code than one who writes verbose code, yet they may both solve the same problem. |
KEDE however, measures how efficiently a developer discovers and applies knowledge, thus reflecting their productivity. |
|
LoC can be a useful predictor of software quality (metric of defects per KLOC)[2]. |
KEDE allows for quantifying human capital of an organization, happiness and productivity of and collaboration between knowledge workers. |
1. P. G. Armour, Beware of counting LOC, Commun. ACM, 47, 3, 21–24, (Mar. 2004), doi: 10.1145/971617.971635
2. H. Zhang, "An investigation of the relationships between lines of code and defects," 2009 IEEE International Conference on Software Maintenance, Edmonton, AB, Canada, 2009, pp. 274-283, doi: 10.1109/ICSM.2009.5306304.
It looks like KEDE favours developers writing more code instead of smart code?
Context KEDEHub is nothing more than a way for developers to pump out more low-quality code faster, rather than putting in the effort to write smart, effective solutions. Just look at this simple case:
- A junior programmer is given a problem. They immediately begin coding and code for 1 hour straight, never stopping.
- A senior programmer is given the same problem, they think for 59 minutes then code for 1 minute. Solves the same problem.
Short Answer: KEDE doesn't favor developers who write more code over those who write smart code. More detailed explanation can be found here along with a numerical example.
Long Answer:
KEDE does not measure software development productivity,
which is a ratio between
the outcome produced and
the new knowledge discovered in order to produce the said outcome.
The outcome in the numerator can be revenue, profit etc.
The value of the output in the numerator can be quantified in monetary terms like revenue or profit, while the knowledge discovered in the denominator can be quantified using KEDE. Since KEDE is in the closed interval [0,100], the higher the KEDE, the higher the productivity, assuming the output remains constant.
It's important to note that a developer or team with a higher KEDE score doesn't necessarily mean that their code is better, or that their productivity is higher. Even if a developer has a high KEDE but low output value, their productivity will still be low.
More detailed information on how to measure productivity in software development can be found here along with a numerical example.
Does higher efficiency in developers correlate with lower levels of happiness?
Short Answer: Indeed, KEDE's measurements suggest a somewhat counterintuitive relationship between efficiency and happiness in developers. The most efficient developers, those who require less discovery of new knowledge, may also be the most bored.
Long Answer: Generally, KEDE values less than 50 reflect an imbalance leaning towards anxiety, while values greater than 50 suggest an imbalance leaning towards boredom. In both cases, the balance is less optimal than when KEDE equals 50. This suggests that even as companies seek to optimize the efficiency of their existing talent in response to the software engineer talent shortage, they must also attend to the job satisfaction and intellectual stimulation of their developers to maintain a balanced, happy workforce.
We are not sure if our team will understand or embrace KEDE. How can we ensure they see its value?
As part of the KEDEHub onboarding, we offer training and support to ensure your team understands the KEDE metric, its importance, and how to interpret it. Further, illustrating how KEDE can help improve productivity and workplace satisfaction could be key in gaining their acceptance.
We are concerned about the cost of implementing KEDEHub. Is it worth the investment?
KEDEHub, while involving an initial investment, is intended to drive long-term productivity and efficiency gains. By optimizing knowledge discovery, your teams could work smarter, reducing rework and accelerating development timelines. The potential cost savings and improved outputs can make KEDEHub a valuable investment.
We have tried similar metrics before without success. How is KEDE different?
KEDE stands out because it focuses on quantifying knowledge discovery, a critical but often overlooked aspect of software development. By measuring and optimizing this specific dimension, KEDE can offer unique insights to improve your team's productivity and collaboration.
Our projects vary significantly in complexity. Will KEDE still provide accurate insights?
KEDE can accommodate the complexity inherent in software development. By focusing on knowledge discovery, it offers valuable insights regardless of the scope or complexity of your projects.
Our organization is too small to benefit from KEDE. Isn't it better suited for large companies?
While KEDE can indeed provide valuable insights for large organizations, its core principles are equally applicable to small teams. In fact, smaller organizations may find it easier to implement and can enjoy more immediate benefits.
We have a unique development process. How can we be sure KEDE will fit into our workflow?
KEDE is a flexible metric that can be integrated into diverse development processes. It is not prescriptive, and it doesn't conflict with Agile, Kanban, or other traditional methodologies. Instead, it supplements these methodologies by providing additional insights into knowledge discovery.
Our team is dispersed globally and works in different time zones. Can KEDE handle such variations?
Yes, KEDE can handle variations in team dynamics, including geographical dispersion and different time zones. Its focus is on knowledge discovery, which remains a fundamental aspect of software development regardless of the team's location.
KEDE seems theoretical. Can it provide practical, actionable insights?
Absolutely. KEDE may be grounded in theoretical principles, but its ultimate goal is to provide practical insights for improving software development. The insights derived from KEDE can help you enhance collaboration, reduce cognitive load, improve productivity, and ultimately build better software
We already use performance metrics like velocity, burn down charts, etc. Why should we add another metric like KEDE?
While traditional metrics provide useful insights into productivity, KEDE offers a unique perspective by focusing on knowledge discovery. It complements existing metrics by shedding light on collaboration and cognitive load, factors that significantly impact developer productivity and happiness.
Our software development process is unique. How can a generalized metric like KEDE be applicable to us?
KEDE is a metric that applies to various software development processes. Its emphasis on knowledge discovery as a measure of efficiency applies universally, regardless of the specific methodologies or techniques employed.
How can working in an ensemble affect a developer's happiness and cognitive load?
Context With approaches such as pairing and ensemble, the 'author' field in version control systems becomes largely irrelevant, as it doesn't fully represent an individual's knowledge or workload.
For instance, when working in pairs, the committer is simply the person whose machine was used, even though both parties contributed to the code and tests. In an ensemble, up to 8 people could be collaborating on a single machine. In this scenario, each commit is the collective work of several contributors, but is made from an arbitrarily chosen machine. When collaborating online, we alternate drivers, meaning different individuals' machines reflect the collective work of the same group of people.
Thanks to Tim Ottinger for posing the question. Here is the response:
Short Answer: Knowledge is a property of the system within which a software developer operates. Therefore, we recommend measuring KEDE only at the system level, i.e., team, project, or company.
Long Answer: Knowledge should be viewed as an attribute of the system within which a software developer functions. For example, a non-Scrum team may include an architect and a QA who don't make any commits, but they still contribute their knowledge. Similarly, clients provide crucial information about the development needs and are part of the system the developer operates within. Therefore, we recommend measuring KEDE only at the system level, i.e., team, project, or company. However, factors such as happiness and cognitive load are assessed at the individual level. If a developer is working in an ensemble that fails to provide necessary knowledge, they may experience anxiety. Conversely, if the ensemble provides the required knowledge, the developer may experience a state of flow, or happiness. In these situations, the ensemble's collective work is reflected in the source code.
Can developer experience (DevEx) be measured by observing team delivery trends like cycle times and defect rates?
Short Answer: While Flow Metrics offer vital insights they don't cover the intangible aspects of software development. In contrast, Knowledge-Centric Metrics shed light on the intangible facets. They address the knowledge gap that a software developer needs to bridge to successfully complete a task. We believe that when combined with Flow Metrics, our Knowledge-Centric Metrics provide a comprehensive, holistic view of the software development process, thereby augmenting and enhancing the insights provided by Flow Metrics.
Long Answer: Software development analytics is a rapidly growing field, with the power to change how software engineering processes are managed and executed. At the core of these analytics is that measurement framework: Flow Metrics.
Flow Metrics focus on quantifying tangible logistics such as Flow Velocity, Flow Time, Flow Efficiency, Flow Load, and Rework assessment, providing insights into the efficiency and productivity of the software development process as a manufacturing system.
However, there are inherent limitations. While Flow Metrics offer vital insights they don't cover the intangible aspects of software development. Take, for instance, the developer experience at work. In today's software industry, companies invest heavily in nurturing developers' happiness. They believe that amenities like perks, playground rooms, free breakfast, and sports facilities, among others, would yield a return on investment in the form of improved productivity and retention. Such investments operate under the assumption that happy developers equate to productive developers.
Yet, using Flow Metrics alone, it's challenging to discern if developers, teams, and projects are truly operating at their peak. There's an inability to definitively ascertain whether developers enjoy their work, derive happiness from optimal work experiences, and ultimately realize their potential.
Furthermore, Flow Metrics often leave executive leaders struggling to connect the developer experience to the economic productivity of the business. Moreover, even the most accomplished managers often find it challenging to objectively validate their management practices for continued growth and success, given the lack of comprehensive data points.
In contrast, Knowledge-Centric Metrics shed light on the intangible facets. They address the knowledge gap that a software developer needs to bridge to successfully complete a task. Derived from the foundational Knowledge Discovery Efficiency (KEDE) metric, indicators such as Collaboration, Cognitive Load, Happiness (Flow State), Productivity(Value per Bit of information Discovered), and Rework (Information Loss Rate) present a multidimensional view of a developer's experience and the overall efficiency of the software development process.
While Flow Metrics provide an important perspective, KEDEHub specializes solely in Knowledge-Centric Metrics. Our focus is on capturing the intangible elements of the software development process, specifically the knowledge discovery aspects. We believe that when combined with Flow Metrics, our Knowledge-Centric Metrics provide a comprehensive, holistic view of the software development process, thereby augmenting and enhancing the insights provided by Flow Metrics.
The beauty of this approach is that Knowledge-Centric and Flow Metrics don't collide; they complement each other. They each offer a unique standpoint, and together, they provide a fuller picture of the software development process. This is why we don't consider vendors of Flow Metrics tools as our competitors. We are all working towards the same goal: to improve the work experience and productivity of software developers. At KEDEHub, we're simply providing a different, yet equally valuable, perspective.
More on the topic can be found here.
Getting started


