How to Measure Rework in Software Development
A knowledge-centric approach
Takeaways
- Rework as Waste: In the context of software development, rework, defined as the replacement of existing knowledge with new information, can be seen as a form of waste, especially when it's due to avoidable mistakes or poor knowledge-acquisition practices.
- Lost Information: 'Lost information' is a key concept for measuring rework. It represents the knowledge that was initially perceived to be gained but turned out to be incorrect or misleading.
- Information Loss Rate: The 'information loss rate', defined as the ratio of lost information to the total perceived information, provides a measure of the 'inefficiency' or 'error rate' of the software development process. A lower information loss rate indicates a more efficient process with less rework.
- Knowledge-Centric Perspective: These metrics align with a knowledge-centric standpoint, where the focus is on the efficient use and management of knowledge. They can be used to identify areas of the process where rework is high and knowledge management can be improved.
- Continuous Improvement: By measuring rework using 'lost information' and 'information loss rate', we can track our progress, refine our strategies, and focus our resources on the most impactful areas, providing a concrete, quantifiable basis for continuous improvement in the knowledge-centric software development process.
Introduction
Software development, as a complex socio-technical activity, presents numerous opportunities for waste to occur. Defined as any activity that yields no value for the customer or user, waste can manifest in several forms in software development projects, including the prevalent issue of rework[1]
In the realm of software development, rework is often seen as a necessary evil. It's the process of revising, correcting, or otherwise modifying software after it has been developed. Essentially, software development is a process of knowledge acquisition and ignorance reduction[2]. When we view this process from a knowledge-centric standpoint — where software development operates on knowledge much like a car runs on fuel — we begin to see rework as a significant form of waste.
In this context, we define 'rework' as a situation where existing knowledge (akin to laid bricks) is replaced with new information. Rework can be seen as a form of waste if it's due to avoidable mistakes or poor knowledge-acquisition and application practices. This replacement of knowledge, or 'lost information', can be quantified and tracked, providing us with a tangible metric for measuring rework.
It's important to note that rework, as defined here, is distinct from design iterations intended for rapid learning, where design decisions are viewed as experimental and subject to change. It's also different from fast project cycles designed to accelerate customer feedback.
In this article, we'll explore how to measure reworks as a form of waste from a knowledge-centric perspective. We'll introduce the concept of 'information loss rate', a measure of the 'inefficiency' or 'error rate' of the software development process. A lower information loss rate indicates a more efficient process with less rework.
We'll look at how we accumulate learnings about an application over time and the challenge of modifying the program to reflect these learnings, as if we had known what we were doing from the start and that it had been easy to do." This perspective will provide a fresh lens through which to view and measure rework as a form of waste in software development, and offer a new approach to improving efficiency and reducing waste.
The Knowledge-Centric Perspective
In the context of software development, a knowledge-centric standpoint refers to a perspective that places knowledge at the core of the development process. It recognizes that software development is not just about writing code, but also about discovering, sharing, and applying knowledge. This knowledge includes understanding of the problem domain, the needs of the users, the architecture of the system, the chosen technologies, and the best practices in software engineering, among others.
Knowledge is crucial in software development because it informs the decisions that developers make at every stage of the process. From understanding the requirements to designing the architecture, from writing the code to testing the system, every step relies on the application of knowledge. The quality of the decisions made at each of these stages, and hence the quality of the final product, depends on the quality and the completeness of this knowledge.
Rework refers to the process of revising, correcting, or otherwise modifying software after it has been developed. This could be due to bugs, defects, or changes in requirements.
Rework can be seen as the result of gaps in knowledge or the misapplication of knowledge. It typically manifests in two forms:
- Changes to 'What' should be built, involving altering or removing features, which, in turn, changes the code and the user-facing functionality.
- Changes to 'How' to build the 'What,' otherwise known as refactoring. This involves altering the code without changing the user-facing functionality.
For instance, if the developers do not fully understand the requirements, they might build a feature that does not meet the users' needs, leading to rework. Similarly, if there is a gap in the developers' understanding of the chosen technologies, they might write code that is inefficient or hard to maintain, leading to waste in the form of time spent on unnecessary optimization or refactoring.
Miscommunication, which can be seen as a failure in the sharing or transfer of knowledge, can also lead to rework and waste. If the requirements are not communicated clearly to the developers, or if the developers do not communicate effectively among themselves, it can result in code that does not meet the requirements or that is inconsistent with other parts of the system.
In this light, reducing rework and waste is not just about improving coding practices, but also about improving knowledge management practices. It's about ensuring that the right knowledge is generated, that it is shared effectively among the team, and that it is applied correctly in the development process.
Rework can be seen as a form of waste if it's due to avoidable mistakes or poor knowledge-acquisition and application practices. When existing knowledge is replaced with new information, it results in a loss of information and an increase in the time and resources spent on the development process. This is the "death by a thousand cuts", where each cut is a piece of knowledge replaced.
The impact of rework and waste on software development processes and outcomes is significant. They lead to increased development time, higher costs, and potentially lower quality of the final product. They can also lead to frustration and decreased morale among the development team.
From a broader perspective, rework and waste can hinder an organization's ability to deliver value to its customers in a timely and efficient manner. They can slow down the pace of innovation and make it more difficult for the organization to respond to changes in the market or customer needs.
Therefore, understanding and managing rework and waste is crucial for any organization that wants to be efficient and competitive in the software development industry. By measuring and reducing rework and waste, organizations can improve their processes, deliver higher quality products, and provide more value to their customers.
Measuring Rework
In the realm of software development, rework is an inevitable part of the process. It's a reflection of the iterative nature of development, where we continuously refine and improve our work based on new insights, feedback, and changing requirements. However, unchecked or excessive rework can lead to inefficiencies, delays, and increased costs. It's a form of waste that we strive to minimize in our pursuit of lean and efficient development processes. Therefore, measuring rework is of paramount importance. It allows us to quantify the extent of this waste, identify its sources, and devise strategies to reduce it.
In this context, we introduce two concepts for measuring rework: 'lost information' and 'information loss rate'. These metrics stem from the field of Information Theory and provide a perspective on rework from a knowledge-centric standpoint.
'Lost information' represents the knowledge that we initially perceived to be gained during the development process but turned out to be incorrect or misleading. It's the information that, in hindsight led us down the wrong path and resulted in rework.
Imagine you're developing a feature based on certain assumptions or information you have at hand. You invest time and resources into building it, only to find out later that the assumptions were incorrect or the information was misleading. The feature doesn't meet the requirements, or it doesn't integrate well with other parts of the system, or it doesn't deliver the expected value. You have to go back, undo or modify what you've done, and do it again correctly. The initial information that led you to build the feature incorrectly in the first place is what we refer to as 'lost information'.
Lost information is a reflection of the gaps in our understanding, the inaccuracies in our knowledge, and the miscommunications in our interactions. It's a measure of the 'noise' in our development process that obscures the 'signal' and leads us away from the optimal path.
For a detailed explanation on how to quantify and track lost information in a software development project, please follow this link to a dedicated article on the topic.
In our quest to measure and minimize rework in software development, we introduce the concept of 'information loss rate'. This metric is defined as the ratio of 'lost information' to the 'total perceived missing information'. The 'total perceived missing information' represents the sum of the actual information gained (the correct knowledge that led to productive work) and the lost information (the incorrect or misleading knowledge that led to rework). The 'information loss rate' is then the proportion of this total perceived missing information that was lost. In essence, it provides a measure of the 'inefficiency' or 'error rate' of the software development process.
Below is an animated example of calculating Information Loss Rate (L) when we search for a gold coin hidden in 1 of 64 boxes.

This metric provides a normalized measure of rework that allows us to compare the efficiency of different developers, projects, teams, and time periods, regardless of their size or complexity.
A lower information loss rate indicates a more efficient process with less rework. It signifies a higher signal-to-noise ratio in the information flow, a better alignment between perceived and actual knowledge, and a more effective management of knowledge in the development process.
Quantifying and tracking the information loss rate in a software development project can provide valuable insights into the efficiency of the process and the effectiveness of our strategies to reduce rework. It can help us identify the areas where our process is most prone to errors and where our efforts to improve can have the greatest impact.
For a detailed explanation on how to quantify and track the information loss rate in a software development project, please follow this link to a dedicated article on the topic.
Applying Lost Information and Information Loss Rate
From a knowledge-centric standpoint, where the focus is on the efficient use and management of knowledge, the concepts of 'lost information' and 'information loss rate' are particularly relevant and insightful. They provide a way to quantify and track the efficiency of our knowledge management in the software development process.
These metrics align perfectly with the knowledge-centric view because they directly measure the extent to which our perceived knowledge (what we think we know) matches the actual knowledge (what is truly correct and useful). They provide a measure of the 'noise' in our knowledge management process and the 'signal-to-noise ratio' in our information flow.
For instance, consider a stacked bar chart that presents how rework for a developer is distributed across different software development projects.
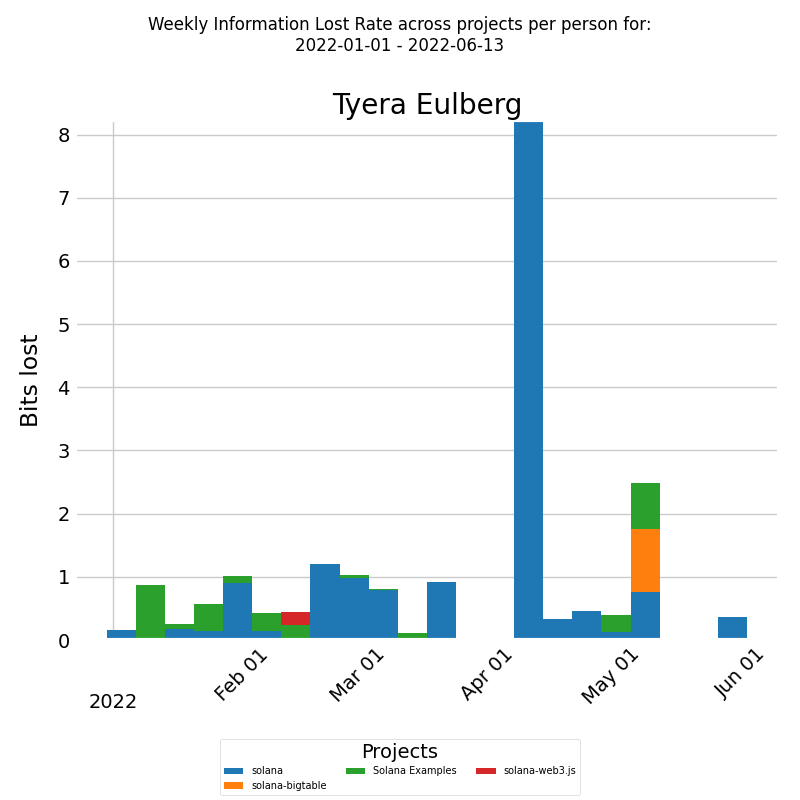
The x-axis shows the week dates and the y-axis shows the amount of bits of information lost per week. Each bar represents the bits lost per week by the selected developer, which is further divided into boxes. Each box corresponds to the fraction of bits lost per week by the developer for a particular project. The color of each box represents a different project. This way, we have a clear visualization of how much bits of information the developer replaced for each project during the selected time period. The information loss rate for each project can be compared.
By visualizing and analyzing the information loss rate, we can identify the projects where the rework is high, and where our knowledge management can be improved. We can see where our perceived knowledge is most misaligned with the actual knowledge, where our assumptions and communications are most prone to errors, and where our learning and adaptation are most needed.
These insights can guide our efforts to reduce rework and improve efficiency. They can help us focus our resources on the most impactful areas, refine our strategies, and track our progress. They provide a concrete, quantifiable basis for our continuous improvement in the knowledge-centric software development process.
For a more detailed understanding of how to leverage these insights to reduce rework, you can refer to this article. This resource provides a comprehensive guide on how to apply the concepts of 'lost information' and 'information loss rate' to effectively minimize rework in your software development projects.
Conclusion
In the ever-evolving landscape of software development, the ability to measure and manage rework is of paramount importance. Rework, when viewed from a knowledge-centric standpoint, can be seen as a form of waste - a replacement of existing knowledge with new information. This perspective allows us to quantify rework in terms of 'lost information' and 'information loss rate', providing us with tangible metrics to track and improve our processes.
Measuring rework using 'lost information' and 'information loss rate' offers a powerful approach to improving efficiency and reducing waste in software development. By embracing these metrics, we can enhance our understanding of our processes, make more informed decisions, and ultimately deliver better software faster.
Works Cited
1. T. Sedano, P. Ralph and C. Péraire, "Software Development Waste," 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 2017, pp. 130-140, doi: 10.1109/ICSE.2017.20.
2. Armour, P.G. (2003). The Laws of Software Process, Auerbach
How to cite:
How to Measure Rework as a Form of Waste in Software Development? https://docs.kedehub.io/kede/kede-rework-waste.html
Getting started


