Understanding the details of Knowledge Discovery
Through the lens of Information Theory
Total unconditional missing information
"Lack of knowledge…that is the problem. we should not ask questions without knowledge. If we do not know how to ask the right question, we discover nothing." ~ W. Edwards Deming
In order to correctly define a problem, we must consider all possible definitions, which form the problem space (as shown in the image below).

The gold coin represents the correct definition for the problem we are addressing. We need to find the gold coin, i.e., correctly define our problem, as we believe a correct definition is necessary for solving a problem.
Finding the correct definition is an example of a process known as "knowledge discovery,".
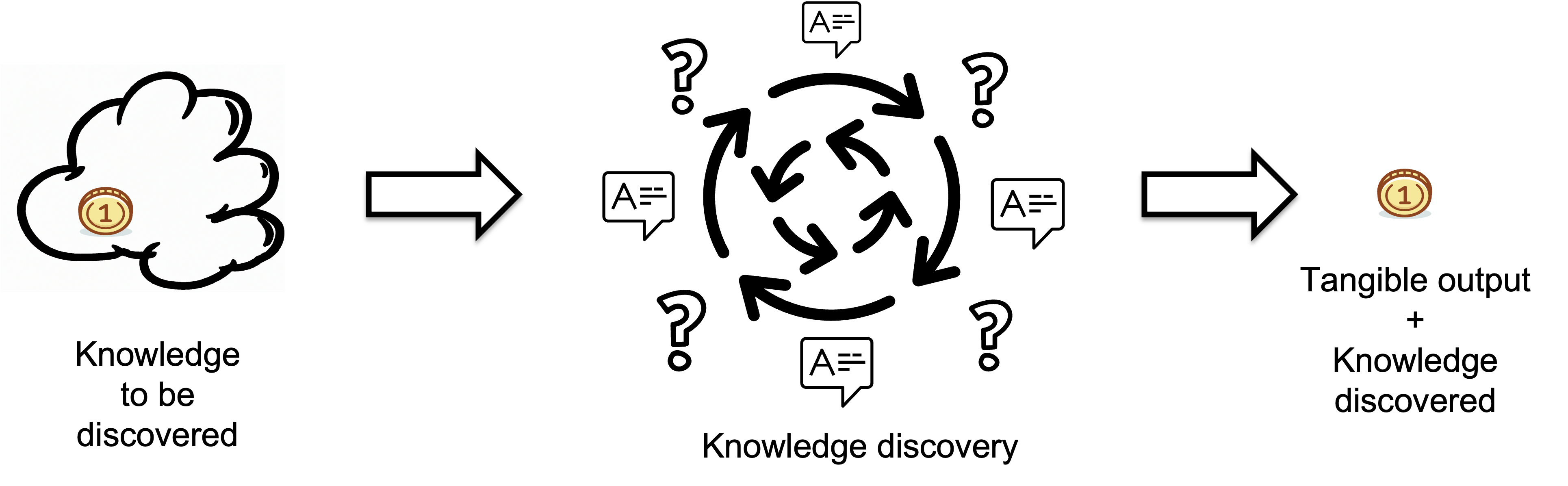
This process takes some knowledge to be discovered as input, or in other words, "what do we need to know?" The result of knowledge discovery is the knowledge that is discovered. In our case that would be the correctly definition of our problem. Knowldge discivery works by gaining infirmation i.e. reducing missing information.
Missing information, also known as "uncertainty", is mathematically defined for a "random variable" using Shannon's formula. However, it is important to remember that physical systems are not purely mathematical; they are complex and often messy. When we observe a physical object through a measurement device, we are essentially looking at it through a "mathematical looking glass" with a finite resolution. This means that the missing information of the object is not inherent to the object itself, but rather defined by the measurement device we use to examine it. A measurement device means we already know something. It specifies what questions we can ask about a system.
In order to find the gold coin (i.e., correctly define the problem) in the problem space, we must establish a measurement device. This process, which is an example of "knowledge discovery," is illustrated in the image below.
In the example depicted in the figure, we go through the three states of knowledge discovery in order to learn about a single problem. At the beginning of the process, we are not sure where the gold coin we are looking for is located within the problem spaces. However, as we progress through the states, we are able to narrow down the possibilities.
Knowledge discovery involves three stages:
-
We don't know anything about the problem space.
At the start of the knowledge discovery process, we have little to no understanding of the problem space. It is like a cloud, where we cannot determine the number of alternative definitions or possible states. If we are not even aware of how much we don't know, we are dealing with "unknown unknowns." In this initial stage, we must first gather information and try to clarify the boundaries of the problem space.
-
We know nothing about the problem space except how many states it has.
When we have very little information about a probability distribution and cannot make any other assumptions, we must assume that each state has an equal probability of occurring. This reflects a maximal level of uncertainty. This principle, known as the "maximum entropy principle," states that the probability distribution that best represents our current understanding of a system is the one with the largest amount of missing information, or Hmax[4][5]. This is because, in the absence of other information, our uncertainty must be at its maximum.
On Fig. 2, the knowledge to be discovered Hmax left after the transition from State 1 to State 2 can be expressed as: "partitioning the problem space of 'unknown unknowns' using some knowledge." This process can also be represented by the following formula:
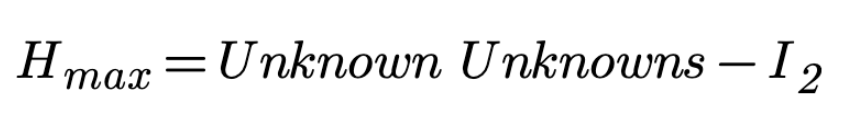
where I2 represents the knowledge (measurement device) we used to partition the problem space of "unknown unknowns" into N states. I2 represents the knowledge we gained in the second stage. Information gain is a measure of the reduction in missing information that occurs when objects are classified into different classes. It is frequently used in the construction of decision trees from a training dataset by evaluating the information gain of each variable and selecting the variable that maximizes the information gain, which in turn minimizes missing information and divides the dataset into the most effective groups for classification. Information gain is calculated by comparing the missing information of a dataset before and after a transformation[6].
If we have no other knowledge about a system except for the number of possible states it can be in, the maximum missing information Hmax is equal to the logarithm of the number of possible states.
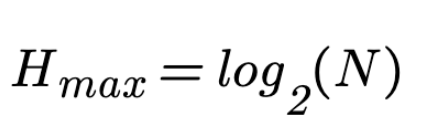
where N represents the number of states. In this particular case presented on Fig. 2, we have divided the problem space into four parts. Therefore, we can calculate Hmax as being equal to Hmax=2 bits of information.
-
We know the states and the probabilities of each state.
In the third stage of knowledge discovery, we are aware of the possible states and the probability of each state. This missing information, represented by H(X) is conditional on some new knowledge, which we will refer to as I3. H(X) can be calculated using Shannon's formula.
On Fig. 2, the knowledge to be discovered H(X) left after the transition from State 2 to State 3 can be quantified as: "what remains to be discovered equals what we don't know minus what we know." This process can also be represented by the following formula:
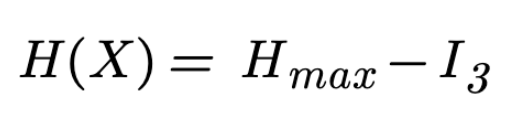
where I3 represents the knowledge we used to assign probabilities to the partitions of the problem space, based on a particular non-uniform probability distribution.
After reaching State 3, we can start reducing the missing information by eliminating the partitions that do not contain the gold coin. This process is explained in the following sections.
Once we have narrowed it down to a single partition, we can consider that partition as a new problem space at State 1. We can then iteratively follow the same process of knowledge discovery (State 1 -> State 2 -> State 3) until we find the gold coin (i.e., correctly define our problem)."
Joint missing information
Let us quantify our uncertainty i.e., how much we do not know about X by the N1 number of states it can be in. Imagine that there is another system Y, and that one can be in N2 different states. How many states can the joint system (X and Y combined) be in? For each state of the N1 of X, there can be N2 number of states. So the total number of states of the joint system must be N1 x N2. But our uncertainty about the joint system is not N1 x N2. The uncertainty i.e. missing information adds up, it doesn't multiply. Actually, the below inequality hold[2]:
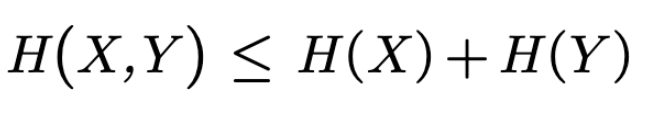
The equality holds when the two random variables are independent:
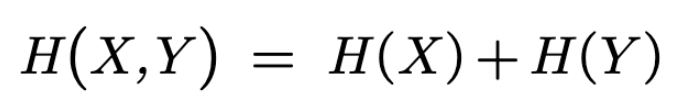
In the figure below, the problem space is represented by X and our prior knowledge is represented by Y.
At this point, X and Y are not connected i.e. are independent. This means we have not yet tried to apply our prior knowledge Y to the current problem X.
The last two results imply that if we have two experiments (or two games) with independent outcomes, then the missing information about the outcomes of the two experiments is the sum of the missing information about the outcomes of each individual experiment.
On the other hand, if there is dependence between the two sets of outcomes, then the missing information about the compound experiment H(X,Y) will always be less than the missing information about the two experiments separately. In this case, we use conditional probabilities.
Conditional missing information
"Without theory, experience has no meaning. Without theory, one has no questions to ask. Hence without theory there is no learning."- W. Edwards Deming[3]
In information theory, the concept most closely related to "knowledge to be discovered" between two random variables X and Y is conditional entropy, denoted H(X|Y). It measures the uncertainty of X given Y and is defined as the expected entropy of X, given Y. The conditional entropy represents the amount of missing information in X after taking into account the information in Y. It can be derived from mutual information using the equation H(X|Y) = H(X) - I(X;Y).
If Y has high entropy, it means that the information in Y does not significantly reduce the uncertainty of X, resulting in a high H(X|Y). Conversely, if Y has low entropy, it provides useful information to reduce the uncertainty of X, leading to a low H(X|Y).
To reduce missing information, we need to gain more information about a system. One way to do this is by using a theory. Theories can often constrain probability distributions in such a way that we have certain expectations about them before making any measurements. In other words, a theory can shape our prior knowledge.
To formally introduce the concept of conditional missing information, we need to discuss conditional probabilities. A conditional probability represents the likelihood of an event occurring, given that another event has already occurred. To quantify the dependence between two events, we examine two random variables, which may or may not be independent.
Probability distributions are initially uniform, meaning we have no knowledge about the variable except possibly the number of states it can take on. Once we gain information about the states, the probability distribution becomes non-uniform, with some states being more likely than others. This information is reflected in the form of conditional probabilities. We can only truly know that a particular state is more or less likely than the random expectation if we have some other knowledge about the system at the same time.
We view all probabilities as being conditional on one or more hypotheses rather than absolute, meaning they depend on the evidence or state of knowledge used to formulate them. While probabilities are subjective in that they rely on available information, they are also objective in that any rational observer would assign the same values. As a result, any probability distribution and the missing information it contains are largely anthropomorphic.
In the figure below, we see the missing information of X after applying our prior knowledge Y.

The parts of the figure labeled 5, 6, and 7 represent the conditional missing information H(Y|X). The parts labeled 2, 3, and 4 represent the conditional missing information H(X|Y), or the missing information that remains after applying our prior knowledge Y to problem X.
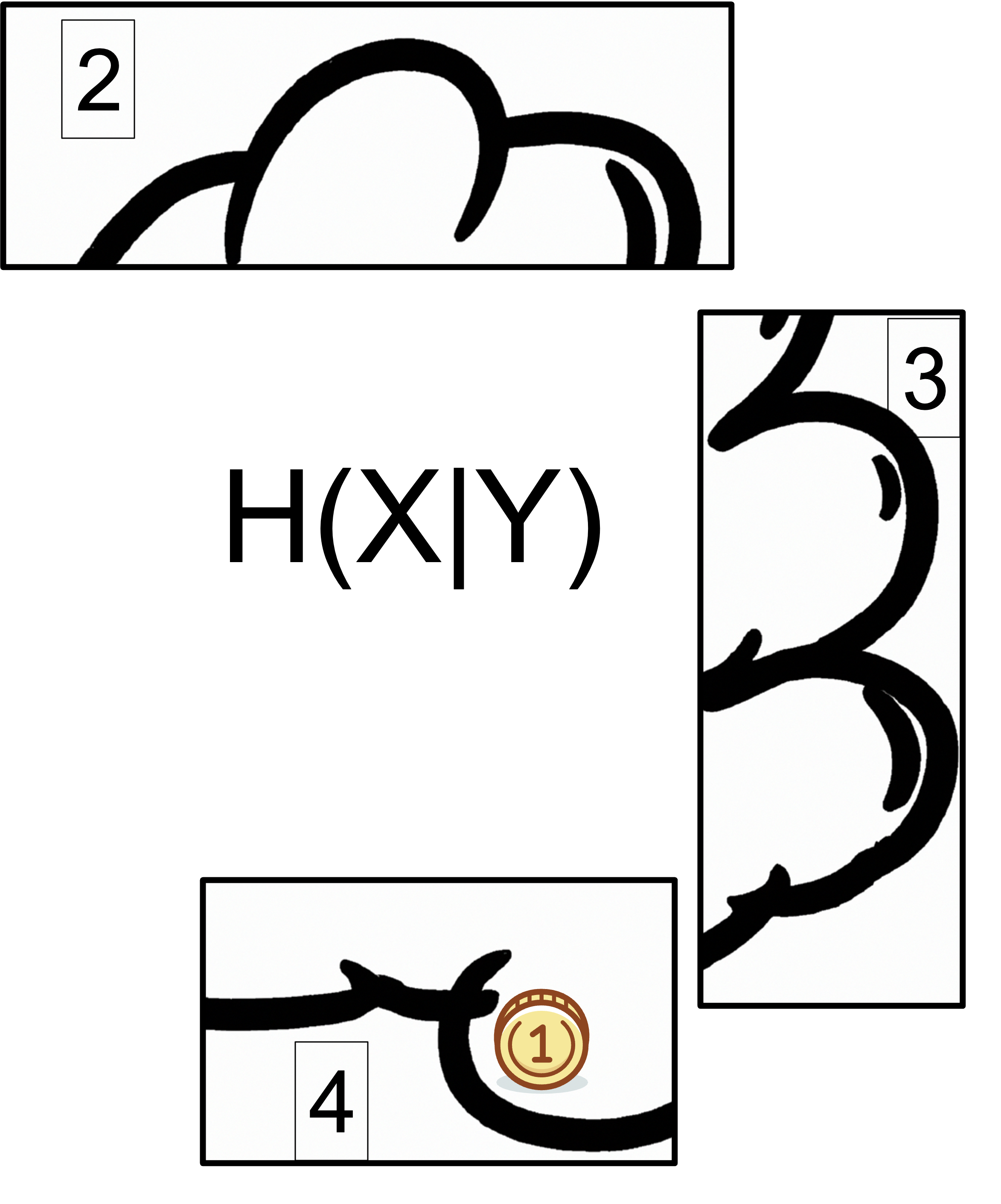
In the formula below, conditional missing information (i.e., knowledge to be discovered) H(X|Y) is defined as the difference between the missing information H(X). minus the mutual missing information I(X:Y).
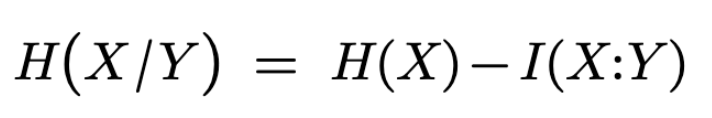
We also obtain the inequality[2]:
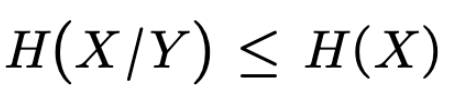
This means that the missing information on X can never increase by knowing Y. Alternatively, H(X|Y) represents the average uncertainty that remains about X when Y is known. This uncertainty is always less than or equal to the uncertainty about X. If X and Y are independent, then equality holds.
It is possible to refer to H(X|Y) as "observed entropy," as it represents the missing information in X given that the value of Y is known. It quantifies the remaining missing information in X after accounting for Y.
The "observed entropy" reflects the knowledge an observer has about a system. However, while observed entropy is subjective—depending on prior knowledge and perspective—conditional entropy H(X|Y) is an objective measure that depends only on the probability distribution of X and Y.
Mutual information
As we discussed previously, prior knowledge refers to the information and understanding that an individual has before engaging in a task or problem. It serves as a starting point for reducing uncertainty and understanding a given distribution.
Let's refer back to the game of hiding a gold coin. This time, we'll represent the eight boxes of equal size as the random variable X, which follows a uniform distribution with 8 possible values and a true entropy of 3 bits. Let Y be another random variable representing a uniform distribution with 4 states that are present in X. In this case, Y serves as "prior knowledge" about X, as it provides partial information about its possible outcomes.
However, having prior knowledge does not mean we know everything about the distribution. We still have missing information in X, but Y helps narrow down the possibilities.
Now, consider another scenario where Y is a uniform distribution with 8 states, 4 of which are present in X and 4 of which are not. Since Y contains extraneous information unrelated to X, it would be more accurate to refer to Y as "prior information" or "partial prior knowledge" rather than "prior knowledge." Understanding the relationship between X and Y is essential to effectively use this prior information.
Mutual information quantifies the amount of information shared between two random variables. It is defined as the reduction in uncertainty about one variable given that the value of the other variable is known.
In this sense, mutual information can be seen as a form of prior knowledge, as it represents the information gained about X when Y is known. The figure below illustrates this concept:
The shared part labeled 1=8 is the mutual information I(X:Y), indicating what Y knows about X and vice versa. Because I(X:Y) is defined symmetrically, it tells us exactly how much of our information about X comes from Y. If I(X:Y) is equal to the combined area of parts 2, 3, and 4, then we were able to remove 1 bit of missing information from H(X).
The remaining missing information to be discovered H(X|Y) is conditional on Y.
Mutual information is sometimes referred to as the "knowledge shared" between X and Y, as it measures how much information is common between them. However, we still need to use this information to "discover knowledge."
Additionally, I(X:Y) is often described as the average amount of information that X conveys about Y (and vice versa). It measures the extent of dependence between the two variables and is always non-negative. If X and Y are independent, I(X:Y) = 0.
Finally, mutual information and information gain are essentially the same concept, though they are used in different contexts. Since both measure the reduction in uncertainty when new information is introduced, mutual information is sometimes used as a synonym for information gain.
Multivariate mutual information
Multivariate mutual information is a measure of the amount of mutual dependence between multiple random variables. It is a generalization of the concept of mutual information, which is used to quantify the dependence between two random variables. In the case of four dependent variables, it quantifies the degree of association between all possible pairs of the variables, as well as the association between all possible combinations of three and four variables[9].
The full range of their possible information-theoretic relationships appears in the information diagram (I-diagram) below:
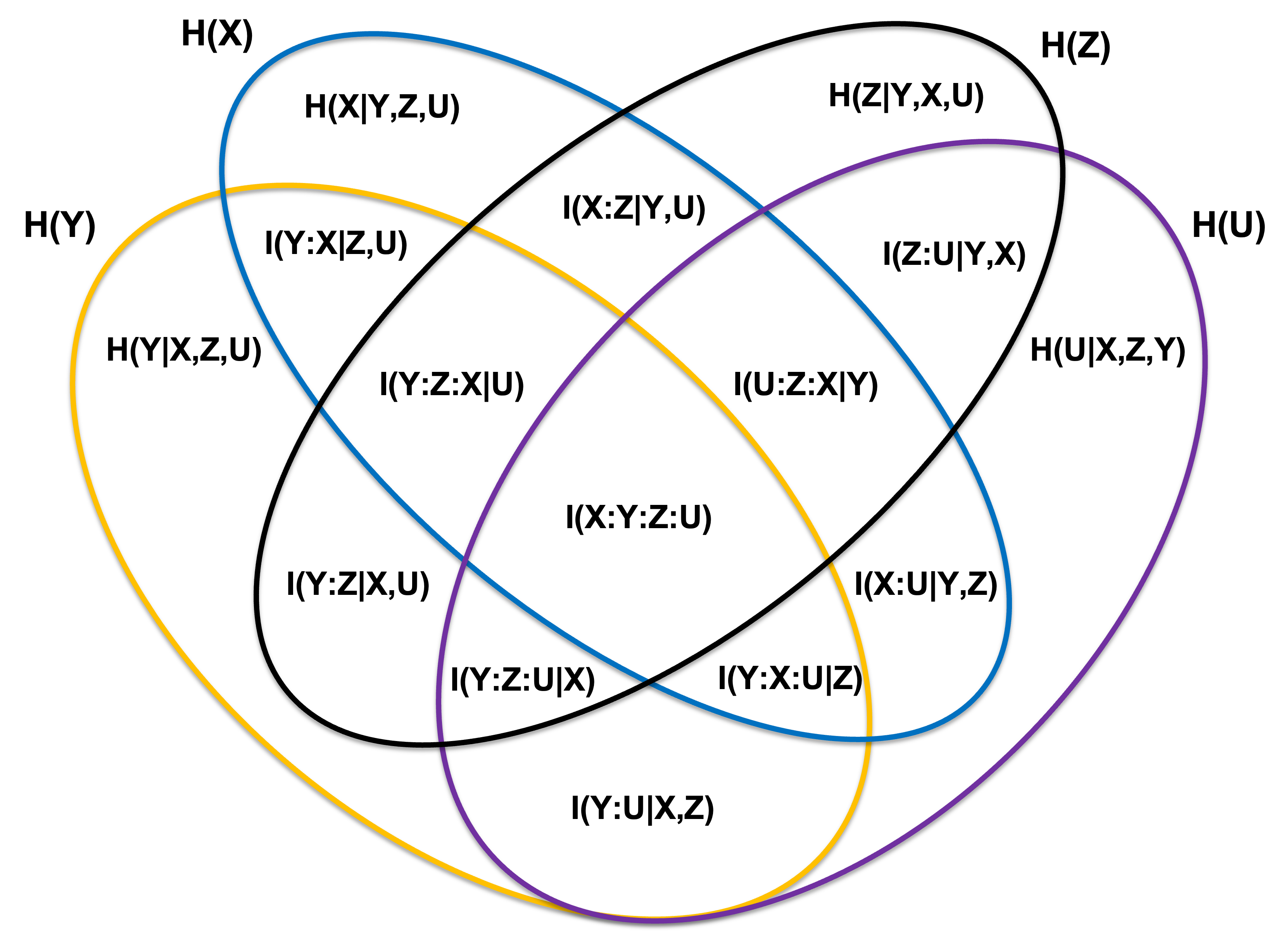
Where, we are interested only in the bellow listed quantities:
- I(X:Y:Z:U) is the joint mutual information of X,Y,Z and U
- I(X:Z|Y,U) is the conditional mutual information between X and Z given Y and U. It quantifies the dependence between X and Z given that the variables Y and U are known.
- I(Y:Z:X|U) is the conditional multivariate mutual information between three random variables Y, Z and X, given another random variable U. It's a measure of the amount of mutual dependence between Y, Z and X given U. In mathematical terms, I(Y:Z:X|U) can be defined as the difference between the joint entropy of Y, Z, X given U and the sum of the individual entropies of Y, Z, X given U. Mathematically it can be defined as I(Y:Z:X|U) = H(Y,Z,X|U) - H(Y|U) - H(Z|U) - H(X|U)
- I(U:Z:X|Y) is the conditional multivariate mutual information between three random variables U, Z and X, given another random variable Y. It quantifies the dependence between U, Z, and X given that the variable Y is known.
It is important to note that, this representation of conditional multivariate mutual information is based on the assumption that all variables are discrete.
Lost information
Consider an example. Suppose we have eight boxes of equal size, with a gold coin hidden in one of them. The goal is to locate this gold coin by asking binary (yes/no) questions. I start by dividing the eight boxes into two groups of four (a left and right group) and inquire if the coin is in the left group. The response is affirmative, leading me to divide the left group into two smaller groups of two boxes each (left and right), and I ask the same question. Again, the answer is affirmative. At this point in time I learn that my initial binary question was answered incorrectly; the coin was not in the left group after all. This means I need to start my questioning from the beginning due to this misinformation.
In the scenario we've described, the incorrect answers to my questions have led to a loss of information. I initially gained information from the answers to my questions, which allowed me to reduce the number of boxes where the coin could be. However, when I found out that those answers were incorrect, the information I gained turned out to be false, and I had to discard it and start over. This is a form of information loss.
In terms of information theory, this could be seen as an increase in the missing information, or uncertainty, of the system. When I received the answers to my questions, I reduced the missing information by narrowing down the possible locations of the coin. But when I found out the answers were incorrect, the missing information increased again because the possible locations of the coin again became as uncertain as in the beginning.
So in this context, the "lost information" could be quantified as the increase in remaining missing information resulting from the discovery that the initial answers were incorrect.
Let's frame our example in terms of two random variables X and Y, mutual information I(X;Y), and conditional missing information H(Y|X).
Let's define:
- X as the true location of the gold coin.
- Y as the answers to my questions.
- missing information of X, H(X): This is the total uncertainty or missing information of the system before any questions are asked. In our case, with 8 boxes and the coin equally likely to be in any box, the missing information is maximum and can be calculated as
- Mutual Information, I(X;Y): This is the amount of information gained about X (the location of the coin) by knowing Y (the answer to a question). If the answer to a question is correct, it reduces the number of possible locations of the coin by half, so each correct answer provides 1 bit of information, reducing the remaining uncertainty H(X|Y) of X by 1 bit.
- Conditional missing information, H(X|Y): This is the remaining uncertainty about X (the location of the coin) after knowing Y (the answer to a question). If an answer is incorrect, it means that the information gained from that answer was false, and the missing information of X given that answer is actually higher than previously thought. Each incorrect answer increases the conditional missing information H(X|Y) by 1 bit, because it adds back one bit of uncertainty about the location of the coin.
- The relation between the three quantities is:
Initially, I have no information about X, so the missing information H(X) is at its maximum (log2 of the number of boxes, in this case, = 3 bits of information).
When I ask a question and receive an answer, I gain some information about X. This is represented by the mutual information I(X;Y). If the answers are correct, each question reduces the uncertainty of X by 1 bit (since each question divides the number of possible locations of the coin by 2).
However, if I find out that an answer was incorrect, the information I gained from that answer turns out to be false. This could be represented as an increase in the conditional missing information H(X|Y), the remaining uncertainty about X given the knowledge of Y. In this case, the conditional missing information increases by 1 bit for each incorrect answer, because each incorrect answer adds back one bit of uncertainty about the location of the coin.
When an answer is correct, it reduces the uncertainty about X, and this reduction in uncertainty is quantified by the mutual information. When an answer is incorrect, the supposed reduction in uncertainty turns out to be false, and the actual uncertainty about X is higher than what the mutual information suggested. This discrepancy could be thought of as the "lost information".
The "lost information" is the information I initially thought I gained from the incorrect answers, but which turned out to be false.
So, in this context, the "lost information" due to an incorrect answer could be quantified as an increase in the conditional missing information H(X|Y). For each incorrect answer, I "lose" 1 bit of information, because I have to add back one bit of uncertainty about the location of the coin. The "lost information" can be thought of as the difference between the reduction in uncertainty suggested by the mutual information and the actual reduction in uncertainty, which is less due to the incorrect answer.
This can be represented as:
Where:
- is the conditional missing information of X given the incorrect answer, which is higher because the incorrect answer adds uncertainty.
- is the conditional missing information of X given the correct answer, which is lower because the correct answer reduces uncertainty.
This equation gives a measure of the "lost information" due to incorrect answers.
Let's try to incorporate mutual information into the picture. In the context of the gold coin example, the total information received (H) would be the sum of the information I gained from the correct answers and the information I initially thought I gained from the incorrect answers.
The equation H = Mutual Information + Information Lost is a general conceptual equation that describes the total information received (H) as the sum of the mutual information (the information successfully conveyed) and the information lost (the information intended to be conveyed but not successfully received due to errors, noise, or other forms of interference).
Let's break it down:
- Information from Correct Answers (Mutual Information from Correct Answers): Every time I asked a binary question and received a correct answer, I gained mutual information. This mutual information I(X;Y_correct) reduced the uncertainty about the location of the coin (X). For example, when I asked if the coin is in the left group of 4 boxes and the answer was "yes", I gained 1 bit of information that reduced the number of possible locations for the coin from 8 to 4.
- Information from Incorrect Answers (Apparent Mutual Information from Incorrect Answers): When I received an incorrect answer, I initially thought I were gaining mutual information. This apparent mutual information I(X;Y_incorrect) did not actually reduce the uncertainty about the location of the coin, but I initially believed it did. For example, when I asked if the coin is in the left group of 2 boxes and the answer was "yes" (but this was incorrect), I initially thought I had gained mutual information that reduced the number of possible locations for the coin from 4 to 2.
- Lost Information: The "lost information" is the apparent mutual information I initially thought I gained from the incorrect answers, but which turned out to be false. This can be thought of as negative mutual information, because it represents a decrease in the actual mutual information about the location of the coin. This lost information is equal to the apparent mutual information from incorrect answers I(X;Y_incorrect) minus the actual mutual information (which is zero for incorrect answers).
Based on the previous explanation, the "lost information" can be quantified as the difference between the apparent mutual information I initially thought I gained from the incorrect answers and the actual mutual information. Since the actual mutual information from incorrect answers is zero (because they do not reduce uncertainty about the coin's location), the "lost information" is simply the apparent mutual information from incorrect answers.
If we denote the apparent mutual information from incorrect answers as I apparent, the equation for the lost information H lost would be:
Since = 0 for incorrect answers, this simplifies to:
This equation quantifies the "lost information" as the apparent mutual information I initially thought I gained from the incorrect answers.
As an example, if the total missing information H(X) = 3, this means that there are 2^3 = 8 possible outcomes (or locations for the coin), which is consistent with our example.
If I experienced 1 wrong answer to a binary question, this means that I initially thought I had reduced the number of possible outcomes by half. In terms of missing information, this would correspond to a reduction of 1 bit of missing information, since each binary question reduces the missing information by 1 bit.
However, since this answer was incorrect, this apparent reduction in missing information did not actually occur. Therefore, the "lost information" Hlost would be equal to the apparent reduction in missing information that I initially thought I had achieved, which is 1 bit.
So, in this case, Hlost = 1 bit. This represents the amount of information that I initially thought I had gained from the incorrect answer, but which turned out to be false.
Perceived missing information is the sum of the actual missing information of a system H(X) and the additional missing information perceived due to incorrect or misleading information Hlost. It represents the total amount of uncertainty perceived about a system, taking into account both the actual uncertainty and the additional uncertainty introduced by incorrect or misleading information.
Mathematically, we could express this as:
where:
- H(X) is the actual missing information of the system, representing the actual number of questions needed to locate the gold coin, which is akin to the mutual information I(X;Y), and not the inherent uncertainty about the state of the system. This is because the mutual information I(X;Y) quantifies the amount of information gained about one random variable (in this case, the location of the gold coin) by observing another random variable (in this case, the answers to my questions). So, if I were lucky and found the gold coin with just one question, then H(X) would be 1 bit, even though the average minimum number of binary questions needed to locate the gold coin in 8 boxes would be 3 bits.
- Hlost is the "lost information" due to incorrect or misleading information, representing the additional perceived uncertainty introduced by this incorrect or misleading information.
In the context of our example, Hperceived would represent the total amount of uncertainty I perceived about the location of the coin, taking into account both the actual uncertainty and the additional uncertainty introduced by the incorrect answer.
So, if H(X) = 3 bits (representing 8 possible locations for the coin) and Hlost = 1 bit (representing the incorrect answer), then the total perceived missing information would be Hperceived = 3 bits + 1 bit = 4 bits. This would represent a perceived uncertainty of 16 possible locations for the coin, even though there are actually only 8 possible locations.
The term "perceived missing information" is not a standard term in Information Theory or other scientific fields. The concept of "perception" introduces a subjective element that is typically not present in the mathematical formulations of Information Theory, which deals with quantifiable measures of information, uncertainty, and missing information.
However, in broader contexts, the idea of "perceived missing information" or "perceived uncertainty" could potentially be used to describe situations where the subjective perception or understanding of a situation differs from the objective, quantifiable uncertainty. This might be relevant in fields like psychology or decision theory, where the focus is on understanding human perception and decision-making processes[7][8].
Information Loss Rate
Hlost, as we've defined it, represents the amount of information that was thought to be gained but was actually not due to incorrect answers. In the context of searching for a gold coin, a lower Hlost would indicate a more efficient or accurate process, because it means less information was lost due to incorrect answers.
We can use Hlost as a metric to compare two different processes searching for a gold coin. Remember, this metric assumes that all other things are equal, such as the total number of questions asked and the initial missing information (total number of possible locations for the coin). If these factors vary between the two processes, we need to take them into account when comparing the processes. For that, we need to normalize the Hlost value to make a fair comparison.
Let's consider the gold coin example where we have 8 boxes and I am asking binary questions to find the coin. Let's say I asked a total of 3 questions. The first two questions were answered incorrectly, and the third question was answered correctly. So, we have Hlost = 2 (from the two incorrect answers) and total number of questions asked was 3.
I asked a total of 3 questions. The first two questions were answered incorrectly, and the third question was answered correctly. Each question reduces the perceived missing information by 1 bit (since they are binary questions), so after asking 3 questions, I have reduced the perceived missing information by 3 bits.
The fact that the first two questions were answered incorrectly doesn't change the amount of perceived missing information reduction, because from my perspective at the time I asked those questions, I believed I were reducing the missing information. It's only in hindsight, after learning that those answers were incorrect, that I realize some of that perceived missing information reduction was actually "lost information".
In our definitions, Hperceived is the sum of the actual missing information H(X) and the additional perceived missing information due to incorrect or misleading information (Hlost).
In aour scenario, where I asked 3 questions and the first two were answered incorrectly, H(X) would be 1 bit (since I found the coin after 3 questions, the actual missing information was reduced to 1 bit), and Hlost would be 2 bits (from the two incorrect answers). So, Hperceived would be H(X) + Hlost = 1 bit + 2 bits = 3 bits.
In the context of our gold coin example, H(X) represents the actual number of questions needed to locate the gold coin, which is akin to the mutual information I(X;Y) in this scenario.
This is because the mutual information I(X;Y) quantifies the amount of information gained about one random variable (in this case, the location of the gold coin) by observing another random variable (in this case, the answers to my questions).
So, if I were lucky and found the gold coin with just one question, then H(X) would be 1 bit, even though the average minimum number of binary questions needed to locate the gold coin in 8 boxes would be 3 bits.
Thus, normalizing by the perceived missing information Hperceived instead of the total number of questions could provide a more accurate measure of efficiency in the context of our gold coin example.
This is because Hperceived takes into account both the actual number of questions needed to locate the gold coin (H(X)) and the additional perceived missing information due to incorrect or misleading information (Hlost).
By normalizing by Hperceived, we're essentially measuring the proportion of the total perceived missing information that was due to incorrect or misleading information. This gives a measure, which can be useful for comparing different processes even if they involve different numbers of questions or different initial entropies.
"Information Loss Rate" is a suitable term for the ratio Hlost / Hperceived. It accurately describes the concept we're trying to convey: the rate at which information is lost in relation to the total perceived information.
Thus, for our example scenario, the Information Loss Rate (L) would be:
L = Hlost / Hperceived = 2 / 3 ≈ 0.67
This means that, on average, I lost about 0.67 bits of information per question asked due to incorrect answers. A lower value would indicate a more accurate process, because it means less information was lost per question asked.
Here's how we can calculate Information Loss Rate (L):
- Calculate Hlost for each process For each process, calculate Hlost based on the number of incorrect answers and the apparent reduction in missing information that was initially thought to have been achieved with each incorrect answer.
-
Calculate Information Loss Rate (L) Divide Hlost by the total perceived missing information for each process. By normalizing by Hperceived, we're essentially measuring the proportion of the total perceived missing information that was due to incorrect or misleading information. A lower value would indicate a more efficient process, because it means a smaller proportion of the perceived missing information was due to incorrect or misleading information. The formula would be:
This normalized metric allow us to compare the efficiency of different processes even if they involve different numbers of questions or different initial entropies. The initial missing information (Hinitial) for each process would typically be H(X), which is the actual (objective) missing information of the system representing the average minimum number of binary questions needed to reduce uncertainty to zero.
Mapping the Information Loss Rate (ILR) to a percentage
We might want to map (or rescale) this ILR to a quantity that goes from 0 to 1, to interpret it “as a percentage.” By definition, ILR=1 means that for each “useful bit,” exactly 1 bit of information was discarded, ILR=2 means that for each “useful bit,” 2 bits of information were discarded, and so on.
A very common approach to map the range [0,∞) onto[0,1) smoothly is the function:
This mapping is smooth and monotonic, so you get a continuous scale from 0 to 1 that does not abruptly cap.
Pros:
- Smoothly maps [0,∞)→[0,1)
- ILR=1 maps to 0.5. That is exactly what we want, because it means that for each “useful bit” exactly 1 bit of information was discarded.
- Monotonically increasing.
- Values above ILR=1 do not get squashed into 1, but rather approach it asymptotically.
Cons:
- We do not get an exact “percentage of bits lost” interpretation at face value. We get a smooth 0–1 measure that we can treat as a percentage, but the direct meaning is “ILR out of ILR+1".
Appendix A - Information theory with I-diagrams
If we treat our random variables as sets (without being precise as to what the sets contain), we can represent the different information-theoretic concepts using an Information diagram or short: I-diagram. It’s essentially a Venn diagram but concerned with information content.
This intuition allows us to create and visualize more complex expressions instead of having to rely on the more cumbersome notation used in information theory.
Yeung’s “A new outlook on Shannon's information measures” shows that our intuition is more than just that: it is actually correct! The paper defines a signed measure M that maps any set back to the value of its information-theoretic counterpart and allows us to compute all possible set expressions for a finite number of random variables. The variables have to be discrete because differential entropy is not consistent. (This is not a weakness of the approach but a weakness of differential entropies in general.)
M is a signed measure because the mutual information between more than two variables can be negative. This means that, while I-diagrams are correct for reading off equalities, we cannot use them to intuit about inequalities (which we could with regular Venn diagrams).
How many atoms are there?
Intuitively, each atom is exactly a non-overlapping area in an I-diagram.
For variables, there are 2n-1 meaningful atoms as we choose for each variable if it goes into the atom as part of the mutual information or as variable to be conditioned on (so two options for each of the variables). The degenerate case that conditions on all variables can be excluded.
How can we compute the atoms?
Every set expression is a union of some these atoms and their area is a sum where each atom contributes with a factor of 0 or 1. Such a binary combination is a special case of a linear combination. All joint entropies are well-defined and thus we can compute the information measure of every atom, which we can use in turn to compute the information measure for any other set expression.
Works Cited
1. Adami C. (2016). What is information?†. Philosophical transactions. Series A, Mathematical, physical, and engineering sciences, 374(2063), 20150230. https://doi.org/10.1098/rsta.2015.0230
2. Ben-Naim, A. (2008), A Farewell to Entropy: Statistical Thermodynamics Based on Information, World Scientific Publishing, Singapore
3. Deming, W. Edwards, (2000). The New Economics for Industry, Government, Education, 2nd Edition,The MIT Press. Cambridge, Mass
4. Jaynes, E. T. (1957). "Information Theory and Statistical Mechanics" (PDF). Physical Review. Series II. 106 (4): 620–630. Bibcode:1957PhRv..106..620J. doi:10.1103/PhysRev.106.620. MR 0087305.
5. Jaynes, E. T. (1957). "Information Theory and Statistical Mechanics II" (PDF). Physical Review. Series II. 108 (2): 171–190. Bibcode:1957PhRv..108..171J. doi:10.1103/PhysRev.108.171. MR 0096414.
6. Quinlan, J.R. Induction of decision trees. Mach Learn 1, 81–106 (1986). https://doi.org/10.1007/BF00116251
7. Corso, K. B., & Löbler, M. L.. (2011). Understanding the subject's behavior in the interaction with a decision support system under time pressure and missing information. JISTEM - Journal of Information Systems and Technology Management, 8(3), 581–604. https://doi.org/10.4301/S1807-17752011000300004
8. Garcia-Retamero, R., & Rieskamp, J. (2009). Do people treat missing information adaptively when making inferences? Quarterly Journal of Experimental Psychology, 62(10), 1991–2013. https://doi.org/10.1080/17470210802602615
9. Bar-Yam, Y. (2004). Multiscale complexity/entropy. Adv.Complex Syst, 7, 47–63.
Getting started


