Sizing Software Development Projects
in Bits of Information
Takeaways
- A knowledge-centric approach to software development project sizing, which measures the size in bits of missing information, captures the intellectual complexity and learning curves inherent in software development, leading to more accurate project estimations.
- This approach views each feature, user story, or epic as a unit of knowledge to be discovered, with more complex or unfamiliar units requiring more effort and time to implement.
- By accounting for the 'missing information' that needs to be discovered, the knowledge-centric approach effectively predicts project size and completion time.
- The adaptability of this approach means it can accommodate varying team knowledge levels and experience, making it a more realistic estimation method than traditional ones.
- Recognizing that software development is as much about knowledge discovery and application as it is about coding, testing, and deploying provides a holistic view of project management and contributes to the overall project success.
Introduction
As the world continues to accelerate towards an increasingly digital future, software systems form the backbone of our modern society. They power our businesses, fuel our creativity, and connect us with each other in ways we've never imagined. Given this importance, understanding the size of a software system is a fundamental aspect of planning, managing, and delivering these essential tools.
Traditionally, measuring the size of a software system has been focused on metrics such as lines of code, story points, or even the number of modules. However, these measures tend to focus on the physical attributes of the software, without fully considering the knowledge required to develop and maintain such systems.
This raises the question - is there a more effective way to size software systems? What if we looked at software sizing from a different perspective - not just as a product composed of lines of code or features, but as a manifestation of the knowledge and learning required to build it?
Welcome to a new era of software sizing - a knowledge-centric approach that shifts the focus from the physical product to the intellectual process. This approach treats software as an embodiment of discovered knowledge, providing a fresh perspective that better captures the essence of software development.
In this article, we will delve into traditional software sizing methods, explore the concept of sizing software systems in bits of information, and illustrate the benefits of adopting a knowledge-centric approach. Through this exploration, we'll uncover a more nuanced and effective way to estimate software development project size, one that factors in the complexity of knowledge discovery and application in software development projects.
Join us as we navigate this innovative paradigm, exploring how it can revolutionize the way we plan, estimate, and manage software projects.
Traditional Methods for Software Sizing
In software development and project management, the concept of 'size' can be somewhat abstract and multifaceted. Traditional software sizing methods attempt to measure the size of a software system based on either quantitative aspects of the codebase or on visible attributes defined from an observable functionlity perspective.
Let's take a closer look at some of the most prevalent methods:
- Lines of Code (LOC): Perhaps the most intuitive method of software sizing, LOC simply counts the number of lines written in the codebase. This includes executable lines, declarations, and comments. While LOC is easy to measure, it has significant limitations. The measure is highly sensitive to coding style and language choice and doesn't adequately account for the complexity of the code.
- Function Points (FP): Introduced in the 1970s, function points measure software size by quantifying the functionality provided to the user, based on the user's perspective. FP considers inputs, outputs, inquiries, interfaces, and internal tables. However, the FP count can be subjective, varies across different teams, and does not correlate well with the complexity or the effort required for development.
- Story Points: Popular in agile development, story points measure the relative complexity of user stories. A user story with more story points is deemed more complex. The measure is abstract and relies heavily on team estimation sessions, which could be subject to bias or inaccuracy.
- Feature Points: Feature points extend the function point concept by adding a weighting factor for the algorithmic complexity of each feature. This helps to address some of the complexity-related issues with FPs but still misses the finer nuances of software development effort related to knowledge discovery and learning.
- Object Points: Object Points are used in object-oriented software systems. They measure the size based on the number of screens (user interfaces), reports, and components/modules in the software system. Like the others, this method tends to ignore the complexity of software systems and the effort involved in learning and problem-solving during development.
- Use Case Points (UCP): UCPs measure software size by counting and weighting use cases. They incorporate complexity factors, including the number of actors and scenarios. While UCPs provide a more nuanced view of software size, they still fall short in capturing the true complexity of the software system and the knowledge discovery process involved.
These traditional methods have undeniably served their purpose, providing a tangible basis for estimating effort, cost, and timeline. However, they don't adequately address the unique characteristics intrinsic to software development – the quintessence of which lies in the constant learning and knowledge acquisition process. Software development is not only about coding or creating functionalities, but it's also a journey of continual learning and knowledge discovery that developers undertake. This is the knowledge they didn't possess before embarking on the project and is essential to its successful completion. Traditional methods often overlook this critical aspect, resulting in an underestimation of effort and timeline, leading, in turn, to overruns and missed deadlines.
As we move towards more complex, knowledge-intensive software systems, it's time to rethink our approach to software sizing, focusing more on the knowledge discovery process. This shift in perspective forms the crux of the knowledge-centric approach to software sizing, which we will delve into in the next section.
Knowledge-Centric Approach to Software Sizing
When using a knowledge-centric approach the size of a software system is measured in bits of information. The 'size' is the total missing information acquired by the team through time about 'what' was developed and 'how' it was developed the 'what' for the successful delivery to the customer and users.
The missing information can be broadly categorized into two types:
- WHAT needs to be done (the objectives or requirements)
- HOW to accomplish the WHAT (the processes, methods, and techniques to fulfill these requirements).
Software system size is not absolute, but is context dependent because the same product or system specification given to two different teams each with a different level of team collaboration, client collaboration, technology expertise, domain expertise, and development process:. will result in two different system sizes. Based on your experience, you may find this conclusion aligns with the realities of software development.
Quantifying the size of a software system in terms of bits of information brings a new perspective that aligns with the knowledge-centric approach we've been discussing. This method focuses on measuring the 'knowledge gaps' or 'information missing' rather than physical lines of code or function points.
In essence, each component of the software system (a feature, a user story, or an epic) can be seen as a 'knowledge unit'. Initially, these knowledge units are filled with 'missing information' which corresponds to the knowledge that the development team needs to discover in order to implement the unit. For each knowledge unit, you can estimate the number of bits of missing information based on factors like complexity, uncertainty, novelty, etc. This size can be thought of as a measure of 'total Shannon entropy' for the knowledge unit[1]. The 'size' of the entire software system in bits can then be estimated as the sum of the bits of missing information for all knowledge units. This measure of size reflects the total amount of knowledge that needs to be discovered to complete the system development.
Consider the process of exploring a new city as an analogy. You start with a high-level map that outlines a few key neighborhoods, streets, or landmarks. In this scenario, the landmarks can be seen as the 'what' to see, and the paths you need to traverse to reach each landmark represent the 'how' to see the 'what'. Initially, your knowledge about these landmarks and routes is sparse - this is your 'missing information'. As you start your exploration, you may stumble upon new landmarks, thus expanding your 'what' and, as a result, increasing the total 'missing information'. The larger and more intricate the city, the more 'missing information' you need to uncover, which translates into more bits of information.
Just like in a software system, some areas of the city might be harder to understand or navigate than others. These areas would represent higher degrees of 'missing information,' mirroring the complexity or uncertainty of certain knowledge units. For instance, an ancient, meandering neighborhood with no street signs would possess a high volume of 'missing information', analogous to a complex feature with a high information entropy. Conversely, a well-planned, modern district with clear markings would have less 'missing information', similar to a simple, familiar feature in a software system.
Let's assume, as an example, that we are developing a software system for an online bookstore. We have several key features to implement, such as 'User Registration,' 'Book Search,' and 'Order Checkout.' Each of these features represents a 'knowledge unit' in our software system.
Initially, our development team may lack the exact knowledge of what the required features are and how to implement them, a gap that represents 'missing information.' This 'missing information' can be estimated in terms of the number of bits, providing a measure of the 'size' for each knowledge unit.
For instance, suppose the team is familiar with user registration systems, but the 'Book Search' feature requires integration with a new external database, and the 'Order Checkout' involves a complex payment processing system the team has never worked with before. In this scenario, 'User Registration' would have fewer bits of missing information, compared to 'Book Search' and 'Order Checkout.'
By estimating the bits of missing information for each feature, we can calculate the overall 'size' of the software system in bits. This estimate reflects the total amount of knowledge the team needs to discover to implement all features and complete the development.
This way of sizing a software system aligns with the knowledge-centric approach to software project management, emphasizing the discovery and application of knowledge as key factors in project complexity and completion time. It provides a new angle for project managers to consider when planning and executing software projects, focusing on the learning and problem-solving aspects rather than just coding and testing.
Knowledge-Centric Approach to Software Development Project Sizing
A system size is often referred to interchangeably as 'project size' because most of the time a new system is delivered in the context of a new project, even if the system is treated as a 'product' i.e. it is not a one-time effort but is continuously enhanced and enlarged. Project size could be seen as a broader concept that includes not only the 'system size' (the knowledge required for the software itself) but also additional knowledge related to project-specific requirements. This might include understanding stakeholder needs, compliance requirements, project management practices, team dynamics, and more.
In a knowledge-centric approach to software development, the concepts of 'system size', 'project size', 'project complexity', and 'system complexity' could be framed in terms of the volume of knowledge to be discovered or the amount of 'missing information'. Here's one possible way to structure these concepts:
- System Size: This can be defined as the total amount of knowledge that needs to be discovered or learned to fully understand the software system's functionality and behavior. It's essentially a measure of 'what' needs to be developed and 'how' it needs to be developed.
- Project Size: This could be seen as a broader concept that includes not only the 'system size' (the knowledge required for the software itself) but also additional knowledge related to project-specific requirements. This might include understanding stakeholder needs, compliance requirements, project management practices, team dynamics, and more.
- System Complexity: This would be a measure of the intricacy of the knowledge associated with the software system. Higher complexity could imply that the knowledge units are more interconnected, harder to discover, or exist in a higher state of uncertainty or volatility. This might correspond to the number of components, their interrelations, the novelty of the technology, and so on.
- Project Complexity: This goes beyond system complexity by also taking into account the complexity of the project environment. It includes factors such as the diversity of stakeholder needs, the level of innovation required, the proficiency of the team, the project's timescale, and so on. Higher project complexity would suggest a larger amount of diverse, interconnected, and perhaps volatile knowledge units to discover.
In this knowledge-centric view, 'system size' and 'system complexity' are primarily concerned with the knowledge necessary to build the software system itself, while 'project size' and 'project complexity' incorporate broader factors about the project environment and execution. However, it's important to recognize that there can be significant overlap and interaction between these concepts. A complex system can contribute to a complex project, and a large system will typically result in a large project, for example.
System complexity doesn't necessarily increase the system size directly, but it affects the understanding of the system size. A complex system often has a lot of interrelated parts and intricate structures which might not be fully understood at the onset of the project. This lack of understanding increases the amount of "missing information" to be discovered, which can lead to an increase in perceived system size.
Similarly, project complexity doesn't directly increase project size, but it can increase the uncertainty and thus the perceived project size. In a complex project, there might be many unknowns and unexpected obstacles that require additional knowledge acquisition. For example, the team might have to learn new technologies, understand complex business domains, or navigate complicated organizational structures. All of these factors can lead to an increase in the amount of missing information to be discovered, effectively increasing the perceived project size.
So in the context of a knowledge-centric approach, we can say that complexity indirectly affects size through the lens of the amount of "missing information" or knowledge to be discovered. It's also worth noting that the inverse can also be true: a larger system or project can add to its complexity because there's more information to manage and more opportunities for intricate relationships and unexpected challenges.
Benefits of the Knowledge-Centric Approach to Software Development Project Sizing
A knowledge-centric approach, which measures the size of a software development project in bits of missing information, focuses on the intellectual effort required. It takes into account the learning process and problem-solving activities, which are key aspects of software development. The measure of size as the sum of bits of missing information for all knowledge units not only estimates the physical dimensions but also encapsulates the intellectual complexity of the project.
When sizing a project in this way, each feature, user story, or epic can be seen as a unit of knowledge to be discovered. More complex or unfamiliar units will naturally have more missing information, i.e., more bits. As a result, they would require more effort and time to implement, directly impacting the project's estimated completion time.
This approach also accommodates for variations in team knowledge and experience. The same software specification given to two different teams, each with a different level of domain and technical knowledge, will result in different amounts of missing information, hence different project sizes. This consideration makes the knowledge-centric approach more adaptable and accurate compared to traditional methods.
By focusing on the missing information that needs to be discovered, this approach allows for a more effective prediction of project complexity and completion time. It acknowledges that software development is as much about discovering and applying new knowledge as it is about coding, testing, and deploying. Consequently, it provides a more holistic and realistic approach to software project estimation and management.
Practical Application
The knowledge-centric approach finds its most practical application in forecasting software project completion times. By charting the cumulative growth of knowledge discovered in reference projects, we can foresee the learning and problem-solving activities that will likely take place throughout the life cycle of a new project.
This practice of measuring cumulative knowledge growth is not confined to software development. It is prevalent in various domains, including scientometrics—the study of measuring and analyzing scientific literature and research activities.
The diagram below presents the growth of knowledge discovered, in bits, for a real project[2]. This is a tangible manifestation of the knowledge-centric approach in action, illustrating how it can be leveraged to predict project completion times.
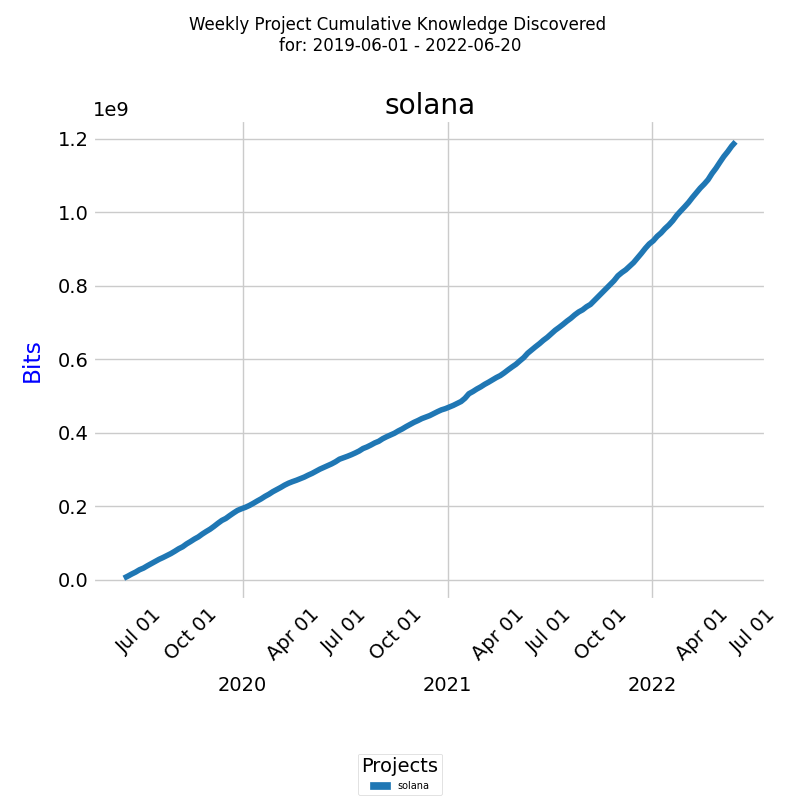
From the diagram, it's clear that the total knowledge discovered for the selected project, over the given time period, amounts to 1.2*109 bits or 1.2 terabits (Tbits). The blue line represents the cumulative growth of knowledge discovered, which directly correlates with the team's progress. By tracking this growth, project managers can estimate the amount of knowledge yet to be discovered and subsequently forecast the completion time of a new similar project, epitomizing the core premise of the knowledge-centric approach.
Conclusion
In conclusion, adopting a knowledge-centric approach to software development project sizing offers a more nuanced, realistic, and effective strategy for software project estimation and management. By recognizing the integral role of knowledge discovery in software development, we are better equipped to account for the intellectual complexity, learning curves, and dynamic problem-solving involved in these projects. This perspective places equal emphasis on coding and the underlying discovery and application of knowledge, thus painting a comprehensive picture of software development. Such an understanding ultimately fosters more accurate forecasting, better resource allocation, and a higher likelihood of project success. We encourage developers, project managers, and stakeholders to incorporate this knowledge-centric approach into their software development project sizing and management strategies for more effective and successful project delivery.
Works Cited
1. Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal. 1948;27(3):379-423. doi:10.1002/j.1538-7305.1948.tb01338.x
2. Solana
How to cite:
Bakardzhiev D.V. (2023) A Knowledge-Centric Approach to Sizing Software Systems in Bits of Information https://docs.kedehub.io/kede-manage/kede-manage/kede-software-sizing.html
Getting started


