Knowledge Discovery Efficiency (KEDE) and Ashby's Law of Requisite Variety
Abstract
We address Real-world applications of Ashby's Law by adopting Ashby's strict black-box perspective: only external behaviour is observable. First we define the multi-staged selection process of narrowing down and selecting the appropriate response from the set of alternative responses as the Knowledge Discovery Process. We then establish H(X|Y) as the knowledge to be discovered, which is the gap in internal variety that had to be compensated by selection. This quantifies how much disorder the regulator still permits and, conversely, how close the system comes to meeting Ashby's requisite-variety condition. In information-theoretic terms, perfect regulation requires H(X|Y) = 0. Then we quantify the knowledge to be discovered H(X|Y) based on the observable outcomes. Building on this result, we generalize Knowledge-Discovery Efficiency (KEDE) - scalar metric that quantifies how efficiently a system closes the gap between the variety demanded by its environment and the variety embodied in its prior knowledge. KEDE operationalises requisite variety when internal mechanisms remain opaque, offering a diagnostic tool for evaluating whether biological, artificial, or organisational systems absorb environmental complexity at a rate sufficient for effective regulation. Finally we present applications of KEDE in diverse domains, including typing the longest English word, measuring software development, testing intelligence, basketball game, assembling furniture, and speed of light in medium.
Introduction
The Law of Requisite Variety, formulated by W. Ross Ashby, states that for a system to effectively regulate its environment, it must have at least as much variety/complexity as its environment[1]. This principle is foundational in disciplines such as cybernetics, control theory, and machine learning.
The concept of requisite variety has since been applied across diverse domains, including organizational theory, ecology, and information systems. It underscores the necessity for systems to adapt to environmental complexity in order to maintain stability and achieve intended outcomes.
Real-world attempts to apply Ashby's Law of Requisite Variety face three persistent obstacles. (i) Combinatorial explosion: enumerating all relevant states of a system and its environment quickly becomes intractable, especially when hidden or unmeasured variables are present. (ii) Dual control dilemma: a regulator must simultaneously amplify its own control variety and attenuate external variety—an optimization that is delicate in multiscale, hierarchical, and time-varying settings such as digital ecosystems or military command structures. (iii) Resource constraints: limited data, computational power, and organisational capacity often preclude sophisticated control architectures. Existing remedies—markup-language state catalogues, iterative multidimensional sampling, and distributed self-organising controllers—mitigate but do not eliminate these limitations.
In section 2, we conduct a literature review of the primary challenges in applying Ashby's Law to real-world systems and propose a black-box solution: treating the system as a black box, observing the probability of successful outcomes to disturbances, and estimating the gap in its internal variety from that. In section 3, we present the Law of Requisite Variety in both its set-based formulation—covering the Table of Outcomes, requisite variety, goal revision, and behavioral rework—and its information-theoretic formulation, covering entropy, probabilistic success, residual variety bounds, response-equivalence, and the regulator's learned law of action. We conclude section 3 by introducing Knowledge To Be Discovered as the conditional entropy H(X|Y) that remains after available disturbance information is known. In section 4, we establish the Knowledge Discovery Process as the staged reduction of Knowledge To Be Discovered. We develop this in three layers: a set-based formulation of staged selection covering episodes, closures, and rule regulation; an information-theoretic formulation introducing the expected staged reduction of H(X|Y), action units, and response-class commitment; and learning across episodes, including comparable episodes, the learning axiom, and the posterior-becomes-prior rule. We also develop the operational ledger and the knowledge ledger, together with their window-level accounting measures and a three-loop feedback reading of all revisions. In section 5, we show how to quantify Knowledge To Be Discovered from observable outcomes alone, deriving the operational one-bit effective-depth estimator. and its relationship to the latent entropy. In section 6, we generalize the Knowledge-Discovery Efficiency (KEDE)—a scalar metric in [0,1] that quantifies how efficiently a system closes the gap between the variety demanded by its environment and the variety embodied in its prior knowledge. Finally, in section 7, we explore applications of KEDE across diverse domains including manual assembly, typing, software development, intelligence testing, sports performance, industrial assembly lines, and the speed of light in a medium, demonstrating its utility as a unified diagnostic tool for evaluating system performance and adaptability.
Core challenges in applying Ashby's Law to real systems
We conducted a literature review aimed at identifying the primary challenges and limitations associated with applying Ashby's Law in real-world systems.
A central challenge that emerges is the measurement of variety. In most of the reviewed literature, the concept of variety is either poorly defined or not explicitly measured, resulting in ambiguity and potential misinterpretation of the law's implications. Key obstacles to effective measurement include:
- The direct measurement of variety is fundamentally incomputable for all but the simplest systems [14].
- Hidden variables introduce uncertainty and complicate measurement efforts [15].
- Trade-offs often arise between variety at different scales [16].
- A combinatorial explosion occurs when attempting to enumerate all possible system states [15,16].
- Resource limitations constrain the feasibility of comprehensive measurement [20].
- Environmental complexity is frequently “unknowable,” preventing complete assessment [25].
- Most studies lack explicit or standardized methods for quantifying variety [14,17'-20,25,27].
- Existing approaches often lack rigorous quantitative validation [17].
Several measurement methods have been proposed, including:
- Markup language-based variety estimation [18],
- Iterative sampling techniques [21],
- Entropy and determinism metrics to evaluate communication complexity, where greater variety was correlated with improved effectiveness [22],
- Social network and cluster analysis to assess resilience [23], and
- Multiple Correspondence Analysis (MCA) for capturing organizational complexity [24].
In addition, a subset of studies estimate variety through observed performance rather than structural attributes. Notable examples include:
- Communication-based performance measures, employing determinism metrics to evaluate repeatable patterns in team behavior [22];
- Team performance assessments, using task-based surveys to evaluate an organization's risk-handling capabilities [23];
- Leadership behavior analysis, based on actual behavioral responses to simulated scenarios [26]; and
- Relative performance comparisons, assessing organizational effectiveness across contexts using perception-based rather than absolute metrics [14].
While these performance-based approaches provide practical insights, they often rely on subjective or indirect indicators of variety, which may introduce biases and limit their generalizability. For example, performance outcomes may fail to account for hidden variables or the underlying complexity of the system [15]. Moreover, these approaches remain underrepresented in the literature, where structural and theoretical analyses still dominate.
In summary, although numerous methods for measuring variety have been proposed, no single comprehensive or universally accepted solution has emerged. Quantification remains a persistent challenge in the application of Ashby's Law to complex real-world systems.
Solution
These challenges significantly hinder the practical application of Ashby's Law. Whether considering a human, an AI model, or an organization, we are typically limited to observing external behavior rather than internal mechanisms—unless we are able to "open the box."
Ashby himself emphasized that all real systems can be considered black boxes. He argued that while black boxes mimic the behavior of real objects, in practice, real objects are black boxes: we have always interacted with systems whose internal workings are, to some extent, unknown.
This leads to what Ashby termed the black box identification approach [2], which involves:
- Perturbing the system by applying external disturbances,
- Measuring the system's responses to these perturbations, and
- Inferring the internal variety or capacity from the observed input-outcome relationships.
In most practical scenarios, we are only able to observe the outcomes of a system. These observable outcomes can be used to infer bounds on the system's internal variety—specifically, the extent of variety it must possess or lack in order to exhibit the observed behavior.
We propose such an approach: to treat the system as a black box, observe the probability of successful outcomes to disturbances, and estimate the gap in its internal variety based on that. Let E denote the event that the system gives an response to disturbance D, and let R be the regulator's action. In information-theoretic terms, perfect regulation requires H(R|D) = 0[31]. Using our novel information-theoretic estimator, empirical estimates of P(E=1) are used to quantify H(R|D) in bits of information. This quantifies how much disorder the regulator still permits and, conversely, how close the system comes to meeting Ashby's requisite-variety condition.
The Law of Requisite Variety
For a system to effectively regulate its environment, it must have at least as much variety as its environment.
Set-based formulation
Regulation achieves a goal by selecting responses against disturbances.
is the essential-variable vector. The essential variables are the goal-relevant state components. is the value set of . The essential variables define the dimensions; their value sets define the coordinate domains of the essential-variable space , which is the set of all possible combinations of their values[29].
An essential state is one particular point in the essential-variable space, i.e. a tuple of values of these dimensions, e.g. .
It is assumed that the goal has already been determined: the acceptable essential states are given by an acceptable region in the essential-variable space. Thus, the goal is a region in a multidimensional essential-variable space .
Let D, R, and Z denote, respectively, the disturbance variable, regulatory-response variable, and outcome variable. Let their corresponding sets of possible values be , , and . Thus , , and are particular values.
In the general case, the outcome-value space may itself be multidimensional. Let be the outcome-variable vector. The outcome variables are the components used to describe the concrete or functional result produced by a disturbance-response pair. is the value set of . Thus the outcome-value space is .
An outcome-value is one particular point in the outcome-value space. In the multidimensional case, it has the form . In the Appendix we have an example of a typing task, where an outcome-value may record both the intended target position and the typed symbol: .
The number of outcome dimensions m need not equal the number of essential-variable dimensions n. The outcome-value space describes the result produced by the system, while the essential-variable space describes the goal-relevant state used to judge that result. The mapping from outcomes to essential-variable values will be introduced below.
The scalar outcome-value case is recovered when . In that special case, each outcome-value may be treated as an unstructured value. More generally, each table cell still contains one outcome-value, but that outcome-value may itself be internally structured as a tuple.
We use roman for the essential-variable vector and script for its value space. Likewise, we use roman for the outcome-variable vector and script for its value space.
The Table of Outcomes is the map
so that for each disturbance-value and response-value , the value is the outcome-value .
Thus the table T is two-dimensional in its indexing by disturbance-response pairs (d,r), while each cell-entry may be a scalar outcome-value or a structured outcome-vector. The scalar-outcome case is recovered when .
| T | R | ||||
|---|---|---|---|---|---|
| r₁ | r₂ | r₃ | ... | ||
| D | d₁ | z₁₁ | z₁₂ | z₁₃ | ... |
| d₂ | z₂₁ | z₂₂ | z₂₃ | ... | |
| d₃ | z₃₁ | z₃₂ | z₃₃ | ... | |
| d₄ | z₄₁ | z₄₂ | z₄₃ | ... | |
| ... | ... | ... | ... | ... | |
Two distinct disturbance-response pairs may yield the same outcome-value:
This means that repetition belongs to the mapping T, not to the set . A set contains each of its elements only once. So one should not say that contains repeated values. What repeats is the same outcome-value appearing as the image of multiple table-cells.
Correspondence between outcome-values and essential-variable values. The “outcomes” in the Table of Outcomes are simple outcome-values, without any implication of desirability. An outcome-value is a concrete or functional result of a disturbance-response pair. An essential-variable value is the goal-relevant state description used to judge whether the result falls inside or outside the acceptable region.
The correspondence between outcome-values and essential-variable values is therefore not automatic. It is part of the modeling frame of the regulatory problem. To use a function from outcomes to essential-variable values, the outcome-description must be specified at a level of detail sufficient to determine the relevant essential-variable value. In this article we assume that this has been done. Thus each outcome-value under the adopted description has a determinate associated essential-variable value.
so that . This means that the function is a modeling map from the outcome-description used in the table to the essential-variable description used for regulation. It should not be read as saying that every possible description of an outcome would automatically determine an essential-variable value. If the outcome-description were too coarse to determine the relevant essential-variable value, then would have to be replaced by a relation, a refinement of , or a probabilistic mapping.
The reduced, bijective, and many-to-one cases discussed below are therefore not alternatives to this modeling assumption. They are different ways in which the adopted outcome-description may correspond to the essential-variable description. In the reduced case, outcome-values already are essential-variable values. In the bijective case, outcome-values and essential-variable values are distinct descriptions but correspond one-for-one. In the many-to-one case, several finer-grained outcome-values correspond to the same essential-variable value.
Reduced correspondence. The special case is the reduced representation in which the table T directly contains values of the essential variables, i.e.
Bijective correspondence between outcome-values and essential-variable values. This is the case in which each relevant outcome-value maps to a unique essential-variable value, and each relevant essential-variable value is represented by exactly one outcome-value. In the bijective case, is one-to-one and onto between the relevant outcome-values and the relevant essential-variable values represented in the regulatory model, not bijective over the entire possible outcome and essential-variable spaces. Then and are conceptually distinct but informationally equivalent: with and every essential-variable value relevant to the regulatory model has exactly one corresponding . On this reading, may still be understood as the outcome-value space and as the essential-variable space, but every relevant distinction in outcomes is mirrored one-for-one at the level of the essential variables. This is the form used in later reformulations such as with an explicit bijection between the outcome-value variable and the essential variable E. In that literature Y corresponds to our outcome variable Z, or to the induced outcome variable generated through T. Aulin-Ahmavaara's formulation uses a one-to-one mapping between outcome Y and essential variable E, so our is a generalization of that case[31]. See the illustrative example in the Appendix.
Many-to-one correspondence between outcome-values and essential-variable values. This is the case in which multiple distinct outcome-values map to the same essential-variable value. Ashby says that a particular outcome can be treated “as unit with unit,” but “in another context, [it] may be analysed more finely.[1]” That means an outcome can be used as a single table-entry in the regulatory schema, even though in a more detailed analysis it may unfold into a whole trajectory, microstate, or process.[1] Then different outcome-values can collapse to the same essential-variable value: .
On this reading, contains finer-grained outcomes, while contains the coarser essential-variable values that matter for survival or goal-attainment. The many-to-one relation therefore expresses that several distinct outcome-states may be equivalent from the standpoint of regulation. Successful regulation is still judged at the level of the essential variables: distinct trajectory histories may all count as equally successful if they yield the same relevant value of and hence fall within the acceptable region . This is a refinement of Ashby's basic regulatory schema, but it is an added modeling layer[1]. See the illustrative example in the Appendix.
In this article formulas below are written in the general form. Most later calculations use the general -form; where individual outcome deletion/addition is interpreted literally, the reduced or bijective case is assumed unless stated otherwise.
Requisite variety
The regulator does not choose outcome-values directly. It selects a response-value in the presence of a disturbance-value, and thereby determines an outcome-value.
Strictly speaking, there may be many disturbance-values that are conceivable in the world but not part of the regulatory problem currently being modeled. Let denote the larger set of all conceivable disturbance-values. In the present formulation, however, we restrict attention to the disturbance-values under consideration in the regulatory problem. For notational economy, we write this context-restricted disturbance set simply as , where .
This restriction is part of the modeling frame, not an effect of regulation. It does not mean that the regulator has already reduced the disturbance variety. It means only that success is being evaluated over the disturbance-values included in the present regulatory problem. Thus, from this point onward, means the disturbance set under consideration.
In Ashby's table formulation, the “actual outcomes” is the rule-induced actual outcome-set selected from the possible outcome table by the regulator's response choices. They are actual in contrast to the full set of possible outcomes , not necessarily actual in the narrower historical sense of having occurred in a single observed run[1][8].
Let the regulator use a response rule
This induces the actual outcome map
and its image:
The image is the rule-induced actual outcome-set under the response rule . It contains the outcome-values selected from the possible outcome table when each disturbance-value under consideration is paired with the response chosen for it by the rule . In this Ashby-style sense, these are the rule-induced actual outcomes: actual relative to the regulator's response rule, as distinct from the full space of possible outcomes .
This should be distinguished from the historically realized outcome-set in one particular run. If only some disturbance-values actually occur, let be the historically realized disturbance subset. Then the historically realized outcome-set is
Thus is the possible outcome-value space; is the actual outcome-set over the modeled disturbance domain; and is the historically realized outcome-set in the actual case.
Successful regulation requires that the essential-variable values corresponding to all rule-induced actual outcomes lie in the acceptable region: for any
This is a universal rule-level success condition over the disturbance set under consideration. At a particular moment only one disturbance may occur, but the response rule is judged by what it would produce for every disturbance in the modeled set.
This set-based representation tracks which outcome-values can occur under the policy, but it does not track multiplicity, frequency, or probability. Its role here is to support a universal success condition over the disturbance set.
Equivalently, successful regulation requires that every disturbance-value under consideration be mapped, through the selected response rule, into an acceptable outcome-value:
Here, the acceptable outcome-set denotes the preimage of the set , not a two-sided inverse function. Also is a subset of , so it is at the outcome-value level.
This subset relation is the primary success condition. It says that every actual outcome produced under the response rule must lie in the acceptable outcome-set. Any variety inequality derived from it is only a necessary numerical consequence, not the defining criterion of success. In Ashby-style terms, regulation succeeds when the rule-induced actual outcomes remain within the goal subset[1].
In this subsection, V denotes count-variety: for any finite set , we define , the number of distinguishable values/states in under the adopted classification. The following count-variety statements assume that the relevant spaces have been discretized into distinguishable classes under the adopted modeling resolution. If is an interval in a continuous space, plain cardinality becomes unhelpful because many regions may have the same infinite cardinality. For continuous spaces, the same role would have to be played by a measure, entropy, or another explicitly chosen variety measure. Thus all formulas written with are cardinality statements. Therefore, at the level of variety, success implies the following necessary numerical bound:
Similarly, from we obtain the necessary bound
These variety inequalities are consequences of the subset condition. They are not, by themselves, equivalent to it: an actual outcome-set may have variety no greater than that of an acceptable set and still fail to be a subset of that set. So success is fundamentally a matter of set inclusion, while the variety inequalities are derived necessary conditions. They are not, by themselves, equivalent to it.
Under the reduced representation in which and , the outcome-values are already values of the essential variables, so the success condition reduces to
and therefore implies the numerical bound
This numerical compatibility condition is still only necessary, not sufficient. The decisive success criterion remains: .
Thus, in this set-based formulation, regulatory success is stated at the level of the rule-induced actual outcome-set , not at the level of a single actual outcome which is used to state success at a particular time.
A special finite-table lower-bound result. Under Ashby's finite table T idealization, a special count-variety consequence of the law of requisite variety can be stated precisely[1][8]. Suppose the table T has finitely many disturbance-values and response-values, and suppose that no response-column contains a repeated outcome-value. Equivalently, for every fixed response-value , the map is injective. Thus a single unchanged response-value cannot by itself collapse different disturbance-values into the same outcome-value.
Let the regulator select one response-value for each disturbance-value by a response rule . This selects one cell from each disturbance-row of the table and induces the actual outcome-set
The response rule may use only a subset of the available response repertoire. Define the used response-set as
Because no response-column contains a repeated outcome-value, any one outcome-value can appear among the selected cells at most once per used response-column. Since the rule uses response-columns, any one outcome-value can cover at most selected disturbance-rows. But the response rule selects one cell from each of the disturbance-rows. Assume is non-empty, so that is also finite and non-empty. Therefore the selected cells cannot collapse into fewer than the ceiling of disturbance-rows divided by used response-columns:
Since , we also have . Therefore the weaker repertoire-level lower bound is:
This is a finite-table, count-variety quotient analogue of the Ashby-style requisite-variety bound. It is not Ashby’s general entropy formulation. It is not derived from the goal-subset condition alone. It follows from the additional table assumption that no response-column already contains repeated outcome-values. If the table itself contains such repetitions, then some disturbance variety has already been collapsed by the table structure before the regulator's response rule is considered. In that case this quotient lower bound need not hold at the outcome-value level.
This is an outcome-value-level bound before applying . In the many-to-one case, may collapse several distinct outcome-values into one essential-variable value, so the same lower bound need not hold for unless is injective on the selected outcome-values.
The quotient bound is a lower bound on the variety of the actual outcome-set selected by the response rule. Successful regulation, however, is still defined by set inclusion, not by the quotient alone. The success condition remains:
Therefore a necessary outcome-level numerical compatibility condition for success is:
This condition is necessary, not sufficient. It says only that the acceptable outcome-set is numerically large enough to contain the unavoidable residual outcome variety. It does not guarantee that the table entries are arranged so that some response rule actually maps every disturbance-value into the acceptable outcome-set. Success remains a matter of the subset relation itself.
If one wants the numerical condition to count only outcome-values that are actually attainable from the table, define the table-image as
Then the attainable acceptable outcome-set is
Using this stricter attainable set gives the sharper necessary condition:
In the reduced representation, where and , the acceptable outcome-set is just the acceptable essential-variable region:
Therefore the necessary numerical condition becomes:
The same reduction holds in the bijective case, provided preserves cardinality on the relevant acceptable sets. In the many-to-one case, however, may be much larger than . Thus the outcome-level compatibility condition and the essential-variable-level compatibility condition coincide in the reduced or bijective case, but can diverge in the many-to-one case.
Outcome map induced by a response rule at time t
At time , let the regulator use the response rule
The induced actual outcome map is
where := for notational economy.
The acceptable outcome-set at time t is not chosen directly in ; it is induced by pulling back the acceptable essential-variable region along the outcome-to-essential-variable map .
Thus the acceptable outcome-set is the pullback, or preimage, of the acceptable essential-variable region. An outcome-value is acceptable at time t exactly when its associated essential-variable value lies in .
Successful regulation under the criterion prevailing at time means that the response rule maps every disturbance under consideration into the acceptable outcome-set for that time:
Equivalently,
Goal revision with fixed table and time-indexed acceptable outcomes
We consider a regulator acting against disturbances within a fixed system structure. The aim is to model the case in which the structure of the system does not change from time t1 to time t2, but the criterion of success does.
In this subsection, goal revision means a change in the acceptable region within a fixed modeling frame. The disturbance space , the response space , the possible outcome space , the essential-variable space , the table , and the outcome-to-essential-variable map remain fixed. Thus the same outcome-value keeps the same essential-variable interpretation. What changes is the acceptable region and therefore the acceptable outcome-set changes from to inside the same essential-variable space , not the meaning or dimensionality of the essential variables themselves.
If the goal revision changes which variables count as essential, or changes the level at which outcomes are mapped to essential-variable values, then or must also be revised; that would be a different modeling case.
This is goal revision within a fixed repertoire, not structural adaptation. That distinction is important because stronger Ashby-style adaptation involves change in the system's structure, organization, or available repertoire, not merely a different rule selected from the same fixed table[1].
In a higher-order system, revising the acceptable set may itself be part of a meta-regulatory process[57]. Here, goal revision is treated as an external change in the criterion of success, not as regulation by the fixed first-order regulator. It could be modeled as higher-order regulation in a larger adaptive system, but that is outside the fixed-table case considered here.
A change in the acceptable set is not yet a change in actual behavior. It is a change in the criterion by which behavior is judged. A behavioral change occurs only if the regulator changes its response rule from to . Such a change is required only when the old rule no longer maps the disturbances under consideration into the revised acceptable outcome-set.
Thus the transition from to first changes the criterion of success. This induces a change from to . The old response rule must then be tested against the revised acceptable outcome-set. If , then the old behavior remains successful under the new criterion. If not, regulation requires selecting a revised response rule such that . Goal revision is not itself regulation. Continued regulation after goal revision requires that some response rule — possibly the old one, possibly a revised one — maps the disturbances under consideration into the revised acceptable outcome-set.
We are therefore tracking acceptability at the level of outcome-values in , via the pullback along φ. Acceptability-status is time-indexed, while outcome-identity in is not. So the change is not that outcome-values disappear from the table. The change is that some fixed outcome-values in may cease to be acceptable, while others may become acceptable. That is why it is correct to time-index Oacc,t.
Before defining deletion and addition at the level of outcome-values, one qualification is needed. If acceptability is defined by pulling back the acceptable essential-variable region along φ, then acceptability is constant on the fibers of φ.
The set is the fiber of outcome-values that all correspond to the same essential-variable value . If , then all members of the same fiber have the same acceptability-status at time t.
When acceptability is defined by pullback from , acceptability cannot vary inside a fiber of φ. If two distinct outcome-values map to the same essential-variable value, they share the same acceptability-status at time t. Therefore, if the modeler wants two outcome-values in the same fiber to have different acceptability-statuses, then the map has collapsed a distinction that is relevant for regulation.
This is not a limitation of the set-theoretic construction; it is a consequence of the chosen level of description. If two outcome-values must be judged differently for purposes of regulation, then they cannot be treated as equivalent under the outcome-to-essential-variable map. In that case, is too coarse for the regulatory problem being modeled. The outcome-description must be refined, or the mapping must be replaced by a relation, a more detailed essential-variable space, or a probabilistic mapping.
Therefore, in the many-to-one case, deletion and addition of acceptable outcome-values is not truly individual. It happens fiber-wise. Because acceptability is defined by pulling back the acceptable essential-variable region along , one cannot remove one member of a fiber from the acceptable set while leaving another member of the same fiber acceptable.
Revision of acceptability: deletion, addition, and substitution within the acceptable outcome-set
With this interpretation, the notions of deletion, addition, and substitution are legitimate, provided they are understood as operations on the acceptable subset Oacc,t, not on the table T itself. So no outcome-value is deleted from the table T. Rather, some fixed outcome-values may lose or gain acceptability.
An outcome-value z is deleted from the acceptable set between t1 and t2 iff
This does not mean that z disappears from the table T. It means only that z, though still a possible outcome-value in T, is no longer acceptable under the revised goal.
These definitions concern changes in acceptability-status only. They do not imply that the regulator actually produces, stops producing, or replaces those outcome-values. Behavioral change is tracked separately by comparing and .
An outcome-value z is added to the acceptable set between t1 and t2 iff
In the minimal set-theoretic sense, a weak substitution occurs when one acceptable outcome loses acceptability and another gains acceptability between t1 and t2. That is, there exist b, c ∈ such that
Then one may say that b is removed from the acceptable set and c is admitted into it. This expresses substitution as coexistence of loss and gain; a stronger one-for-one replacement notion would require an additional correspondence between lost and gained elements.
It is useful to decompose the transition from t1 to t2 into three parts.
The persistently acceptable outcomes are
Equivalently, changes in acceptable outcome-values are the pullbacks of changes in acceptable essential-variable values. If , then the outcome-values that lose acceptability between t1 and t2 are:
The outcome-values that gain acceptability between t1 and t2 are:
This makes the fiber-wise character explicit. If several distinct outcome-values map to the same essential-variable value , then they enter or leave the acceptable outcome-set together. The reason is that acceptability is assigned first to essential-variable values and only then transferred back to outcome-values through .
Thus, in the reduced or bijective case, each relevant fiber contains exactly one outcome-value, so deletion and addition can be read directly at the level of individual outcome-values. In the many-to-one case, however, deletion and addition should be read as operations on whole fibers of .
Then
and the disjoint unions of the persistently acceptable outcomes and the outcomes that lose and gain acceptability are given by:
Thus deletion, addition, and substitution are operations on acceptability-status within the fixed outcome-space , not on the existence of values in T itself.
This models the attempt to maintain regulation under an externally revised criterion of success within a fixed repertoire. It is not structural adaptation in the stronger sense, because the regulator does not alter its own structure or acquire a new repertoire. Stronger adaptation enters only when the fixed repertoire is no longer sufficient and the system must reorganize itself.
Strict substitution
A strict substitution is stronger than the mere coexistence of loss and gain. Weak substitution says only that some outcome-values lose acceptability and some other outcome-values gain acceptability. Strict substitution says, in addition, that the model supplies a specified replacement correspondence between the lost and gained outcome-values.
Using the earlier definitions:
A strict substitution structure from t1 to t2 is an ordered triple
such that:
and the model supplies a specified bijection
where λ12 is not merely a bijection whose existence follows from equal cardinalities. It is part of the model. It specifies which lost acceptable outcome-value is treated as replaced by which newly acceptable outcome-value.
Thus,
means that the previously acceptable outcome-value b is replaced, under the revised criterion of success, by the newly acceptable outcome-value c.
Strict substitution is still a relation between acceptability-statuses. It says that the revised criterion treats newly acceptable outcome-value c as the specified replacement for previously acceptable outcome-value b. It does not, by itself, imply that the regulator has actually produced c as a behavioral replacement for b. That would require an additional closure event or a change in the response rule.
The existence of a bijection requires
but this equality is only a necessary cardinality condition. It does not determine which lost outcome-value corresponds to which gained outcome-value. The transition of acceptable sets determines only the lost set and the gained set. It does not, by itself, determine the replacement pairing.
Therefore, replacement is not objectively present in the set transition alone. Weak substitution is present in the set transition whenever loss and gain coexist. Strict substitution requires additional correspondence structure.
In the special one-for-one case, where exactly one outcome-value loses acceptability and exactly one outcome-value gains acceptability, strict substitution reduces to:
In that case there is only one possible bijection, so one may say that b is strictly substituted by c.
This defines strict substitution at the outcome-value level. In the many-to-one case, one may instead define strict substitution at the essential-variable level by pairing lost and gained elements of and . The outcome-level and essential-variable-level notions coincide in the reduced or bijective case. Strict substitution at the outcome-value level may fail in the many-to-one case even when strict substitution exists at the essential-variable level, because fibers may have unequal cardinalities.
Behavioral rework
The preceding definitions describe revision of acceptability-status. They do not yet describe behavioral rework. Behavioral rework concerns a change in the outcome-values actually selected by the regulator's response rule. Thus, an outcome-value is behaviorally removed between t1 and t2 iff:
It is behaviorally added iff:
Therefore, goal revision changes the criterion of success; behavioral rework changes the regulator's selected outcomes. The two are related but not identical. A goal revision may require no behavioral rework if the old response rule remains successful under the revised acceptable outcome-set.
Information-Theoretic Formulation
The set-based formulation specifies the regulatory problem in terms of value spaces, the Table of Outcomes, the outcome-to-essential-variable map, and the acceptable region. The information-theoretic formulation keeps that same structure and adds probability distributions over it. It does not introduce a different regulatory model; it measures uncertainty, variety, buffering, and knowledge over the same disturbance-values, response-values, outcome-values, and essential-variable values.
Random variables over the set-based regulatory geometry
At time t, let , , , and denote, respectively, the disturbance random variable, regulatory-response random variable, outcome-value random variable, and essential-state random variable. These random variables are functions into the value spaces introduced above:
Thus their realized values satisfy , , , and .
The disturbance distribution Pt(Dt) describes how probability mass is distributed over the disturbance-values under consideration. The regulator's response policy is represented by Pt(Rt | Dt). In the deterministic case, this policy reduces to a response rule:
meaning that Pt(Rt = r | Dt = d) = 1 exactly when r = ρt(d).
Given the Table of Outcomes T : 𝒟 × 𝓡 → 𝒵, the disturbance and response variables induce the outcome-value variable:
The corresponding essential-state variable is obtained by applying the outcome-to-essential-variable map:
Under the fixed-table assumption used here, the system transition is deterministic: once d and r are fixed, z = T(d,r) and e = φ(z) are fixed. A stochastic plant would require replacing the indicator terms below with conditional probability kernels.
Equivalently, the joint distribution is concentrated on tuples satisfying the structural constraints imposed by T and φ:
Thus the information-theoretic formulation measures uncertainty over the same regulatory geometry already defined in the set-based formulation. The Table of Outcomes determines which outcome-value is produced by a disturbance-response pair, and φ determines which essential-variable value is associated with that outcome-value.
Entropy, variety, and the outcome-to-essential-variable map
Shannon entropy, denoted by H, measures uncertainty over distinguishable values of a random variable. For a finite random variable X with distribution P(X), entropy is:
When all values in the finite support of X are equiprobable, entropy reduces to the logarithm of count-variety:
More generally, entropy is the probabilistic analogue of variety. It measures how much uncertainty remains about which distinguishable value of a variable will be realized.
Because Et = φ(Zt), the essential-state variable is a function of the outcome-value variable. Therefore:
More precisely:
In the reduced or bijective case, H(Zt|Et) = 0, so the outcome-value variable and the essential-state variable are informationally equivalent on the relevant support:
In the many-to-one case, φ collapses several distinct outcome-values into the same essential-variable value. Then outcome-level uncertainty may be greater than essential-variable uncertainty. Equality holds only when φ is one-to-one on the relevant outcome-values. This distinction matters because regulation is judged at the level of the essential variables, even though the Table of Outcomes produces outcome-values.
Probabilistic success and support-level success
The acceptable region at time t is the set:
The corresponding acceptable outcome-set is the pullback of that acceptable essential-variable region along φ:
Strict probabilistic success at time t means that the essential-state variable lies inside the acceptable region with probability one:
Equivalently, at the outcome-value level:
In discrete support notation, this is:
or equivalently:
This is the distribution-level probabilistic version of the set-based success condition. It checks the disturbance-values that have positive probability under the current disturbance distribution. If supp(Dt) = 𝒟, then in the deterministic rule-level case it reduces to the universal set-based condition that the rule-induced actual outcome-set lies inside the acceptable outcome-set. If supp(Dt) ⊂ 𝒟, then the probability-one condition is weaker: it guarantees success only over disturbance-values that have positive probability at time t.
For universal rule-level success over the whole modeled disturbance set, the policy must be successful for every disturbance-value under consideration. Here Pt(Rt|Dt=d) is treated as the regulator's policy kernel, defined for every modeled disturbance-value d ∈ 𝒟, not merely for disturbance-values with positive probability under the current disturbance distribution.
Define the acceptable concrete response-set for disturbance d as:
Then universal rule-level success requires:
In the deterministic case, this condition reduces to:
This distinction matters because probability-one success is a statement about the support of the current distribution, while universal set-based success is a statement about every disturbance-value included in the modeled regulatory problem.
Allowed residual variety
If the acceptable essential-variable region is finite, its maximum allowed essential-variable entropy is:
Strict probabilistic success implies the necessary entropy condition:
This entropy condition is necessary, not sufficient. A distribution can have low entropy while still placing probability mass outside the acceptable region. Successful regulation requires confinement within ηt, not merely low entropy.
Similarly, if the acceptable outcome-set is finite, its maximum allowed outcome-level entropy is:
Strict probabilistic success at the outcome-value level implies:
In the reduced representation, where 𝒵 = 𝓔 and φ = id𝓔, the acceptable outcome-set is just the acceptable essential-variable region, so hO,t = hη,t. In the many-to-one case, however, the outcome-level entropy allowance hO,t may be larger than the essential-variable entropy allowance hη,t, because the pullback may include whole fibers of φ back into acceptability.
Response-equivalence and regulatory ignorance
Aulin-Ahmavaara and Heylighen characterize the ignorance term H(R|D) at the level of disturbance, regulator action, and quality of regulation. They describe it as uncertainty about how to react correctly to a disturbance and how to use the available regulatory acts optimally — using "correctly" and "optimally" loosely as near-synonyms rather than as a deliberate two-level distinction. However, their prose does not fully fix the granularity of the response variable R. It leaves open whether the response denotes: (i) an equivalence class of concrete responses that achieve the same acceptable outcome, (ii) the exact concrete response emitted by the regulator, or (iii) the optimal response among several acceptable responses[29][31].
The term H(Rt|Dt) measures uncertainty over which concrete response-value the regulator will use after the disturbance is known. That is useful, but it can overcount ignorance if several concrete responses are equivalent for the adopted success criterion. Entropy only measures uncertainty over the variable supplied to it; it does not know which distinctions matter for regulation.
To avoid counting irrelevant implementation variation as ignorance, we introduce response-equivalence classes. “Response-equivalence” means that two concrete responses belong to the same response class if the model treats them as interchangeable for the regulatory purpose being analyzed. At the coarsest success-preserving granularity, two concrete responses are placed in different classes only if choosing between them can matter to whether the resulting outcome is acceptable under the adopted success criterion.
For a fixed time t, let gt : 𝓡 → 𝓧t map each concrete response-value to a response-equivalence class. Each element of 𝓧t is therefore a subset of 𝓡. The partition 𝓧t should be chosen at the coarsest granularity that still preserves distinctions relevant to the adopted valuation and success criterion. The response-class random variable is:
One natural acceptability-based response-equivalence requirement is:
That is, two concrete responses may be placed in the same class only if replacing one with the other never changes success or failure under the adopted regulatory criterion. This weaker version is enough when regulation only asks: Did the outcome fall inside the acceptable region?
If the model needs to preserve exact essential-variable values rather than merely acceptability-status, a stronger valuation-based response-equivalence requirement may be used:
The weaker success-equivalence relation is appropriate when only membership in the acceptable region matters. The stronger valuation-equivalence relation is appropriate when different acceptable essential-variable values must still be distinguished. If the modeler wants the coarsest possible partition, the corresponding implication can be strengthened to a biconditional. “Response-equivalence” is important because it determines what uncertainty counts as regulatory ignorance.
Using the acceptable concrete response-set 𝒜t(d) defined above, the corresponding acceptable response-class set is:
In words, a response-class is acceptable for disturbance d when every concrete response in that class is acceptable for d. If a proposed class contains both acceptable and unacceptable concrete responses, then the class is too coarse for the adopted success criterion and must be refined.
Regulator's learned law of action
The regulator's accumulated structure Mt is its learned law of action: its prior knowledge about disturbances, available responses, outcome consequences, and success-relevant distinctions. In the deterministic case, this learned structure may be represented as a response rule:
In the general case of learning and uncertainty, Mt induces a response policy:
This policy describes how probability mass is allocated across possible response-values or response-classes for each disturbance-value, given the regulator's current knowledge state. If the Table of Outcomes T is the fixed space of possibilities, then Mt is the learned structure that induces a probability distribution over possible paths through that table.
Across time, Mt need not remain fixed. Changes in Mt alter which disturbance-response pairs become more or less probable, and therefore how the system's realized trajectories are distributed over the Table of Outcomes. Successful learning shifts probability mass away from ineffective responses and toward responses that better compensate the same disturbances.
All probabilities, entropies, and mutual informations used to describe the regulator's knowledge state can therefore be read epistemically, relative to Mt. When that dependence matters, we write PMt and HMt. When it is clear from context, the subscript is suppressed.
When the regulator's response variation is both disturbance-specific and correct for the Table of Outcomes, Mt reduces residual outcome or essential-variable variety. However, correctness is still judged by the set-based success condition:
or, equivalently:
Knowledge To Be Discovered
Let Yt denote the disturbance information available to the regulator. In the simplest fully observed case, Yt = Dt. In a partially observed case, Yt may be only a signal, observation, or classification of the disturbance.
For a particular observation-value y, define the disturbance-values still possible under that observation as:
Then the acceptable response-class set under observation y is:
Thus, under partial observation, a response-class is safely acceptable only if it works for every disturbance-value still possible under the regulator's observation. If this intersection is empty, then no response-class is guaranteed to succeed under that observation without additional information, additional buffering, or a richer response repertoire.
If the regulatory problem is modeled as requiring a unique valuation-based response-equivalence class for each disturbance-value, let qt : 𝒟 → 𝓧t denote the target-class map. The required response-class random variable is then:
Under this unique-target assumption, the regulator's remaining epistemic ignorance after the available disturbance information is known is:
When the dependence on Mt is clear from context, this may be written more simply as H(X|Y).
In this article, H(X|Y) is called Knowledge To Be Discovered: the remaining uncertainty, after the available disturbance information is known, about which required target response-equivalence class must be fixed for successful regulation.
Knowledge To Be Discovered is defined by the conditional entropy of the required target class: H(Xt*|Yt). It is not generally defined by H(Xt|Yt), because Xt may describe the regulator's actual policy variation rather than the response-class that success requires, unless we explicitly assume:
That assumption is strong. It means the regulator’s actual response-class variable is already aligned with the required target-class variable. Without that alignment, H(Xt|Yt) can measure randomness, indecision, exploration, implementation variation, or even consistently wrong behavior — not necessarily knowledge still to be discovered. However, correctness is a separate matter. A regulator may be perfectly selective and still wrong. Therefore, Knowledge To Be Discovered must be paired with a success/misalignment condition if the model is to distinguish uncertain regulation from confidently wrong regulation.
In the more general set-valued case, where several response-classes are acceptable for the same disturbance or observation, Knowledge To Be Discovered is not a single conditional entropy unless the model adds a selection criterion that turns the acceptable set into a target-class variable.
The H(X|Y) should be used as Knowledge To Be Discovered only after the model specifies a selection criterion that makes one class the target. Otherwise, uncertainty among several equally acceptable response-classes is not necessarily regulatory ignorance. Successful regulation requires only that the class eventually fixed by the regulator lie inside the acceptable response-class set, not identification of one uniquely correct class:
This is the key distinction: uncertainty over concrete responses is not automatically ignorance. It becomes regulatory ignorance only when the unresolved distinction matters for achieving an acceptable outcome under the adopted success criterion.
If Xt is a quotient of the concrete response variable Rt, then Xt is determined by Rt. Therefore:
More explicitly, since Xt = gt(Rt):
The second term, H(Rt|Xt,Yt), is residual uncertainty over which concrete response inside the already-fixed response-equivalence class will be emitted. That residual uncertainty is not necessarily regulatory ignorance. It may simply be implementation variation.
For example, suppose the disturbance is “pay $10,” and both “use one $10 bill” and “use ten $1 bills” are equally acceptable from the valuation layer's point of view. These are different concrete response-values, but they belong to the same response-equivalence class if the adopted success criterion cares only that $10 is paid. In that model, uncertainty between those concrete responses should not increase Knowledge To Be Discovered.
If the environment later cares about speed, accounting policy, fraud risk, or change preservation, then “one $10 bill” and “ten $1 bills” may no longer be equivalent. They should then be separated into different response-equivalence classes. In that revised model, uncertainty over which bill combination to use is genuine lack of requisite knowledge.
Thus, Xt must be defined at the right granularity. If Xt is too fine, the model counts irrelevant implementation variation as ignorance. If Xt is too coarse, the model hides distinctions that matter for success. Knowledge To Be Discovered is meaningful only when the response-equivalence classes preserve exactly the distinctions required by the adopted regulatory criterion.
Therefore, response-equivalence is the bridge between the entropy formula and Ashby's regulatory success condition. Without it, H(X|Y) is merely uncertainty over a chosen response variable. With it, H(X|Y) is uncertainty over the response variable at the regulatory granularity being analyzed: the uncertainty that must still be resolved for successful regulation.
Knowledge To Be Discovered and effective regulatory knowledge
The preceding definition of Knowledge To Be Discovered is not separate from the mutual-information terms used in the Ashby-style formulation below. It is the complementary uncertainty term in the same entropy decomposition.
Under the unique-target assumption, Xt* is the response-equivalence class that must be fixed for successful regulation. The total uncertainty over required response-classes is:
The mutual-information term I(Xt*;Yt) measures how much the available observation reduces uncertainty about the required response-class. The conditional-entropy term H(Xt*|Yt) is Knowledge To Be Discovered: the remaining uncertainty about which response-class must be fixed.
Thus Knowledge To Be Discovered and effective regulatory knowledge are two sides of the same decomposition:
In the fully observed case, where Yt = Dt, this becomes:
This is the response-class version of Aulin-Ahmavaara's ignorance term. At the correct regulatory granularity, the effective knowledge available to the regulator is the part of required response-class variety already determined by the disturbance information. The Knowledge To Be Discovered is the part not yet determined.
Therefore, the later mutual-information term I(St;Dt) should be read as an effective regulatory-knowledge term only when St is defined at the same success-relevant granularity as the required response-class variable. In the unique-target case, this means setting St = Xt*. If St denotes concrete responses or some other granularity, the mutual-information term measures disturbance-response coupling, but not necessarily Knowledge To Be Discovered.
Ashby-style residual-variety bounds
The preceding success conditions are exact confinement conditions. A variety inequality is not the definition of success; it is a necessary numerical consequence under additional assumptions.
In the idealized finite-table case, where disturbances and responses are treated as distinguishable possibilities, the Ashby-style count-variety lower bound can be written as:
In logarithmic form, and ignoring the ceiling for the idealized entropy analogue, this becomes:
This expression should be read as an idealized lower-bound form, not as a general theorem about every possible Table of Outcomes. It assumes that disturbance variety is not already collapsed by the table structure except for any explicitly modeled buffering or passive absorption. If the table itself collapses several disturbance-values into the same outcome-value, then the lower bound must be modified to reflect that additional collapse.
The preceding subsection defined Knowledge To Be Discovered at the level of the required response-equivalence class. The Ashby-style residual-variety bound can now be written using a general response variable St, where St is the response variable at the regulatory granularity being analyzed. If concrete response-values are relevant, then St = Rt. If response-equivalence classes are the relevant units, two cases must be distinguished. If St denotes the actual response-class emitted by the regulator, then St = Xt. If St denotes the required target response-class, then St = Xt*. Thus St is not a new kind of response; it is a placeholder for the response-level at which regulatory knowledge and residual variety are being measured.
Under the same idealizing assumptions as the finite-table quotient argument — no unmodeled table collapse except buffering K, a response variable St defined at the same regulatory granularity as the outcome variable being bounded, and correct disturbance-specific compensation — the following Shannon-style residual-variety analogue may be written:
Here [a]+ := max(a,0), since residual entropy cannot be negative. The term K denotes buffering capacity: disturbance variety absorbed passively before active regulation is required. This equation should be read as an information-theoretic analogue of Ashby's finite-table lower-bound argument under the stated idealizing assumptions.
Since:
the same bound can be written compactly as:
The mutual information I(St;Dt) measures how much the regulator's response variable, at the chosen regulatory granularity, is coupled to disturbance variation.
This is a measure of disturbance-specific response selection at the regulatory granularity being analyzed. By itself, however, it is not a guarantee of correctness. A response can be strongly coupled to a disturbance and still be the wrong response for the Table of Outcomes. Under the additional assumption that the coupling maps disturbances to appropriate compensating responses, it can be interpreted as requisite regulatory knowledge.
The outcome-level residual-variety bound can therefore be written as:
Combining this lower bound with the allowed outcome-level residual variety gives the following necessary feasibility condition for strict success:
In the reduced or bijective case, where the acceptable outcome-set and the acceptable essential-variable region have the same relevant variety, this becomes:
Expanded, this is:
If this necessary condition fails under the stated assumptions, strict success is impossible. If it holds, success is still not guaranteed; the response mapping must still be appropriate for the actual Table of Outcomes. The decisive success condition remains the confinement condition:
In the many-to-one case, the outcome-level and essential-variable-level statements must be kept distinct. A lower bound on H(Zt) does not automatically imply the same lower bound on H(Et), because φ may collapse outcome distinctions that are irrelevant at the essential-variable level. The safer formulation is therefore to write the bound first for Zt and then relate Zt to Et through Et = φ(Zt).
Point regulation
In the special case of point regulation, the acceptable region contains only one essential-variable state:
Under the reduced or bijective representation, the necessary feasibility condition becomes:
Equivalently:
In the ideal best-opportunity case, where buffering is ignored, the response policy is deterministic at the relevant regulatory granularity, and the response mapping is correct, this reduces to:
This should be read as an optimal-control limit, not as a blanket claim that every control problem is solved whenever response entropy is at least as large as disturbance entropy. The response mapping must also select the right response-values or response-classes for the actual Table of Outcomes, so that the induced outcome-values fall inside the acceptable outcome-set.
The deterministic-policy assumption means that the regulator's response variable at the chosen regulatory granularity is fully determined by the disturbance: H(St|Dt) = 0. This represents complete requisite knowledge only under the additional assumption that the learned response mapping sends each disturbance to an appropriate regulatory act. A regulator can deterministically choose the wrong response; therefore, zero conditional entropy alone does not prove correct regulation.
Successful essential-variable outcomes do not depend solely on the amount of response variety available to a regulator. The system must also be able to select the appropriate response for the given disturbance. Effective compensation of disturbances requires that the system possess a mapping from disturbances to appropriate responses within its repertoire. The absence or incompleteness of such knowledge can be represented by the conditional entropy H(St|Dt) only when St denotes the required response-class variable, or when the actual response variable is assumed to be aligned with the correct target mapping. Otherwise, zero conditional entropy means only that the response is determined by the disturbance; it does not by itself mean that the selected response is correct.
In other words, H(St | Dt) measures how much uncertainty remains about the regulator's response at the chosen regulatory granularity after the disturbance is known. Under the regulatory correctness assumption, this uncertainty corresponds to lack of requisite knowledge. Merely increasing response variety is therefore not sufficient. It must be complemented by a corresponding increase in selectivity: a reduction in H(St | Dt), i.e. an increase in knowledge. This requirement may be called the law of requisite knowledge[29].
The larger H(St | Dt) is, the less selectively the regulator's actions are determined by the disturbance. Under the assumption that each disturbance requires a limited set of appropriate responses at the chosen regulatory granularity, this increases the risk of selecting an ineffective response. Therefore, the term H(St | Dt) has a plus sign in the inequality: more uncertainty about how to respond increases the lower bound on residual outcome or essential-variable variety[54].
The information-theoretic formulation therefore does not replace the set-based success condition. It measures the uncertainty, variety, buffering, and knowledge involved in satisfying that condition. The set-based section gives the geometry of the regulatory problem; the information-theoretic section puts probability mass over that same geometry and measures the remaining uncertainty in bits.
Knowledge Discovery Process
The process of selection may be either more or less spread out in time. In particular, it may take place in discrete stages. What is fundamental quantitatively is that the overall selection achieved cannot be more than the sum (if measured logarithmically) of the separate selections. (Selection is measured by the fall in variety.) 13/17[2]
Ashby's selection in design and regulation share the same abstract selection schema: both reduce a space of possible alternatives by applying constraints, tests, rules, observations, or feedback. In regulation, however, the regulator does not select an outcome-value directly. It selects a response-value in the presence of a disturbance-value; the Table of Outcomes then determines the resulting outcome-value, and the outcome-to-essential-variable map determines whether that outcome is acceptable.
Importantly, so far we assumed that the regulator selects a response-value to a given disturbance-value in a single step. However, in many real-world regulatory problems, the regulator does not select a response-value in a single step. Instead, the regulator may select a response-value in stages, where each stage of selection may depend on the disturbance-value and on the response-values selected in previous stages. For example, a regulator may first select a coarse response-value, and then refine that coarse response-value in subsequent stages of selection. To capture this staged selection we now add time to the notation to indicate that the candidate response-sets are generated by a process of selection that unfolds over time.
Throughout this subsection, the index denotes the staged selection trace index at which the disturbance, knowledge state, acceptable region, and committed response are evaluated. It does not index the internal stages of the staged selection trace. The internal stages of a staged selection trace are indexed by . Thus a staged selection trace at time may contain several internal selection stages, but those stages are represented by the stage index , not by changing the external selection trace time index.
Unless explicitly stated otherwise, the acceptable region and the knowledge state are treated as the regulatory frame for the selection trace indexed by .
Set-based Formulation of Staged Selection
Using the set-based formulation above, for a disturbance-value and a response-value , the outcome-value is . The corresponding essential-variable value is . At time , this response is successful exactly when that essential-variable value lies in the acceptable region .
Equivalently, the acceptable outcome-set at time is the pullback of the acceptable essential-variable region:
For a given disturbance-value , define the acceptable response-set at time as:
This is just the pullback of the acceptable outcome-set through the row of the table T corresponding to disturbance d.
Equivalently:
The set contains exactly those response-values that would produce an acceptable outcome-value for the disturbance-value under the criterion of success prevailing at time .
We can now define the set-based staged selection trace as the nested reduction of candidate response-values for a realized disturbance-value. For a particular disturbance-value , let
be a nested sequence of candidate response-sets. Here, is the initial set of response-values available or considered for disturbance . Each stage applies a constraint, observation, test, rule, model, or feedback signal that removes response-values no longer admissible under the current regulatory problem.
The set-based trace is strongly successful when the remaining candidate response-values are all acceptable:
In the limiting case, the process fixes a single acceptable response-value:
Thus, the set-based staged selection trace is the staged reduction of candidate responses until the regulator can commit a response-value that maps the present disturbance into the acceptable outcome-set. The candidate response-set represents the remaining support of response-values still admissible after stage for the realized disturbance-value . This is a support-level description. It records which response-values remain possible.
Rule regulation
The rule-level version is obtained by applying the same idea to response rules rather than individual responses. Let be the set of possible response rules .
For a rule , define its induced outcome map by and its image over the modeled disturbance set by
At a particular moment, the regulator may face one realized disturbance-value. But a response rule is judged by what it would produce for every disturbance-value in the modeled disturbance set .
Define the successful rule-set at time as:
The rule-level condition is a universal guarantee over the modeled disturbance set. The episode-level condition is a pointwise condition for one realized disturbance
Equivalently:
This means a rule succeeds only if it produces acceptable outcomes for every modeled disturbance.
A rule-level staged selection trace is then a nested sequence of candidate rule-sets:
The process succeeds at the rule level when the remaining candidate rules are successful:
In the limiting case, the process fixes a single successful response rule:
This rule-level formulation is the universal version of the pointwise acceptable-response condition. Equivalently, a rule is successful when, for every modeled disturbance-value , it selects a response-value in .
Therefore, staged response selection is not a process outside regulation. At the set level, it is the nested narrowing of candidate responses or candidate response rules over the disturbance-values under consideration
Episodes and Closures
The set-based staged selection trace, an episode, and a closure describe three different aspects of the same regulatory event. The set-based staged selection trace is the nested reduction of candidate response-values for a realized disturbance-value. An episode is one realized run of that trace. A closure is the realized outcome-value produced when the episode terminates in a committed response-value.
For a selection trace at time , suppose the realized disturbance-value is . An episode at time is the realized set-based staged selection trace initiated for that disturbance-value. The staged candidate trace begins with an initial candidate response-set and proceeds through a sequence of internal staged reductions:
Since t is fixed, we suppress the time index and write instead of for readability.
The selection process terminates when the regulator commits a response-value . This commitment terminates the realized staged selection trace for that episode. The committed response-value then produces the realized outcome-value:
Thus, a closed episode can be represented by the formal tuple:
The closure is what closes the episode : the punctual act, committed at time , at which the regulator fixes the response and ends the episode's staged selection. It is the closure act, not its outcome-value, that individuates one counted closure unit.
The closure act produces a realized outcome-value through the Table of Outcomes, realized at time :
The commitment and the outcome need not coincide in time. The half-open interval between them,
carries no response-relevant discrimination and no further commitment; it is booked as feedback. The closure unit is anchored and charged at , while the closure event is recorded at , when is realized.
An acceptable closure is a closure whose realized outcome-value belongs to the acceptable outcome-set prevailing at the outcome time :
Therefore, there are two different success conditions that should not be confused. A strongly successful staged selection trace terminates with a remaining candidate response-set containing only acceptable responses:
In that case, any response-value selected from the final candidate set will produce an acceptable closure.
The two conditions are equivalent, since ; the right-hand form is the one used by the survival and invalidation accounting below. Because acceptability is a property of the outcome-value while counting is a property of the act, two distinct closure acts that produce the same outcome-value remain two counted closures.
A realized successful episode requires only that the response-value actually committed by the regulator be acceptable:
Equivalently:
Equivalently, the episode has an acceptable closure exactly when the essential-variable value induced by the realized outcome lies inside the acceptable region:
The strong condition guarantees successful closure before final commitment. The realized condition judges the episode after the committed response has produced its outcome. Therefore, episode closure is defined at the outcome layer. It records that the regulator has committed a response-value and that this commitment has produced a realized outcome-value. Acceptable closure adds the further condition that the realized outcome-value is acceptable under the goal criterion prevailing at time .
This distinction matters because response commitment and acceptable closure are not identical. A regulator may commit a response-value and still fail to produce an acceptable outcome-value. Conversely, an acceptable closure does not require that only one acceptable response-value was possible. Multiple distinct response-values may map the same disturbance-value into the acceptable outcome-set.
At the set level, staged selection is the process by which a regulator narrows candidate response-values until it can commit a response. An episode is one realized run of that staged selection trace. The episode closes when that committed response, together with the disturbance-value, produces a realized outcome-value. The closure is acceptable when that outcome lies in the acceptable outcome-set . For an acceptable closure:
The set-based staged selection trace does not by itself produce an outcome-value. It narrows the candidate response-set until the regulator can commit a response-value. The Table of Outcomes then maps that committed response-value, together with the disturbance-value, into a realized outcome-value. The episode has an acceptable closure exactly when that realized outcome-value belongs to the acceptable outcome-set prevailing at the time of closure.
Action-unit protocols
The staged candidate trace can be generated by an ordered action-unit protocol. For the episode indexed by , let
denote the realized physical action-unit protocol inside that episode. Each is the concrete action-unit token that occurs at internal stage : a test, observation, constraint application, sensor reading, feedback step, model application, partial execution, or other discriminating operation performed at internal stage . The action unit may be externally visible or hidden from the observer, but it is treated as part of the realized physical process.
The protocol is defined extensionally as the physical trace that occurs in the episode. This definition does not specify how the regulator chooses the action units, nor does it require the observer to identify the regulator's internal rule for selecting them. It only records that the episode contains an ordered sequence of physical action units. The formalism does not require a model of how the regulator selected that action unit. The action unit may have been fixed in advance, selected adaptively, or generated by an unobserved mechanism. Once it occurs in the realized trace, it is treated as the action unit for that stage.
At the set level, each physical action unit induces an update on the live candidate response-set. Let
be the set-update operator induced by the physical action unit . The update is eliminative or non-expansive:
Thus an action unit may remove candidate response-values, or it may leave the candidate set unchanged. The latter case represents a physical action unit that occurs but produces no set-level narrowing.
For a realized disturbance-value , define the candidate response-set after stage by:
and, for ,
The resulting set-based staged selection trace is therefore:
The trace is strongly successful when the final candidate response-set is non-empty and every remaining candidate response-value is acceptable for the realized disturbance-value:
The protocol contains only the internal physical action units of staged selection. The terminal commitment or emission of a response-value is a separate closure event, denoted:
When the regulator closes the episode, it commits a response-value from the final live candidate set:
In the limiting case, the staged selection trace fixes a single response-value:
This is a purely set-based and physical description. It records the realized action-unit protocol and the corresponding reduction of candidate response-values. It does not yet introduce informational variables associated with the action units. Those informational variables are introduced only in the information-theoretic formulation, where the physical action-unit trace is interpreted as inducing epistemic distinctions under the knowledge state .
Count-Variety Selection
The set-based formulation above defines the episode, the staged selection trace, and the closure. It records which candidate response-values or response rules remain possible after each stage. This is a support-level account. It can be given a logarithmic count-variety interpretation in the finite equiprobable case, but it does not yet define Knowledge To Be Discovered. Knowledge To Be Discovered requires a probability distribution over the required response-equivalence class and is therefore introduced in the information-theoretic formulation.
For finite equiprobable sets, Ashby[13/15 [2]] measures the amount of selection in bits as:
In the present formulation, the “before” and “after” varieties are the cardinalities of explicitly defined candidate sets. For finite candidate response-sets, the count-variety selection achieved at stage is:
This expression assumes that the remaining alternatives are being counted as distinguishable candidate response-values under the adopted modeling resolution i.e. is a concrete-level quantity rather than an class-level quantity. It measures support reduction, not probability-weighted uncertainty reduction. For the present set-based formulation, no probability distribution over is required.
The total count-variety selection achieved over a nested staged process is therefore:
This additive form is valid when the stages are nested refinements of the candidate set. Each stage must reduce the currently remaining alternatives, not independently recount the original space. If two stages constrain the same distinction in overlapping ways, the second stage's contribution must be counted relative to the alternatives that survived the first stage.
For finite equiprobable rule-sets, the corresponding rule-level count-variety selection at stage is:
And the total rule-level count-variety selection is:
This bridge establishes the count-variety special case. In the finite equiprobable case, and when selection operates purely by eliminating alternatives, logarithmic cardinality reduction coincides with entropy reduction. The information-theoretic formulation generalizes beyond that case by allowing non-uniform probabilities and probability redistribution among surviving candidates. In that formulation, the object being reduced is not merely the candidate set, but the regulator's Knowledge To Be Discovered: the conditional entropy of the required response-equivalence class.
Information-Theoretic Formulation of Staged Selection
What the Information-Theoretic Model Adds
The information-theoretic formulation does not redefine an episode. An episode remains the realized set-based regulatory event defined above. What this subsection adds is a probability model over that episode.
The set-based formulation records the realized regulatory trace: a disturbance occurs, the regulator narrows candidate responses, fixes a response class, emits a concrete response, and produces a closure through the Table of Outcomes. The information-theoretic formulation measures how much expected epistemic uncertainty is removed during that staged process.
A realized episode has an associated conditioning path: Y = y, U1 = u1, ..., Uk = uk. The Knowledge Discovery Process is the staged reduction of conditional entropy HMt(X|Y) about the required response-equivalence class X . This entropy is the Knowledge To Be Discovered, measured in bits.
The organizing distinction is: the episode is the realized set-based regulatory event; the conditioning path is the information-theoretic path through that episode; the KTD quantities are expected uncertainty measures under the regulator's knowledge state; and the closure is the outcome-value produced after final response commitment.
Notation and Modeling Assumptions
In this subsection, D denotes the actual disturbance-value that enters the Table of Outcomes, while Y denotes the disturbance information available to the regulator. In the fully observed case, Y = D. In the partially observed case, Y may be a signal, observation, classification, or task condition that leaves several actual disturbance-values possible.
Unless otherwise stated, X denotes the required response-equivalence class at the regulatory granularity being analyzed. In the unique-target case, this is the variable previously denoted Xt*. Thus X is not merely the regulator's actual response-class variation; it is the target response-class variable whose value must be fixed for successful regulation.
If several response-classes are equally acceptable, then uncertainty among those equally acceptable classes is not automatically Knowledge To Be Discovered. In that case, H(X|Y) should be interpreted as Knowledge To Be Discovered only if the model supplies a further selection criterion that turns the acceptable set into a target-class variable. Otherwise, residual uncertainty among equally acceptable response-classes is not regulatory ignorance at the granularity being analyzed.
The regulator's knowledge state is denoted by Mt. All probabilities, entropies, and mutual informations in this subsection are evaluated relative to the epistemic distribution induced by Mt. When that dependence matters, it is written explicitly as PMt, HMt, and IMt.
As in the set-based episode definition, the episode index t is fixed in this subsection. The response-equivalence map gt : 𝓡 → 𝓧t, the acceptable region ηt, and the knowledge state Mt are evaluated at the same episode index.
| Role | Symbol | Meaning in this subsection |
|---|---|---|
| Actual disturbance | D | The disturbance-value that combines with the final concrete response in the Table of Outcomes. |
| Available disturbance information | Y | The observation, signal, classification, or task condition available to the regulator. |
| Required response-equivalence class | X | The response class still unresolved for the regulator after observing Y. |
| Knowledge state | Mt | The epistemic state relative to which probabilities, entropies, and mutual informations are evaluated. |
| Action unit | qi | The operation performed at stage i. |
| Selection signal | Ui | The information-bearing result of action unit qi. |
| Actually fixed response class | X̂k | The response class selected by the regulator after k stages. |
| Concrete final response | Rfinal | A concrete response emitted from the fixed response class. |
| Outcome | Z = T(D,Rfinal) | The outcome produced after final response commitment. |
Staged Action Units and Realized Signals
Within an episode indexed by , the external regulatory frame is fixed: the knowledge state is , the acceptable region is , and the realized disturbance-value is . The internal stages of the episode are indexed by .
The episode-level action-unit protocol is denoted by . Its individual action units are denoted by . Let the action-unit prefix through stage be:
The observable result produced by action unit is denoted by , representing the epistemic signal made available by that unit under knowledge state . Let the corresponding realized signal prefix be:
The result , not the mere occurrence of the action unit, is the information-bearing signal associated with the physical action unit . On a realized episode path, and . Thus the action unit specifies the discriminating operation, while the realized signal selects which candidate responses remain compatible with the realized episode path.
This ensures a conceptual separation between the action unit and the realized signal. The protocol structures the episode. The action unit specifies a discriminating operation. The signal is the realized information-bearing result. The candidate-set update is the support-level consequence. Entropy reduction is the information-theoretic measure of how much uncertainty about the required response-equivalence class has been removed.
The action-unit protocol is treated as the realized physical enactment of the regulator's learned law of action under the knowledge state . The protocol may be fixed, dynamic, or adaptive. However, its adaptivity is governed by the law of action already contained in and by the episode history already represented in and the prior realized signals . Therefore, is not treated as an additional information-bearing signal about . It is the physical action-unit token that determines which signal map is applied at stage . The informational update is carried by the realized signal , not by conditioning on the action-unit token itself.
We assume the selected action protocol is fixed in advance or is a deterministic function of information already contained in Y under the frame Mt, That means: knowing the physical protocol tells us nothing about X beyond what Y=y already tells us, thus conditioning on adds no further information about X.
Therefore, after conditioning on the initial observation and realized signals, the protocol path adds no further information about the required response-equivalence class:
Equivalently:
Expected Staged Reduction of Knowledge To Be Discovered
The initial Knowledge To Be Discovered is the regulator's remaining epistemic uncertainty, under , about which required response-equivalence class must be fixed after the available disturbance information is known:
Each information-bearing signal Ui conditions that uncertainty further. After stages, the expected residual Knowledge To Be Discovered under the selected action-unit protocol is:
Equivalently, the residual Knowledge To Be Discovered after i stages is the initial Knowledge To Be Discovered minus the information gained from the first i selection signals:
A Knowledge Discovery Process is the sequence:
The expected reduction achieved by stage i is the difference between the residual Knowledge To Be Discovered before and after that stage:
The total expected selection achieved over all k stages is:
Shannon's chain rule for mutual information gives the operational decomposition of that total reduction:
The chain-rule identity holds regardless of dependence among the signals U1, ..., Uk. It does not require the stage signals to be independent or conditionally independent. Dependence among stages is handled by conditioning each stage-wise term on the earlier signal-values.
Therefore the per-stage contributions must be conditional and incremental. If stages share information or impose overlapping constraints, summing their marginal reductions I(X;Ui|Y) can overcount. The chain-rule decomposition avoids that overcounting by crediting each stage only for the reduction of residual uncertainty left by previous stages.
Realized Conditioning Path Inside One Episode
The quantities KTDi are expected conditional entropies under Mt. A realized episode, however, follows one concrete conditioning path: explicitly layered on top of the physical protocol . After the signal-values are observed, the regulator's posterior uncertainty is represented by conditioning on those realized values.
For a realized episode, let the regulator's posterior distribution over required response-equivalence classes before stage i be:
After observing Ui = ui, the posterior becomes:
The realized entropy-based selection measure tracks the probability-weighted change in uncertainty:
In a realized episode, σient may be positive, zero, or negative. It is positive when the observed signal concentrates probability mass, negative when the signal makes the posterior more diffuse, and zero when the entropy is unchanged. The non-negativity claim applies only in expectation.
For a fixed episode prefix Y = y, U<i = u<i, the conditional expectation of the realized entropy change is:
Fully averaged over Y and the previous signal-values, this gives:
At the terminal point of the realized conditioning path, the realized Knowledge To Be Discovered is the posterior entropy left after the actual signal-values have been observed:
The realized reduction in Knowledge To Be Discovered along that path is therefore:
In the unique-target case, if the realized conditioning path makes the required response-equivalence class posteriorly certain, then:
In that special case, the realized conditioning path has removed all of the initial Knowledge To Be Discovered for that episode:
This terminal quantity is still a posterior uncertainty measure, not yet a success condition. Zero terminal realized Knowledge To Be Discovered means that the required response-equivalence class has become identifiable under the model. Successful regulation additionally requires that the class actually fixed by the regulator be the required class.
Bridge to the Set-Based Candidate Trace
The set-based staged selection trace introduced above is naturally indexed by the realized disturbance-value. That trace is an ex post description of what happened in the episode. For a realized disturbance-value , write the actual response-candidate trace as:
This actual trace is disturbance-indexed. It records the nested response-values that remain compatible with the realized disturbance and the realized physical action-unit path. However, in a partially observed regulatory episode, the regulator does not generally condition on the realized disturbance-value itself. It conditions on the observation available at the start of the episode and on the realized action-unit and signal history. Therefore, the information-theoretic bridge must use an epistemic candidate trace.
The regulator's information state after stage is . The realized action-unit path is protocol context: it identifies which discriminating operations were applied. It is not, under the default protocol assumption, an additional information-bearing signal about .
For an information state , write the epistemic response-candidate set as:
This set contains the response-values still live from the regulator's point of view after the observed information path. The actual trace answers the ex post question, “Which responses remained compatible with the realized disturbance?” The epistemic trace answers the regulatory question, “Which responses remain possible under the information currently available to the regulator?” The two traces coincide only in the fully observed case, where the initial observation fixes the disturbance-value.
Bridge Lemma: epistemic support and terminal real KTD
Let be the knowledge state governing the episode. Let denote the required response-equivalence class. Let map each response-value to its response-equivalence class under the regulatory frame at time . The epistemic class-candidate set induced by the response-candidate set is:
The bridge condition is that this induced class-candidate set equals the probabilistic support of the required response-equivalence class under the same information state:
Define the terminal real Knowledge To Be Discovered after the realized protocol and signal history as:
Under the bridge condition, terminal real KTD is zero exactly when the terminal epistemic trace leaves only one required response-equivalence class possible:
Equivalently, if the terminal epistemic response-candidate set may still contain several response-values, terminal real KTD is nevertheless zero whenever all those response-values belong to the same required response-equivalence class:
Proof sketch. By the bridge condition, the class-candidate set induced by the epistemic response trace is exactly the conditional support of under the realized information state. For a finite random variable with positive probabilities on its support, conditional entropy is zero exactly when the conditional support is a singleton. Therefore, terminal real KTD is zero exactly when the terminal epistemic trace has reduced the possible required response-equivalence classes to one. This does not require the regulator to have fixed a unique response-value. It requires only that all remaining response-values be equivalent for the regulatory problem.
If the selected action-unit sequence carries information about beyond the realized signals, then it must remain inside the conditioning set as shown above. If the protocol is fixed in advance, or is conditionally determined by information already contained in and , then the simpler expression omitting is equivalent.
Action Units, Signals, and Response-Class Commitment
An action unit is an operational intervention performed during an episode. The intervention may produce or expose a signal , whose realized value updates the set or probability distribution of responses still considered possible. The action unit and the signal should therefore be kept conceptually distinct: the action unit is what the regulator does, whereas the signal is the evidence made available by that action.
The first implication is operational rather than deterministic: an action unit specifies how evidence is sought, but the resulting signal-value may depend on the disturbance, the system, and the current knowledge state. The second implication represents the epistemic effect of the realized evidence on the live candidate-response set.
Let denote the live concrete candidate-response set after the -th action unit in the realized set-based trace. Let be the count measure, or another admissible size measure, on candidate-response sets. Provided both sets have positive measure, define the concrete-response amount of selection contributed at stage as:
In the finite case with the count measure, this becomes:
This measure records the logarithmic reduction in the variety of live concrete responses. Within an ordinary fixed-knowledge-state episode:
- when no concrete candidate response is eliminated;
- when the update eliminates some candidates but leaves more than half of the previous measure;
- when the update halves the measure of the live candidate set; and
- when the update leaves less than half of the previous measure.
The concrete-response measure does not yet establish how much uncertainty about the required response-equivalence class has been removed. Several concrete responses may belong to the same response-equivalence class and may therefore be interchangeable for the regulatory problem. Let map concrete responses to their response-equivalence classes. Using the response-candidate trace defined above, the corresponding class-projected candidate set is:
For finite class-candidate sets, define the class-level set-based amount of selection as:
The concrete-response and class-level amounts of selection need not coincide:
For example, an action unit may eliminate several concrete responses while leaving every previously possible response class represented. In that case, concrete-response variety has been reduced but no required response-equivalence class has yet been ruled out. Conversely, a small concrete-set reduction may eliminate an entire response class and therefore produce a larger proportional reduction at the class level. The two measures coincide only under additional structural conditions on the projection , such as when it is injective on the relevant live candidate responses.
Set reduction must also be distinguished from probability redistribution. Let denote the posterior probability distribution over the required response-equivalence classes after observing the information available through stage . An action unit may affect the episode in four distinct ways:
| Case | Support effect | Probability effect | Interpretation |
|---|---|---|---|
| Pure support reduction | Relative probability ratios among the surviving classes are unchanged. | The signal rules out one or more candidate response classes. | |
| Probability redistribution only | The same classes remain possible, but their relative plausibilities change. | ||
| Mixed update | on the surviving support. | The signal both eliminates classes and redistributes probability mass among the survivors. | |
| Epistemically null update | The signal contributes no information about the required response class. |
In a probability-redistribution-only update, no response class has been ruled out, and therefore:
The realized entropy-based selection measure may nevertheless be positive, zero, or negative because the posterior distribution over the surviving classes has changed.
In a mixed update, because the class support has shrunk. The realized entropy-based selection may still be positive, zero, or negative, depending on how probability mass is redistributed among the surviving classes. Non-negativity applies to the expected information gain, not necessarily to every realized entropy change.
In an epistemically null update, both the posterior support and the posterior distribution remain unchanged:
Thus, an action unit may narrow an episode by eliminating concrete responses, by eliminating response-equivalence classes, by concentrating probability mass among classes that remain possible, by combining these effects, or by contributing no information about the required response class. The concrete set-based measure observes reduction in response variety. The class-level set-based measure observes elimination of response-equivalence classes. The entropy-based measure additionally observes probability redistribution. These three effects are related, but they are not identical.
Under a fixed knowledge state , ordinary conditioning on a signal-value that had positive probability cannot broaden the support of possible response classes:
If an action unit reveals that a response class previously assigned zero support must be reconsidered, the event is not ordinary staged conditioning under the unchanged knowledge state . It is a model-revision, reopening, or rework event and should be represented by an updated knowledge state or by the start of a new episode.
At some stage, the regulator commits to a response-equivalence class. Let be the set of response-equivalence classes over which ranges. Let denote the response class actually fixed by the regulator after stages of selection. This commitment may be represented by a decision rule:
Response-class commitment is an act of the regulator and does not, by itself, prove that all uncertainty has been removed. A regulator may commit while several response classes remain possible. The special case of uniquely determined commitment occurs when the terminal class-candidate set is a singleton:
The actually fixed class is distinct from , which denotes the required response-class uncertainty being reduced by the staged-selection process. In a well-aligned successful case, the regulator fixes the class required by the regulatory problem. The notation keeps the required class and the actually fixed class separate because a regulator may become confident, commit, and still select the wrong class.
A realized set-based episode may therefore be represented as:
This display describes the realized set-based episode. The corresponding information-theoretic conditioning path is:
If the sequence of action units is fixed in advance, or is generated by a policy already included in the regulator's prior structure , the signal sequence is sufficient to represent the staged conditioning path. If the choice of the next action unit is itself adaptive and may convey information about , the selected action unit must also be included in the information sequence. The stage-level information contribution is then represented by:
Success, Closure, and Policy-Level Success
At the response-class level, success requires that the actually fixed class lie inside the acceptable response-class set for the available disturbance information:
In the partially observed case, a response class is acceptable under Y = y only if every concrete response in that class is acceptable for every actual disturbance-value still possible under Y = y:
This is a robust class-level acceptability condition. It is stronger than realized closure success, because it requires success for every disturbance still possible under the observation, not merely for the actual disturbance that occurs.
Once the response class is fixed, a concrete response is emitted from that class:
The Table of Outcomes then produces the closure:
Closure does not, by itself, imply that the terminal realized Knowledge To Be Discovered is zero. Closure means that the regulator has committed a final response and that the Table of Outcomes has produced an outcome-value. It does not necessarily mean that the realized conditioning path has eliminated all posterior uncertainty about the required response-equivalence class.
A closed episode may therefore still end with positive terminal realized Knowledge To Be Discovered:
This is not a contradiction. It means only that the episode has produced a closure while the model still represents residual uncertainty over the required response-equivalence class. Whether that residual uncertainty counts as remaining Knowledge To Be Discovered depends on the response-class granularity and on whether the model requires one specific target class to be fixed.
At the level of a realized episode, success is judged by the actual closure:
The closure is acceptable exactly when its induced essential-variable value lies in the acceptable region:
At the probabilistic policy level, a stronger almost-sure success condition is:
These are different levels of evaluation. The first judges one realized episode. The second judges the regulator's policy across the modeled distribution of episodes.
In the unique-target case, successful selection requires that the residual uncertainty about the required response-equivalence class approach zero: HMt(X | Y, U1, ..., Uk) → 0. However, zero residual entropy means only that the regulator has enough information to identify the required class. It does not by itself mean the regulator actually selects it. Successful selection additionally requires that the class actually fixed by the regulator equals the required class: X̂k = X.
More generally, regulation does not require that only one concrete response remain possible. It requires that the concrete response finally emitted by the regulator belong to a response class that induces an outcome inside the acceptable region.
In the fully observed special case, where Y = D, the closure may also be written as Z = T(Y,Rfinal). In the general partially observed case, however, Y is only the regulator's observation or signal, while D is the actual disturbance-value that enters the Table of Outcomes.
Summary
The information-theoretic staged-selection formulation does not replace the Table of Outcomes, the outcome-to-essential-variable map, the acceptable region, the set-based episode, or the closure. It defines the Knowledge Discovery Process as the staged reduction of Knowledge To Be Discovered, relative to the regulator's knowledge state Mt.
The set-based episode is the realized regulatory event. The conditioning path is the information-theoretic path through that episode. The expected KTD trace measures staged uncertainty reduction before signal-values are known. The realized posterior trace records what happens after the actual signal-values are observed. The bridge condition links concrete candidate narrowing to response-class posterior support. Success is judged after final response commitment, when the emitted concrete response produces an acceptable closure.
In this limited formal sense, the Knowledge Discovery Process gives an “it from bit” reading of regulation: the realized response or response rule is the result of information-bearing selection from a larger space of possibilities[6].
Learning (across episodes in a window)
The preceding sections described how a single episode discovers enough information to commit a response and produce a closure. The present section asks a different question: whether the discoveries made inside one episode are retained as stored regulatory structure for later comparable episodes.
Comparable episodes
A comparable task class defines the reference frame for comparison. A comparable episode is a realized closed episode whose Knowledge To Be Discovered can be evaluated inside that reference frame. Comparability is therefore not an intrinsic property of an episode alone. It is a relation between an episode and a declared task class.
Let denote a comparable task class. A comparable task class is not merely a collection of tasks that appear similar in ordinary language. It is a formal comparability frame for a recurring kind of regulatory problem. It fixes, or supplies explicit correspondences for, the disturbance-information variable , the required response-equivalence variable , the response-equivalence abstraction , and the modeling resolution at which Knowledge To Be Discovered is measured.
Thus, within a comparable task class, responses may differ at the concrete action level , but they are compared only after being projected into the same response-equivalence class space . Likewise, disturbances may differ at the raw observational level, but they must be represented through the same disturbance-information variable , or through an explicitly declared correspondence to it.
Comparability of task class therefore requires sameness of semantic structure: the same kind of disturbance information, the same kind of required response class, the same response-equivalence abstraction, and the same measurement resolution. It does not require the empirical probability distribution over or to be identical across episodes. It means same regulatory measurement frame.
A closed episode is comparable under if the episode admits an interpretation in that task-class frame such that the following three quantities are well-defined over the same and :
Two closed episodes and are comparable episodes when there exists a task class such that both episodes are comparable under that same task class:
Here is the class of closed episodes interpretable under task class . The episodes may have different realized disturbances, different staged-selection paths, different committed responses, and different closure outcomes. They are comparable because the same response-selection uncertainty is being measured at the same abstraction level.
This means that all episodes assigned to ask the same type of regulatory question: given a disturbance-information state, which response-equivalence class is required to keep the relevant outcome within the intended goal condition? In this sense, the same kind of regulatory problem is being solved.
For exact comparison, the following comparability conditions must hold:
- the disturbance-information variable has the same semantic meaning across the compared episodes;
- the required response-equivalence variable has the same semantic meaning across the compared episodes;
- the response-equivalence map is fixed, or its changes are mediated by an explicit equivalence between response classes;
- the entropy quantities are evaluated at the same modeling resolution;
- the marginal entropy of the required response-equivalence variable is held fixed when changes in stored coupling and changes in KTD are read as exact duals.
Thus comparable episodes are not episodes that look identical operationally. They are episodes whose Knowledge To Be Discovered is measured against the same unresolved response-selection problem.
In plain terms: two episodes do not need the same disturbance, response, outcome, duration, or internal number of stages. They need to belong to the same regulatory problem: "Given this kind of disturbance information, which kind of response-equivalence class must be fixed?"
Learning as stored transformation
Within an episode, staged selection reduces Knowledge To Be Discovered by conditioning on the available disturbance information and the subsequent selection signals. Across episodes, learning occurs only if some of that reduction is incorporated into the regulator's stored law of action, so that the next comparable episode begins with stronger disturbance-response coupling and less residual Knowledge To Be Discovered.
Thus, in this section, learning is the across-episode transformation:
where denotes the regulator's stored structural coupling at the start of episode . In Ashby's terms, this is the regulator's learned law of action: the stored functional or probabilistic structure by which disturbances are mapped to responses. It is not the Table of Outcomes itself.
The fixed environmental relation remains:
and the outcome-to-essential-variable map remains:
Learning does not alter or in the fixed-table case. It alters the regulator's stored coupling , and therefore alters the response law induced at the start of later episodes.
From staged discovery to stored learning
For episode , let be fixed at the start of the episode. It induces the regulator's epistemic probability law over the required response-equivalence class:
Here denotes the required response-equivalence class at the regulatory granularity being analyzed. In the unique-target case, this is the same variable previously denoted . Thus is not merely actual response variation. It is the target response-class variable whose value must be fixed for successful regulation under the adopted criterion.
The initial Knowledge To Be Discovered at the start of episode is:
During the episode, the regulator observes an information-bearing sequence:
This is the within-episode evidence stream generated by the staged selection process. It may include tests, observations, feedback signals, constraint checks, partial executions, or other action-unit results. The corresponding within-episode posterior Knowledge To Be Discovered is:
The within-episode discovery is the reduction:
This reduction is not yet learning. It is only discovery inside the current episode. Learning occurs only if the regulator stores and reuses the resulting information by updating its law of action for later comparable episodes.
After the episode closes, the regulator may update its stored coupling using the evidence stream, the class it actually fixed, the final concrete response, the produced closure, and the valuation of that closure. Let the closure-valuation signal be:
Then a general update form is:
This expression does not assume a particular memory mechanism. The update may overwrite, patch, strengthen, weaken, version, or reorganize the stored coupling. The formal question is not how storage is implemented, but whether the next induced response law has less residual Knowledge To Be Discovered for the same task class.
Across-episode comparison of stored coupling
In the across-episode analysis, the task class must be comparable. The stored coupling may change, but the response classes whose uncertainty is being measured must not silently change meaning.
Thus, for each episode , the stored coupling induces:
Here is the residual lack of requisite knowledge at the start of episode . It measures how much uncertainty remains, after the available disturbance information is known, about which required response-equivalence class must be fixed.
The mutual information: is the stored requisite coupling at episode start: the amount of response-selection structure already aligned with the disturbance distinctions relevant to the task. It is an information-theoretic measure of the coupling induced by .
The comparability of episodes requires that both episodes be evaluated over the same task-class variables, alphabets, and abstraction maps. This makes the quantities and semantically comparable across episodes. However, semantic comparability alone does not require the marginal response-class variety to remain constant, because two episodes can use the same response-class alphabet while having different probability distributions over response classes. For example, both episodes may use the same response classes: , but in one episode the required responses are evenly distributed, while in another one response class dominates. Same alphabet, different entropy.
For the narrower purpose of reading changes in stored requisite coupling and changes in lack of requisite knowledge as exact duals, impose the stronger constant marginal response-variety assumption:
The assumption means that the marginal variety of required response classes has not changed between the two episodes.
Under this assumption, the identity implies that any increase in stored requisite coupling is exactly matched by an equal decrease in lack of requisite knowledge.
Therefore, under the constant marginal response-variety assumption, an increase in stored requisite coupling is exactly equivalent to an equal decrease in residual lack of requisite knowledge:
If the constant marginal response-variety assumption is relaxed, the two changes need not coincide. Part of the change in mutual information may then come from drift in the marginal entropy , not only from reduced conditional ignorance. In what follows, the constant marginal response-variety assumption is maintained.
Learning axiom
Learning Axiom (Structural Knowledge Accumulation). A regulator learns, in the structural-coupling sense, when the within-episode evidence stream is incorporated into an updated stored law of action such that the next comparable episode begins with less residual Knowledge To Be Discovered.
Formally, learning from episode to episode requires:
Under the fixed marginal entropy assumption, this is equivalently:
In words: after the update, the regulator begins the next comparable episode with stronger stored disturbance-response coupling and therefore less residual uncertainty about which response-equivalence class must be fixed.
This axiom defines positive learning at the chosen regulatory granularity. If the update leaves unchanged, then the episode has not improved stored requisite knowledge for that task class. If the update increases the conditional entropy, the regulator has degraded its stored coupling.
This learning criterion is still epistemic. It says that the regulator has reduced uncertainty about the required response-equivalence class. Regulatory success also requires correctness: the class actually fixed by the regulator must be acceptable for the disturbance information and must produce an acceptable closure through the Table of Outcomes.
and, after concrete response commitment:
Thus a regulator may learn in the epistemic sense and still fail if it stores or applies the wrong mapping. Conversely, a regulator may produce a successful closure once without learning, if the episode's discovery is not retained in .
Strong learning: posterior becomes prior
The learning axiom above is weak. It requires only that the stored coupling improve. A stronger assumption is obtained when the regulator stores and reuses, without loss, the uncertainty reduction achieved inside episode .
Strong Learning Assumption (Posterior-Becomes-Prior Rule). For a stable task class, the posterior uncertainty achieved by the end of episode becomes the prior stored uncertainty at the start of the next comparable episode:
In words, the discoveries made during episode are not merely used once. They are incorporated into the stored structure that shapes the regulator's next prior response law.
Under the dual knowledge view, and under the invariant marginal entropy assumption, the same rule can be written as:
This rule is not a consequence of conditioning alone. Conditioning happens inside the current episode. Learning requires retention: the posterior structure must be written into the regulator's stored law of action.
The Posterior-Becomes-Prior Rule therefore requires at least the following conditions:
- the same task class or disturbance semantics across episodes;
- the same response-equivalence map gt : 𝓡 → 𝓧t, or an explicit correspondence identifying the response classes across episodes;
- successful retention of within-episode discoveries;
- reuse of the retained structure in later episodes;
- no intervening forgetting, context drift, or criterion change that invalidates the comparison.
Corollary (Complete Adaptation under Strong Learning). Under repeated successful strong learning, the stored requisite coupling approaches its task-class ceiling:
and the residual lack of requisite knowledge approaches zero:
In that limit, no further within-episode discovery is required to determine the response-equivalence class for the task class under study. This is complete adaptation at the chosen regulatory granularity.
Learning, goal revision, and behavioral revision
Learning must be distinguished from goal revision and behavioral revision. They modify different parts of the regulatory model.
Goal revision changes the acceptable essential-variable region:
and therefore changes the acceptable outcome-set:
Behavioral revision changes what the regulator does. At the rule level, this means a change in the response rule:
Learning changes the stored law of action:
These changes may be related, but they are not identical. A criterion can change without learning. A behavior can change without learning if the regulator merely switches among already available rules. A regulator can learn without immediately producing a different outcome if the newly stored structure is not yet exercised in a later episode.
This distinction is important for the fixed-table case. Outcome-values are not deleted from . They may lose or gain acceptability because changes. But learning is not the change in acceptability itself. Learning is the change in stored coupling that improves later response selection under the task class being compared.
Knowledge Discovery Accounting
Operational ledger
Let the fixed regulatory frame be the Table of Outcomes:
with outcome-to-essential-variable map
At time , the acceptable essential-variable region is
This induces the acceptable outcome-set:
Closure events
A closure event at time is an act in which the regulator selects a response against an observed disturbance , producing the realized outcome-value:
When the closure event is generated by the response rule prevailing at time u, we have . The ledger can also be read more generally as recording realized response selections, even when no total response rule is reconstructed.
The closure event is recorded as:
It is an acceptable closure when produced iff:
Equivalently:
Thus an acceptable closure is not merely an outcome-value in the table. It is a realized action whose produced outcome was acceptable under the criterion prevailing at the time of production.
Window
Let the observation window be:
The window contains the closure events whose event times fall inside the interval. Using a half-open interval avoids double-counting events at boundaries when consecutive windows are used.
Define the accepted closure history inside the window:
This is an event history, not a set of outcome-values. Therefore it preserves multiplicity. If two different closure events produce the same outcome-value,
they still count as two closure-fixing acts.
Gross counted closures
The gross counted closures in the window are:
The gross closure count tallies the acts , not the values .
This counts all successful-at-production closure-fixing acts in the window. It does not count failed attempts. If an action produced an outcome that was not acceptable under the criterion prevailing at the time of production, , then it does not enter , because the ledger is tracking cases of successful regulation that may later cease to count under revised success criteria.
Historically realized outcome-set
The historically realized outcome-set induced by the accepted closure history is only the support of the trace:
Because this is a set, it collapses duplicates. Thus:
The inequality may be strict when multiple acceptable closure events produce the same outcome-value. Therefore answers: which acceptable outcome-values appeared? By contrast, answers: how many acceptable closure-fixing acts were expended?
Continuously surviving counted closures through the window
The operational section evaluates originally successful closures over the criterion history of the window, not merely against the final criterion. A closure event was successful when produced. It counts as a surviving closure at the end of the window only if its produced outcome-value was never invalidated by any acceptability criterion that applied after its production time.
Thus a closure event survives the window iff:
Define the surviving counted closures in the window as:
Equivalently:
This is a survival-through-the-window count. It asks how many closures were successful when produced and were never invalidated by any acceptability criterion applied from their production time through the end of the window. It is therefore a continuous-survival count, not merely a final-criterion count.
Invalidation load
Define history invalidation load in the window as the number of originally successful closures that were later invalidated by at least one acceptability criterion before the end of the window:
Equivalently:
Thus counts closure-fixing acts that were successful when produced but failed to survive the subsequent criterion history of the window. It does not count the corrective work that replaces them.
Therefore:
Hence:
Interpretation
The ledger separates four levels:
- possible outcome-values in ;
- the time-indexed criterion of acceptability ;
- realized closure events in the temporal trace;
- closure events that remained continuously accepted through the rest of the window.
Ashby's table remains fixed. Outcome-values are not deleted from . What changes over time is the criterion by which fixed outcome-values are judged acceptable:
This distinction matters. A criterion revision is a change in the acceptable region, and therefore in the acceptable outcome-set:
A behavioral revision, by contrast, is a change in what the regulator actually does. At the rule level, this means a change from one response rule to another:
and, at the induced-outcome level, it means a change in the rule-induced outcome map or in its image:
The operational ledger in this section tracks criterion invalidation of already successful closures. It does not, by itself, prove that the regulator has changed its behavior. A closure can therefore be successful when produced and later cease to count because the goal criterion changes:
That is the operational meaning of in this ledger. More generally, counts closures that were successful when produced but were invalidated at least once before the end of the window, even if they later became acceptable again.
measures invalidated successful closure, not completed corrective rework. Corrective rework is observed only when a later closure event, response selection, or response-rule revision replaces or repairs the invalidated closure.
Corrective rework would require an additional behavioral event: the regulator must select a new response, produce a new outcome-value, or revise the response rule so that the revised behavior again satisfies the current acceptable outcome-set. That would be tracked by comparing the produced closure history or the response rules before and after the criterion revision, not merely by comparing with .
Therefore, this ledger does not model deletion of outcome-values from , and it does not yet model all behavioral replacement work. It models the narrower case in which a previously successful closure is invalidated by a later criterion of success. Behavioral revision is a separate question: it begins only when the regulator changes what it produces in response to disturbances.
Operational ledger for goal-model revision
The ledger above tracks the case in which a single time-indexed acceptable set serves both as the criterion under which closures are produced and as the criterion against which they are later evaluated. A closure can be invalidated only by external goal revision, i.e. by a change in itself.
A parallel case arises when the regulator does not know the acceptable region perfectly. The regulator acts under a believed acceptable region, while survival is judged against an authoritative acceptable region. In that case, invalidation is driven not by external goal revision but by revision of the regulator's model of the goal.
In this case, there are two acceptability structures:
- the authoritative acceptable outcome-set, which remains fixed during the window;
- the regulator's believed acceptable outcome-set, which may change as knowledge is discovered.
Authoritative and believed acceptability
Let the authoritative acceptable essential-variable region be:
The authoritative acceptable outcome-set is its pullback along :
The authoritative set does not change during the knowledge-discovery process. What changes is the regulator's believed model of the acceptable region.
At time , let the regulator's believed acceptable essential-variable region be:
This induces the regulator's believed acceptable outcome-set:
Thus, in goal-model revision, the operative distinction is not:
but rather:
This is why the process is called goal-model revision, not external goal revision. The goal did not change. The regulator's model of the goal changed.
The believed acceptable set may be incorrect: in general,
The believed set may include outcome-values that the authoritative set excludes, exclude outcome-values that the authoritative set includes, or both.
Provisional closure events
A closure event at time is still recorded as:
But in a goal-model-revision process, the closure is not yet judged by the authoritative set. It is provisionally accepted when produced iff the produced outcome-value belongs to the regulator's believed acceptable set at that time:
Equivalently:
A provisionally accepted closure is not necessarily an authoritatively acceptable closure. It is a closure that the regulator's model of the goal admits at the time of production.
Thus provisional acceptability is model-relative. It records what the regulator counted as successful under its current believed goal model.
Provisional closure history
Let the observation window be:
The provisional closure history in the window is:
This is an event history, not a set of outcome-values. It preserves multiplicity. If the regulator produces several provisional closures for the same target position, all of those closure-fixing acts remain visible in the ledger.
Gross provisional closures
The gross provisional closures in the window are:
This counts all closure-fixing acts that were provisionally accepted under the regulator's believed model at the time of production.It does not yet say whether those closures were authoritative successes.
Net surviving closures
A provisionally accepted closure survives authoritative checking iff its produced outcome-value belongs to the fixed authoritative acceptable outcome-set:
Equivalently:
Define the authoritative net surviving closures in the window as:
This counts closure-fixing acts that were provisionally accepted when produced and were authoritatively acceptable.
Unlike the external goal-revision ledger, this survival test does not require a time-indexed criterion history after production. The authoritative acceptable set is fixed. The change is epistemic: the regulator later discovers whether a provisional closure was inside or outside the authoritative set all along.
Goal-model invalidation load
A provisionally accepted closure is invalidated by goal-model revision iff it was accepted under the believed model when produced but is outside the fixed authoritative acceptable outcome-set:
Define the goal-model invalidation load in the window as:
This counts closure-fixing acts that were successful relative to the regulator's believed model at production time, but failed the authoritative check. measures invalidated provisional closures, not completed corrective rework. Corrective rework is observed only when a later closure event or response-rule revision replaces or repairs the invalidated closure.
Ledger identity
Every provisional closure either survives authoritative checking or is invalidated by it. Therefore:
Hence:
This identity is not an entropy identity. It is an operational accounting identity: provisional closure work equals authoritative surviving closure work plus model-invalidation load.
Model-revision events
If the model updates themselves need to be represented explicitly, introduce a model-revision event:
Here is the model before revision, is the model after revision, and is the checking evidence, observation, comparison, or authoritative feedback that triggered the revision.
The model-revision event induces believed loss and gain sets:
A prior provisional closure is invalidated by the model-revision event if the closure occurred before the model revision and its outcome-value is among the values removed from the believed acceptable set:
In the special case where the revision is caused by authoritative checking, the removed believed values are precisely those discovered not to belong to the authoritative acceptable set:
This makes the knowledge-discovery structure explicit: the regulator acts under a believed goal model, receives evidence, revises the model, and thereby invalidates some earlier provisional closures.
Corrective replacement
Goal-model invalidation does not, by itself, prove that corrective replacement has occurred. Corrective replacement requires a later closure event, response selection, or response-rule revision that repairs the invalidated closure.
If needed, this can be represented by an additional repair relation between closure events:
where means that the later closure is treated as a corrective replacement for the earlier invalidated closure . At minimum, such a relation should satisfy:
In the typing example, a natural repair relation may also require that both closure events address the same target position:
The repair relation is additional structure. The invalidation ledger can count model-invalidation load without it. The repair relation is needed only when the modeler wants to identify which later closure repaired which earlier provisional closure.
Relation to the criterion-revision ledger
The criterion-revision ledger and the goal-model-revision ledger are two instances of the same accounting structure, separated by which acceptable set plays the role of production criterion and which plays the role of evaluation criterion.
In the criterion-revision ledger, both roles are played by the same time-indexed acceptable set . A closure is acceptable when produced iff , and it survives iff it remains in for every . Invalidation is then driven by external goal revision.
In the goal-model-revision ledger, the production criterion is the believed acceptable set , while the evaluation criterion is the authoritative acceptable set . Invalidation is then driven by revision of the regulator's model of the goal, not by any change in the authoritative goal itself.
The two ledgers coincide in the degenerate case in which the regulator's believed model agrees at all times with the authoritative criterion, that is, for all in the window, and the authoritative criterion is itself constant. In that degenerate case, and .
In general, the two ledgers answer different questions. measures invalidation by criterion change. measures invalidation by model mismatch under a fixed authoritative criterion. Neither measures corrective rework: corrective rework is a separate behavioral event tracked by changes in the response rule or in subsequent closure events.
The example in the next section instantiates the goal-model-revision ledger for a typing task in which the authoritative goal is fixed throughout, and the invalidation load records the discovery process by which the typist's believed model is brought into agreement with the authoritative criterion .
Interpretation
This ledger separates three things that should not be collapsed:
- provisional closure: the regulator produced an outcome accepted by its believed goal model;
- model invalidation: later checking showed that some provisional closures were outside the authoritative acceptable set;
- corrective replacement: later behavior repaired the invalidated closure.
Thus the goal-model-revision ledger does not say that the authoritative goal changed. It says that the regulator discovered that its believed model of the goal was wrong or incomplete. The authoritative acceptable set remained fixed, while the believed acceptable set was revised.
That is the operational form of a human knowledge-discovery process: provisional closure under an imperfect model, discovery of mismatch against the authoritative goal, invalidation of some earlier closures, and possible corrective replacement.
Operational counting of action units as Effective non-net-progress load
A counted atomic unit is either a non-closure action unit inside episode t, or a closure unit of episode t. The episode protocol contains only non-closure action units. The closure unit is the terminal commitment event and is counted separately.
For a window of closed episodes , the gross action-unit count is:
Observable invalidation load enters through the operational ledger. Some gross closure events are counted when produced but later fail to survive the window's evaluation criterion. In the external criterion-revision ledger, this invalidation load is . In the goal-model-revision ledger, the corresponding invalidation load is .
Definition (Effective non-net-progress load). If the measurement window records observed invalidation load or lost non-closure discrimination as , then the effective non-net-progress load in window is:
This is an operational ledger quantity. It counts effective discriminating work at the observed action-unit level. It is the physical non-closure count augmented by a one-unit non-progress debit for each invalidated gross closure. By construction , with equality if and only if ; whenever invalidation occurs, strictly exceeds the number of non-closure units actually present on the channel.
Combining the definition with :
In the physical partition, each invalidated closure sits on the closure side, inside . In the effective partition, that same closure has been removed from the surviving-closure side — it is not in — and re-booked as a non-progress debit inside . No new units are introduced; the invalidated closures are simply re-attributed from “closure” to “load.” Equivalently, relative to the physical channel each invalidated closure is counted twice across the two partitions: once as the gross-closure unit it physically is, and once as the discrimination-equivalent debit it is charged to. This double appearance across partitions — not within either one — is precisely why is a defined effective load and not a action unit count.
Knowledge ledger
The operational ledger records realized closure events. The knowledge ledger attaches a bit-valued epistemic accounting row to each closure event. It answers a different question: after a closure and its associated update, how much Knowledge To Be Discovered remains for the next comparable episode?
The operational ledger counts closure-fixing acts. The knowledge ledger counts changes in residual Knowledge To Be Discovered. Therefore the two ledgers are linked by the same closure history, but they do not measure the same quantity.
Closure-indexed knowledge ledger
Let the operational closure event at episode index be:
Let denote the comparable task class under which the episode is evaluated. The task class fixes the meaning of the disturbance information , the required response-equivalence variable , and the response-equivalence map used for comparison across episodes.
The closure-indexed knowledge ledger row is:
This row records the epistemic state before the episode, the terminal posterior uncertainty reached inside the episode, and the stored uncertainty with which the next comparable episode begins.
KTD states at closure boundaries
The initial Knowledge To Be Discovered at the start of episode is:
This is the residual lack of requisite knowledge induced by the stored law of action before the episode's internal staged selection has occurred.
Let the episode's information-bearing evidence stream be:
The terminal Knowledge To Be Discovered inside the episode is:
This quantity is evaluated under the knowledge state that governed the episode. It measures posterior uncertainty after the episode's actual evidence stream has been observed. It does not yet say how much of that discovery has been retained.
The stored Knowledge To Be Discovered at the start of the next comparable episode is:
This is the key knowledge-ledger balance after closure and update. It measures how much Knowledge To Be Discovered remains in the stored law of action for the next comparable episode.
Within-episode discovery and retained learning
The within-episode discovery achieved by the staged selection process is:
This is discovery inside the episode. It is not yet stored learning. Stored learning is measured by comparing the start of the current episode with the start of the next comparable episode.
The retained KTD reduction is:
This is the knowledge gain recorded by the ledger. It counts the number of bits by which the next comparable episode begins with less Knowledge To Be Discovered.
The KTD increase is:
This is the knowledge loss recorded by the ledger. It counts the number of bits by which the next comparable episode begins with more Knowledge To Be Discovered. That may occur through forgetting, model drift, criterion misalignment, incorrect generalization, or degradation of stored coupling.
Knowledge ledger stock-flow identity
The knowledge ledger has the following exact stock-flow identity:
This identity says that the next episode's initial Knowledge To Be Discovered equals the current episode's initial Knowledge To Be Discovered, minus retained knowledge gain, plus knowledge loss.
Equivalently, in stored-coupling form under the comparability assumption:
The KTD form and the stored-coupling form are dual readings of the same update when the task class, disturbance-information semantics, response-equivalence map, and marginal entropy of the required response-equivalence class are comparable across episodes.
Relation to the operational ledger
The operational ledger and the knowledge ledger are joined by the closure event . The same closure can be read operationally as a produced outcome and epistemically as a boundary at which Knowledge To Be Discovered is measured.
| Ledger | Recorded unit | Primary measure | Question answered |
|---|---|---|---|
| Operational ledger | Closure event | Count of closure-fixing acts | What was produced, preserved, or invalidated? |
| Knowledge ledger | Closure-indexed KTD state | Bits of residual Knowledge To Be Discovered | Did the next comparable episode begin with less KTD? |
The operational ledger identity:
is an accounting identity over closure counts. The knowledge ledger identity:
is an accounting identity over bits of Knowledge To Be Discovered. The two identities should not be conflated.
An invalidated closure may trigger learning, but invalidation is not itself learning. A corrective closure may show changed behavior, but changed behavior is not itself stored learning. Stored learning is demonstrated only when the next comparable episode begins with less residual Knowledge To Be Discovered:
Interpretation
The closure-indexed knowledge ledger separates four quantities that are often confused:
- Within-episode discovery: the reduction from to inside the episode.
- Retained learning: the reduction from to across episodes.
- Knowledge loss: any increase in the next episode's starting Knowledge To Be Discovered.
- Operational invalidation: a closure-count event in the operational ledger, not automatically a bit-valued knowledge loss.
Thus, a closure can be operationally successful but epistemically weak if it does not reduce future Knowledge To Be Discovered. A closure can involve rework and still produce positive learning if the next comparable episode begins with stronger stored coupling. Conversely, a closure can be accepted and still produce no learning if the discovered information is not retained.
The knowledge ledger therefore gives the operational ledger its epistemic counterpart: the operational ledger records what the regulator produced; the knowledge ledger records how much ignorance the regulator still carries forward.
Window-level accounting measures
So far, we have presented how the operational and knowledge ledgers are populated at the level of closure events and closure-indexed knowledge rows over an episode. For measurement purposes, those rows can also be aggregated over an observation window. Window-level accounting measures do not introduce new regulatory dynamics. They summarize the operational and epistemic traces already recorded by the ledgers.
The central measurement question is: over a given window and task class, how much residual Knowledge To Be Discovered did episodes begin with, on average? This section defines that quantity as an average of per-episode residual ignorances. It is not the entropy of a pooled variable, and it is not a new information-theoretic identity.
Measurement window and eligible knowledge rows
Let the observation window be:
The window contains closure-indexed knowledge-ledger rows whose closure times fall inside the interval. As in the operational ledger, the half-open interval avoids double-counting boundary events when consecutive windows are used.
For a comparable task class , define the eligible knowledge-row history in the window as:
This is an event history, not a set of unique task types. It preserves multiplicity: if several closure events in the same task class occur inside the window, each contributes one row.
Let the number of eligible rows be:
If , the task-class-specific window measures below are undefined for that window.
Average starting Knowledge To Be Discovered
For each eligible row , define the pre-episode residual ignorance as the row's starting Knowledge To Be Discovered:
The task-class-specific average Knowledge To Be Discovered in the window is:
This is an average of per-episode residual ignorances. It answers: among the comparable episodes that closed inside the window, how much response-selection uncertainty did the regulator still carry at episode start, on average?
The same statistic can be evaluated over all task classes by omitting the task-class restriction:
The all-task-class version is useful as an overall operational dashboard measure. The task-class-specific version is usually more interpretable, because Knowledge To Be Discovered is meaningful only relative to a declared comparability frame.
Companion window knowledge measures
The same eligible knowledge-row history can be used to compute companion averages. The average terminal Knowledge To Be Discovered is:
The average within-episode discovery is:
The average retained knowledge gain is:
The average knowledge loss is:
Finally, the average retained KTD reduction is:
This quantity is positive when the average ledger row records net retained reduction in future Knowledge To Be Discovered. It is negative when knowledge loss dominates retained gain.
Relation to operational window measures
The operational ledger and the knowledge ledger are joined by the closure-event index. The operational ledger classifies closure events by their operational status: produced, surviving, invalidated, provisionally accepted, or authoritatively accepted. The knowledge ledger attaches bit-valued epistemic quantities to those same closure events.
This join supports measurement queries that neither ledger answers in isolation. The operational ledger alone can say which closures survived or were invalidated. The knowledge ledger alone can say how much within-episode discovery, retained knowledge gain, or knowledge loss was recorded for a closure-indexed row. Only the joined ledger can ask whether different operational classes of closures have different epistemic profiles.
For example, in the goal-model-revision ledger, the provisionally accepted closure history is:
The authoritative surviving subset is:
The model-invalidated subset is:
These two subsets partition the provisional closure history:
Now join these operational subsets with the knowledge-ledger rows on the shared closure-event index. For closures that survived authoritative checking, the average within-episode discovery is:
Average within-episode KTD reduction for net surviving closures equals the average amount by which those episodes reduced residual Knowledge To Be Discovered between episode start and episode termination.
We can compute the ex-ante expected conditional entropy over all possible observation states:
(1)
It answers: before observing which knowledge state actually occurred, what is the expected uncertainty about the required response class, averaged over possible values of ?
We can also compute how much ignorance remained after within-episode discovery:
Then how much ignorance was removed inside those episodes:
For closures that were invalidated by goal-model revision, the corresponding average within-episode discovery is:
These two quantities can be compared. They answer the joined-ledger question: do surviving closures and invalidated closures differ in the amount of within-episode discovery they required or produced? This question is invisible to either ledger alone.
The same join can be used for other epistemic quantities. For example, one may compare retained knowledge gain:
with retained knowledge gain for model-invalidated closures:
The same convention applies to all conditional averages: if the denominator is zero, the corresponding average is undefined for that window.
The ledgers can be joined, conditioned, compared, and reported together. What should be avoided is treating closure counts and KTD bits as if they belonged to one conservation equation. The operational identity partitions closure counts. The knowledge-ledger identity tracks bit-valued changes in residual Knowledge To Be Discovered. The joined measures condition bit-valued quantities on operational event classes. They are valid measurement queries, but they do not collapse the operational and knowledge ledgers into one common unit.
Average KTD is not pooled entropy
The window statistic is not the entropy of a single pooled task variable. In general:
The left-hand side averages the conditional entropies attached to individual closure-indexed rows. The right-hand side would require constructing a new pooled probability model over window-level variables. Those are different operations.
For the same reason, the exact per-row duality between change in stored coupling and change in residual KTD does not automatically become an aggregate identity for window averages. In general:
Such a dual reading is valid only under stronger comparability conditions: the same task-class frame, the same response-equivalence abstraction, the same modeling resolution, and a fixed marginal entropy of the required response-equivalence variable. Even then, the identity applies cleanly at the row or matched-row level. Sliding-window averages add sampling, weighting, and window-composition effects.
Sliding-window series
Moving the window over time produces a measurement series. For a sequence of window endpoints , define:
Then the task-class-specific KTD trend is the sequence:
A downward trend means that comparable episodes are beginning with less residual Knowledge To Be Discovered on average. An upward trend means that comparable episodes are beginning with more residual Knowledge To Be Discovered on average. A flat trend means that the regulator's stored coupling is not measurably changing at the chosen task-class granularity, or that gains and losses are offsetting within the window.
Summary
Window-level accounting turns the closure-indexed ledgers into practical measurement series. The operational ledger supplies counts of produced, surviving, and invalidated closures. The knowledge ledger supplies bit-valued measures of residual ignorance, within-episode discovery, retained gain, and knowledge loss.
The key practical statistic is:
is average starting residual ignorance over comparable ledger rows in the window.
It is a useful summary statistic, not a replacement for the per-row knowledge-ledger identity. It should be read as an average burden of discovery carried into episodes, not as the entropy of a single pooled variable and not as the direct knowledge analogue of . The knowledge analogue remains the per-task-class stock-flow identity:
applied row by row and then summarized over the window.
Feedback-loop reading of revisions and the operational ledger
The preceding sections distinguish closure, acceptability, behavioral revision, learning, goal revision, goal-model revision, and ledger accounting. These constructions can now be read uniformly as feedback-loop-induced changes. The key point is that feedback does not name one kind of change. It names a loop in which a produced outcome is evaluated and the resulting signal is returned to some part of the regulatory system. What kind of revision occurs depends on what the feedback signal changes.
In the present formulation, the operational ledger is not itself the feedback loop. It is the memory trace that makes feedback across episodes observable. The feedback loop is the process by which closure events are recorded, evaluated, and then used to revise a response rule, a goal criterion, a believed goal model, or the regulator's stored law of action.
This is the cybernetic reading of regulation as a system of nested loops, where each loop is identified by its error signal, its revision target, and its characteristic time scale[7][57]. Ashby's two-loop scheme for adaptive machines is the historical antecedent: a fast inner loop selects responses within a fixed structure, and a slow outer loop changes the structure when essential variables leave the acceptable region[1][7].
The present formulation distinguishes three loops, because the formal model separates within-episode selection, across-episode learning of the response coupling, and revision of the goal or the regulator's model of the goal.
Feedback as a loop, not a revision type
At the first order, the regulator selects a response for a disturbance. A disturbance-value is paired with a response-value , and the Table of Outcomes produces the closure outcome:
The closure is then evaluated through the outcome-to-essential-variable map and the acceptable region prevailing at that time:
A feedback signal is generated when this evaluation is returned to the regulator. But the feedback signal becomes a revision only when it changes some component of the regulatory system. If it changes the active response rule, the result is behavioral revision. If it changes the stored law of action, the result is learning. If it changes the acceptable region, the result is criterion revision. If it changes the regulator's believed model of the acceptable region, the result is goal-model revision.
Thus invalidation is not itself learning, and it is not itself corrective rework. Invalidation is a feedback signal. Learning, behavioral revision, criterion revision, and model revision are different possible uses of that signal.
The regulatory state
Throughout this section, the fixed environmental frame is still the Table of Outcomes:
with outcome-to-essential-variable map:
In the fixed-table case, these remain fixed. The revisable regulatory state at episode index can be written as:
Here is the stored law of action, is the active response rule, is the regulator's believed acceptable essential-variable region, and is the authoritative acceptable region prevailing at time .
The acceptable outcome-set induced by the authoritative region is:
When the regulator acts under an imperfect model of the goal, its believed acceptable outcome-set is:
The three loops
Each loop is identified by its error signal, by the component of the regulatory state it revises, and by the time scale on which it operates. All three loops are negative-feedback loops in the cybernetic sense: each acts to reduce a measured discrepancy between an observed quantity and a reference[7].
Loop L1 — selection within an episode
L1 is the inner regulatory loop. Its reference is the acceptable outcome-set , or its believed counterpart when the regulator acts under an imperfect model.
Its error signals are the within-episode selection signals generated by action units . Its output is the staged narrowing of the candidate response-set:
The loop terminates when the regulator commits a response and produces the closure:
L1 operates within one episode. It does not, by itself, alter the stored law of action, the believed goal model, or the authoritative acceptable region. This is Ashby's first feedback loop, the error-controlled regulator[1][7].
Loop L2 — learning across episodes
L2 is an outer loop whose reference is reduction in residual Knowledge To Be Discovered for a comparable task class. Its error signal includes the closure-valuation:
together with the within-episode evidence stream , the response class actually fixed, the final concrete response, and the produced closure. Its output is the update:
When successful by the learning axiom, L2 reduces the residual lack of requisite knowledge at the start of the next comparable episode:
L2 operates across episodes within a window of comparable task instances. It corresponds to adaptive learning of a pattern of behavior appropriate for the environment[1][7].
Loop L3 — revision of the goal or the goal model
L3 is a higher-order outer loop whose reference is alignment of the criterion of success used by the regulator with the criterion against which closures are ultimately judged. It has two forms, corresponding to the two ledger cases developed above.
In the external goal-revision form, the trigger is an exogenous change in the authoritative acceptable region:
This change propagates into the acceptable outcome-set through the pullback along , yielding deletion, addition, and substitution operations on .
In the goal-model-revision form, the authoritative region remains fixed. The feedback signal is checking evidence that registers a mismatch between the regulator's believed acceptable set and the authoritative set:
The output is a model-revision event that revises the believed acceptable region:
In both forms, L3 does not by itself produce behavior. It revises the criterion against which behavior is judged. Behavioral consequences arise only when L1 is re-engaged under the revised criterion, possibly using a different response rule.
Mapping revision targets to feedback loops
All revision types can be represented as feedback-induced changes, provided the loop level and revision target are made explicit. The type of feedback-induced revision is determined by which component of the regulatory state is changed.
| Construction or revision type | Loop | Feedback signal / trigger | Revision target | Cybernetic interpretation |
|---|---|---|---|---|
| Staged selection trace | L1 | Selection signals | Candidate response-set | The regulator narrows possible responses within one episode. |
| Closure | L1 terminal output | Commitment of | Realized outcome-value | The episode closes when a committed response produces an outcome. |
| Behavioral revision | L1 re-engaged | Prior closure evaluation or invalidation | Response rule | Feedback changes what response rule the regulator uses. |
| Learning | L2 | Closure-valuation, evidence stream, and retained episode information | Stored law of action | Feedback changes the stored coupling used in later comparable episodes. |
| Learning success criterion | L2 | Across-episode reduction of conditional entropy | Residual Knowledge To Be Discovered | The next comparable episode starts with less response-class uncertainty. |
| Criterion revision | L3 external goal-revision form | Exogenous change in the authoritative acceptable region | Feedback or external change revises the criterion of success. | |
| Acceptability deletion, addition, and weak substitution | L3 external goal-revision form | Change in | Pullback acceptable outcome-set | Fixed outcome-values gain or lose acceptability; they are not deleted from . |
| Strict substitution | L3 external goal-revision form | Criterion revision plus replacement pairing supplied by the model | Replacement correspondence | The model specifies which lost acceptable value is replaced by which gained value. |
| Goal-model revision | L3 goal-model form | Checking evidence against the authoritative acceptable set | Believed acceptable region | Feedback changes the regulator's model of the goal, not the authoritative goal itself. |
| Model-revision event | L3 goal-model form | Authoritative checking or mismatch evidence | Model revision event | The believed loss and gain sets are induced by revising the goal model. |
| Corrective replacement | L1 re-engaged after L3 | Invalidation of an earlier closure | Repair relation | A later closure is treated as repairing an earlier invalidated closure. |
| Structural adaptation | Higher-order adaptation beyond the fixed-table case | Persistent failure or insufficiency of the existing regulatory frame | Feedback changes the system structure or the available regulatory repertoire. |
The present fixed-table formulation allows behavioral revision, criterion revision, goal-model revision, and learning while holding , , , , , and fixed. Structural adaptation is a stronger case and should be modeled separately.
The operational ledger as feedback memory
The operational ledger records the closure history produced by L1. It preserves closure events after their production, allowing the system to evaluate not only whether a closure was acceptable when produced, but also whether it continues to survive later criteria, later model revisions, or later authoritative checking.
Let the operational ledger up to time be the time-ordered history of recorded closure events:
The ledger answers the accounting question: which closures were produced, which survived, and which were invalidated? The feedback-loop formulation answers the question: which part of the regulator changed because closure evaluations were fed back into the system?
A feedback signal is generated when the ledger is evaluated against some current or authoritative criterion. In the external criterion-revision case, a prior closure may be invalidated because:
In the goal-model-revision case, a prior provisional closure may be invalidated because:
These facts are ledger-visible feedback signals. They become revisions only when they are used to change some component of the regulatory state. Thus the ledger supplies feedback memory, but it does not collapse invalidation, learning, and repair into the same event.
The operational ledger as cross-loop bookkeeping
Under this reading, the operational ledger is bookkeeping over L1's closure history after L2 and L3 events inside the window have had their effects. Each ledger quantity has a loop interpretation.
The gross counted closures and the gross provisional closures count L1 outputs admitted under the criterion or believed criterion prevailing at production time. They are work-counts of closure-fixing acts.
The invalidation load counts L1 closures that L3, in its external goal-revision form, later invalidated by changing somewhere in the window.
The goal-model invalidation load counts L1 closures that L3 (goal-model form) later invalidated by revising against the fixed authoritative . Both are L3-attributable invalidations of prior L1 work.
The surviving counted closures and the net surviving closures count L1 closures that were not invalidated by the relevant L3 process within the window.
The two ledger identities therefore have direct loop readings:
The first says that total accepted L1 output equals L1 output that continuously survived plus L1 output later invalidated by criterion revision. The second says that total provisional L1 output equals authoritatively surviving L1 output plus L1 output invalidated by goal-model mismatch.
Neither identity is an entropy identity. Both are operational accounting identities. They count closure-fixing acts, not bits of Knowledge To Be Discovered.
The ledger therefore answers a question that none of the three loops answer in isolation: over a window, how much of L1's produced closure history was preserved, and how much was retroactively invalidated by later criterion or model evaluation?
Invalidation, repair, and corrective rework
The ledger can show that a closure was invalidated, but invalidation is not the same as corrective rework. Invalidation is a feedback signal. Corrective rework requires a later behavioral event that repairs, replaces, or compensates for the invalidated closure.
Thus a feedback-induced corrective replacement requires additional structure beyond the invalidation count. If is an invalidated closure and is a later closure, introduce a repair relation:
This means that the later closure event is treated as the corrective replacement for the earlier invalidated closure . The relation is not determined by the ledger alone. It is additional modeling structure that identifies which later closure repairs which earlier invalidation.
At minimum, a repair relation should satisfy: and is invalidated and is accepted under the relevant criterion.
For a goal-model-revision ledger with fixed authoritative acceptable set, this can be written more specifically as:
In the typing example, a natural repair relation may also require that both closure events address the same target position:
The full feedback sequence is therefore:
closure → ledger record → evaluation → feedback signal → revision → possible corrective closure.
This is the cybernetic role of the operational ledger: it makes closure history available for later feedback, but it does not collapse invalidation, learning, and repair into the same event.
Time-scale separation and loop interaction
The three loops are separated by characteristic time scales, in the cybernetic tradition of nested adaptive control[1][7][57]. L1 operates within a single episode and terminates with a closure. L2 operates across consecutive comparable episodes within a window. L3 operates on an episodic-to-rare time scale, depending on whether the trigger is an exogenous goal change or a discovered model mismatch.
Because L3 acts outside the immediate L1 closure event, an L3 event inside a window can retroactively rewrite the acceptability-status of L1 closures already produced. This is why the operational ledger must track not only gross production count but also survival count under the criterion history or authoritative checking structure of the window.
Because L2 acts between L1 episodes, an L2 update changes the prior structure of the next L1 episode. It does not, by itself, change the status of past closures. Therefore and are L3-attributable invalidation loads, not L2 learning measures.
Loop interaction is still possible. An L3 invalidation may become an error signal for L2: a closure that ceased to count under a revised criterion provides evidence that the stored coupling was aligned with the old criterion or the old believed model, not with the revised one.
Conversely, repeated L2 success may reduce the need for L3 in the goal-model-revision case by bringing the regulator's believed model into alignment with the authoritative criterion. This cross-loop coupling matches Ashby's observation that the adaptive loops of an ultrastable machine interact, with the slow loop reorganizing the structure on which the fast loop operates[1][7].
The present formulation models these loops as negative-feedback loops on their respective error signals. Positive-feedback dynamics — such as exploratory expansion of the candidate set, variety-amplifying changes to the stored law of action, or deliberate broadening of the believed acceptable region — would require explicit additional structure and are not part of the fixed-table formulation developed here.
Summary
Read as a feedback-loop system, the formal model has three loops. L1 selects responses within an episode and closes it. L2 updates the stored law of action across comparable episodes and is evaluated by the learning axiom. L3 revises the criterion of success, either exogenously through external goal revision or endogenously through goal-model mismatch discovery.
The operational ledger is the cross-loop bookkeeping that records how L1's closure history was preserved or invalidated within an observation window. It is not itself the feedback loop. It is the memory trace that allows later evaluation, feedback, revision, and possible repair.
This reading does not introduce new formal objects. It names the cybernetic role of each construction already defined above and exhibits the regulatory model as a nested loop hierarchy in the sense of Ashby's adaptive machine and its successors[1][7][57].
Quantifying the Knowledge Discovery Process
We estimate a non-physical latent information quantity from physical counted units, with calibration/bridge error handling the gap between counted physical action units and ideal information-reduction units.
From latent ignorance to operational measurement
The preceding sections defined the Knowledge Discovery Process in two related ways. Inside a regulatory episode, it is the staged reduction of Knowledge To Be Discovered. Across comparable episodes, it is the retained reduction of Knowledge To Be Discovered in the regulator's stored law of action. Those definitions are information-theoretic. They refer to quantities such as , where is the required response-equivalence class and is the disturbance information available to the regulator.
These latent quantities are not directly observable under a strict black-box measurement regime. The observer does not see the regulator's internal probability model, posterior distribution, candidate set, search path, binary questions, or elementary narrowing operations. In particular, the observer does not directly observe as a count of internal knowledge-seeking actions. The primitive observation is only the external closure ledger.
For a completely black-box observer, the observable data in an observation window are closure events, timestamps, and invalidation events. That is, the observer can record which closure commitments occurred, when they occurred, and which previously recorded closures were later invalidated. If the ledger supports it, an invalidation may also identify the closure that it invalidates. No assumption is made that the observer can see the cognitive or physical actions that occurred between closures.
The operational bridge therefore begins not with observed non-closure action units, but with a declared unit convention. The unit length is anchored to the closure act. Let denote the normalized duration of one closure-act-equivalent unit. Once is fixed, the capacity of the observation window is fixed as the number of closure-act-equivalent units available in that window:
Equivalently, is the maximum closure-act-equivalent capacity of the window: the number of normalized closure opportunities available if every closure-act-sized interval were converted into a surviving closure. For discrete ledgers, one may use the integer convention ; for rate-based ledgers, the fractional convention above is usually cleaner. In either case, is not inferred from hidden search behavior. It is fixed by the observation-window convention and the closure-act unit.
The observed closure side of the ledger is then separated from the capacity side. Let be the number of gross closure events recorded in the window, and let be the number of those closures removed by invalidation under the ledger's validity rule. The net surviving closure count is:
The residual term is now determined by accounting, not by direct observation. The effective residual discovery load is the closure-equivalent capacity that was not converted into surviving closures:
This is the key observability distinction. is observed from the closure ledger. is fixed by the declared closure-act capacity convention. is inferred as the residual term required by the ledger identity. It should not be described as an observed count of hidden knowledge-discovery actions.
Because the closure-act unit is anchored to the closure act itself, no two recordable closures can fall within the same closure-act-equivalent unit. The window therefore cannot contain more surviving closures than it contains closure-act-equivalent slots, so holds by construction of the convention, and the residual is a well-defined nonnegative missing-capacity term. If a coarser unit is declared, so that a single closure-act-equivalent interval could contain several recordable closures, this nonnegativity must be checked rather than assumed.
The resulting operational estimator is therefore:
This quantity is operational rather than ontological. It does not claim that the regulator literally performed internal binary operations. It says that, relative to the declared closure-act capacity of the window, the process consumed that many closure-equivalent units without producing surviving closures. The missing capacity is then read as an effective discovery burden.
Assumption A5 supplies the final interpretation bridge. Write for the latent window-level Knowledge To Be Discovered — the realized estimand defined above. Under A5, the inferred residual is treated as a one-bit-equivalent closure-equivalent code length for that latent quantity. The latent informational content is therefore not identified with the residual count. It is related to it by a signed decomposition:
The analogy is source coding. Entropy gives a lower limit on the average description length required by an ideal code, while an actual prefix-free code supplies a concrete description length that may exceed that limit. In the same way, is not the latent entropy itself. It is the effective closure-equivalent description cost implied by the black-box ledger. Here denotes the source-coding gap between latent entropy and effective description length, and is nonnegative, , in the manner of coding redundancy; denotes the calibration error introduced by the chosen closure-act unit, window boundary, and validity rule, and may take either sign, since a declared unit can systematically over- or under-charge relative to the effective selection actually produced.
Consequently, in the well-calibrated, stable-task regime — where the coding and calibration terms are jointly nonnegative, — the inferred residual is an upper bound on the latent Knowledge To Be Discovered:
The stricter the unit convention and the more stable the task class, the smaller these gap terms and the tighter the bridge. If the capacity convention is loose or inflated, grows and the estimator remains computable but becomes a conservative upper-bound reading of latent Knowledge To Be Discovered. Outside this regime the signed decomposition above still holds as an equality; only the one-sided bound is relinquished.
The measurement chain is therefore:
This preserves the black-box promise and the effective KTD estimator can be computed from closure timestamps, invalidations, and a declared closure-act capacity convention. They do not require direct observation of the regulator's internal search process.
Latent window-level estimand
For the operational ledger, the relevant latent quantity is the realized row-level Knowledge To Be Discovered , evaluated at the disturbance information actually observed for closure , and not the ex-ante conditional entropy averaged over all possible observation states.
The knowledge ledger's is the expected stored-coupling quantity used in the learning and stock-flow identities. The quantity needed here is its realized counterpart at the observed :
Here is the required response-equivalence class and is the realized disturbance information available to the regulator at the start of episode .
The two quantities are linked. For a fixed knowledge state , the expected conditional entropy is the -average of the realized posterior entropies:
Consequently, when the knowledge state is stable across the window and the realized observations among the net surviving closure population are representative of the relevant -induced marginal distribution on , the row average of is an unbiased estimator of the common expected quantity . Where the knowledge state drifts or the realized disturbance mix is atypical, the two diverge, and the realized average — not the expected one — is what the operational construction below targets.
The operational ledger determines which closure events survive as accepted closures in the window. Let the net surviving closure history be:
The corresponding net surviving closure count is:
In this section, denotes the surviving accepted closure count under whichever operational ledger case is being used. In the external criterion-revision ledger, corresponds to . In the goal-model-revision ledger, it corresponds to the authoritative net surviving count already denoted .
The knowledge ledger attaches a knowledge row to each closure event . Define the knowledge-ledger rows joined to the net surviving closure history:
The latent realized average starting Knowledge To Be Discovered for surviving closures is therefore:
(2)
This is the latent estimand for the operational construction. It is an average conditioned on the operational event class “surviving accepted closures.” It is not the entropy of a pooled window-level variable, and it is not yet an operational count.
It is the realized counterpart of equation (1), which averages the expected starting Knowledge To Be Discovered over all possible observation states for the window, whereas equation (2) averages the realized posterior ignorance over the same surviving closures. The two coincide only under the stationarity and representativeness condition stated with equation (2); in general the operational construction below targets the realized average , not the expected average of equation (1).
Ergodic reconciliation of realized and expected KTD
Equations (1) and (2) differ only in whether the per-row conditional entropy is the ensemble quantity averaged over the disturbance law or the realized quantity at the observed disturbance-value. Their coincidence is therefore not automatic: it is an ergodicity condition on the disturbance process restricted to the comparable task class.
Assume the knowledge state is stable across the window, for all in the window. Define the empirical disturbance distribution induced by the net surviving closure population:
Under stability of , the realized latent average of equation (2) is exactly the empirical -average of the realized posterior entropies:
whereas the expected quantity of equation (1) is the same functional evaluated at the model-induced marginal :
Subtracting, the realized–expected gap is a reweighting error driven entirely by the mismatch between the empirical and model-induced disturbance distributions:
Assumption E — Disturbance ergodicity. The disturbance process restricted to the comparable task class is stationary and ergodic over the window, so that the single-trajectory empirical disturbance distribution over the net surviving closures converges to the model-induced ensemble marginal:
Under Assumption E the reweighting error vanishes in the large-window limit, and the realized average of equation (2) is a consistent estimator of the expected average of equation (1):
Absent Assumption E — if the knowledge state drifts, or the realized disturbance mix over the surviving population is not representative of — the two averages diverge by the reweighting error above, and the operational construction below targets the realized average , not the expected average of equation (1).
This realized estimand is latent: under black-box observation we do not see the internal stages of an episode, we do not see the regulator's knowledge state , and we do not see the per-stage selection signals . What we do see is the externally visible execution channel — closure events and the generic action units between them — together with the operational ledger that records which gross closures survived as net accepted closures inside the window.
Ideal binary-question-depth layer
The remaining uncertainty in a closure is latent: it concerns the response-equivalence class that would have to be selected for the realized disturbance, but that class is not directly observed as a visible work item, question, or decision step. To make this latent uncertainty operational, we need a bridge from entropy to ideal inquiry effort.
Lemma 1 — One-bit coding bracket. For each realized episode u, let the posterior distribution over required response-equivalence classes after the realized disturbance information is observed be:
Let denote the minimum expected number of binary yes/no questions required to identify X under this posterior distribution. Equivalently, is the expected depth of an optimal binary decision tree for . Assume the posterior support of X under is finite, or countable with finite entropy, so that the standard binary source-coding bracket applies.
In this lemma, a question means one binary distinction, ideally a yes/no distinction, used to reduce uncertainty about the required response-equivalence class. Question depth is the number of such binary distinctions needed along a particular inquiry path. Expected question depth is the average number of binary distinctions required under a probability distribution over possible response classes. Thus, question depth is literally the number of questions only in the ideal binary-question model
Then the optimal expected binary-question depth is bracketed by the posterior entropy within one bit:
Here, the per-row posterior entropy is exactly evaluated at the realized .
In the special case where the posterior distribution is uniform over 2m equiprobable response classes, the bracket is tight: . For example, if a coin is hidden in one of eight equally likely boxes, then , and the optimal binary-question strategy identifies the box in exactly three questions.
Averaged over the net surviving closure population in window I , the corresponding ideal-depth benchmark is:
(3)
where denotes the average ideal binary question depth over net surviving closures in window I.
Equation (3) is the latent-to-ideal bridge. It says that the average optimal binary-question depth over net surviving closures brackets the latent realized average Knowledge To Be Discovered within the standard sub-one-bit source-coding gap. It is purely information-theoretic. It does not yet involve any observable execution counts, and it does not yet say that the observed execution trace followed an optimal binary-questioning procedure. That stronger reading enters only through the ideality assumptions stated below.
Proof. The result follows from the standard source-coding interpretation of entropy: an optimal binary decision or coding procedure has expected length at least the entropy and less than entropy plus one bit. Averaging this per-row bracket over the net surviving closure population preserves the inequalities.
The bridge says that the posterior entropy is not merely an abstract measure of missing knowledge; it is the idealized binary-question complexity of identifying the required response-equivalence class, up to the standard one-bit gap. Lemma 1 establishes this connection, allowing to be interpreted as the average amount of knowledge that still had to be discovered per net surviving closure.
Execution channel
We have already quantified the amount of knowledge to be discovered in terms of the average ideal binary-question depth over net surviving closures. In order to quantify regulator's efficiency, we now need to quantify the time available.
If we are able to count the number of action units Q directly, then we can measure Qeff without any additional assumptions. In this case, durations may differ. The count is event-based, not durations-dependent.
Durations do not enter the information ledger. The amount of response-relevant selection is invariant to whether the selection trace is executed quickly or slowly. However, durations matter when 1) we need to quantify the time available, and 2) the number of action units Qeff is inferred from elapsed time rather than directly observed as a sequence of counted action units.
We introduce a generic action unit type alphabet and tile the window I into ordered generic action units a, each carrying a type and a duration . A generic action unit is one of three kinds: a non-closure action unit Q, a closure unit S, or an fedback unit F. The first two have already been introduced. Fedback units are capacity that goes neither into discriminating the next response nor into committing one: physical unfolding, feedback latency, waiting, or idle observation.
Every episode terminates in exactly one closure. The closure is the final response commitment after which the episode ends. The response has been selected and released into the world where the table of outcomes T produces the result z. This act is binary in form: at each moment the episode is either not yet closed or closed by commitment. It is not characterized by its information content, which is generally the residual selection entropy at the moment of commitment. What individuates the closure as a single countable act is that it is a discrete, time-bounded commitment, with an onset at the moment of commitment and completion when is produced. The closure duration is the commitment duration, not the post-closure physical execution or waiting interval. The closure time defines a generic action unit, while the post-closure physical execution or waiting interval is feedback time: feedback latency, idle observation, or physical unfolding.
We define the execution channel as a physical trace through which knowledge-discovery work becomes observable. The channel capacity is measured in counted generic action units, not in elapsed time. A generic action unit is one unit of execution-channel capacity capable of supporting either one closure commitment or one non-closure discrimination step.
The central object in this channel is the total number of counted generic action units consumed in window . Then elapsed time supplies a physical trace, but it does not by itself determine how many counted non-closure units, closure units, or fedback units the trace contains. The same stretch of behavior admits more or fewer units depending on the grain at which it is segmented, just as the entropy of a behavior depends on how finely its actions are distinguished. This number becomes a fixed count only after a unit convention has been chosen.
If is estimated from the length of the observation window, then an additional temporal calibration is required. A duration-to-count rule is needed to map time into counted channel capacity. A unit convention must therefore be declared before is fixed. Before that convention is fixed, the question “how many units occurred in interval ?” is underdetermined.
Therefore, the execution channel will be read in two layers, and the order matters. The first layer is unit-convention constitutive: it fixes what counts as one generic action unit, and thereby fixes both the channel capacity and the partition of that capacity into closure, non-closure, and fedback units. The second layer is accounting: once units are defined, is a fixed tally, and every accounting identity operates on that fixed counted-unit ledger, independently of how the units are spread in time.
The accounting layer is duration-free: the identities count units, not time. The count itself, however, is not duration-free, because the choice of unit convention — in particular the time-normalized convention below — can make a unit's identity depend on elapsed time. Duration therefore does not enter the ledger; it enters the convention that constitutes the ledger.
Unit-convention layer
The unit-convention layer is constitutive. It declares what counts as one generic action unit. This layer is logically prior to every execution identity, because it constitutes both the total count and the type partition of units into closures, non-closures, and fedback.
Formally, let denote the observed work trace over interval . A unit convention maps this trace into a finite sequence of generic action units and a type map:
where is the th generic action unit and assigns each unit to exactly one execution type:
The convention therefore constitutes the counted sequence:
Three unit conventions are admissible, at increasing remove from the raw trace:
Observed action-unit convention takes the trace as already segmented into discrete acts. A generic unit may only be a directly observed closure, timestamp or invalidation observable: a code edit, a test run, a command, a review act, a debugging step, a design decision, a keystroke, a button press, a committed response, or another task-relevant act identified by the observation protocol. Units are counted as events; their durations may differ, and no temporal-normalization rule is required. In this case, is obtained by direct counting. No temporal inference is required.
Task-relevant bin convention. lets the task supply the natural grain: a generic unit may be constituted by partitioning elapsed time into bins of width and then retaining only distinctions that matter to the task i.e two distinct keystrokes are two actions, while sub-threshold variation in how a single keystroke is struck is noise, not a further unit. Units remain event-like, but their boundaries are justified by the task rather than inherited from the time trace. Let denote the task-relevant action variable in bin , and let denote the available context for that bin: the task, goal state, prior action history, local constraints, and current work state. The response-relevant uncertainty contributed by the bin is then represented by:
The point of binning is not to count every physical or biomechanical variation. Tiny differences that do not change task performance are noise relative to the task. The unit convention should therefore refine until task-relevant distinctions stabilize, and stop before the observer begins counting irrelevant variation. A useful stabilization condition is:
where denotes the response-relevant information accounted for under bin width , and is an accepted tolerance. This condition says that making the bin smaller should not materially change the task-relevant accounting. If further refinement only captures irrelevant noise, the bin is already sufficiently fine for the execution ledger.
Time-normalized unit convention tiles the window into fixed intervals of length and counts each interval as one normalized generic unit of execution capacity. Let be the duration of action unit , and let be the reference duration of one normalized execution unit. The normalized number of bins occupied by task-unit is:
and the corresponding time-normalized count is:
Here is simultaneously a count and a duration, and a temporal-normalization rule is mandatory.
If the execution channel must remain an integer tally, the normalized convention can be implemented by aggregating raw time bins into one-reference-unit equivalents. The expression above states the normalization rule; the ledger then records the resulting constituted units.
These conventions trade off against one another. Observed and task-relevant units make each unit information-rich but duration-heterogeneous: a unit may carry several bits of response-relevant discrimination, but two units need not occupy equal channel time. Time-normalized units make duration homogeneous by construction, so that closure and non-closure units are automatically commensurable, at the cost that most units carry near-zero conditional information — a single task-act now spans many -units, most of which only continue an already-determined motion.
Under a time-normalized convention the rule must in particular fix the duration assigned to a closure unit. If a closure occupies exactly one , then a closure tally and a non-closure tally are denominated in the same unit and may be added directly.
Time trace
Each generic action unit may have a different length . The emission of a response-value at the end of a selection trace may also have a different length. The count and the dwell time are two different aggregates of the same tiling. Under an observed or task-relevant convention they diverge by the duration heterogeneity of the units; under a time-normalized convention they coincide up to the fixed factor , and the equal-cost convention of the accounting layer holds by construction.
Equal-duration case
The equal-duration case is the special case in which every task-unit spans the same number of bins. Let be the number of bins occupied by task-unit :
At unit resolution, the equal-duration assumption is:
Under this special case, count and duration/bin coincide:
More generally, durations may vary. If elapsed time is used to infer a counted-unit tally, the observer must assume that unit durations are stable enough for a long-run average to be meaningful. If the sequence of unit durations is stationary and ergodic, then:
and elapsed bins can be converted into an expected counted-unit tally:
The strongest form of the operational estimator assumes equal counted-capacity charge across execution types. If closures, non-closures, and fedback have different duration distributions, elapsed bins satisfy approximately:
The equal-charge case is:
The exact equal-duration case is the degenerate case in which the duration distribution has zero variance and the same duration for every execution type. When this does not hold, the temporal-normalization mismatch is not a failure of the execution identities. It is an error in using elapsed time as a proxy for counted execution capacity. Such error is handled later as part of the operational error envelope.
Accounting layer
The accounting layer is combinatorial. Once a unit convention has been fixed, the execution sequence is no longer underdetermined. The interval contains a fixed tally of constituted generic action units, and each unit belongs to exactly one execution type. In this layer, durations no longer appear. Duration has already done its work upstream by helping constitute the unit convention.
Dropping the convention subscript when the convention is clear, let:
where is the set of closure units, is the set of non-closure units, and is the set of fedback units. The symbol denotes disjoint union.
Let denote the fixed generic action unit capacity of window : the total number of counted generic action units consumed in the window. It is held fixed throughout, and the question is only how that fixed capacity is partitioned.
The corresponding counts are:
Therefore the execution-channel partition identity is:
This identity is duration-free. It is not a claim that all physical actions take the same wall-clock time. It is a claim that, under the chosen unit convention, each constituted generic action unit contributes one counted unit to the execution ledger.
The effective non-net-progress load remains the physical non-closure count augmented by the invalidation debit:
The inflation of above is therefore exactly the observable invalidation load , and nothing else. Fedback is never folded into : a setup or idle unit is not a failed discrimination attempt, and charging it as one would misattribute non-progress.
Re-booking the invalidated closures from the closure side to the load side is a pure re-attribution, so the following identity holds in every window, with or without fedback:
The full capacity, however, may exceed this common value by the fedback it contains. The general capacity partition has three buckets — effective non-net-progress load, net surviving closures, and fedback:
Equivalently, using the re-attribution identity above:
The fedback bucket is therefore the residual capacity left after discrimination work and closures are accounted for:
Fedback units exist, occupy the generic action unit capacity, and consume time, but they carry no response-relevant discrimination and produce no closure.
These identities are tallies and hold for any unit convention and any assignment of durations . One further reading, however, is not free of the convention. Reading the ratio as an effective depth per closure, and summing in a common load, additionally charges one closure unit at the same channel cost as one non-closure unit. Under the count partition this equal-cost convention is automatic; under any time- or effort-weighted reading it is an assumption and it is exactly the closure-unit-duration choice fixed in the unit-convention layer above.
Operational assumptions
The operational construction uses a fixed observation window:
The following assumptions define the operational measurement model. They are not epistemological claims about how the regulator thinks. They are coding assumptions about how the externally visible execution trace is counted.
Assumption A1 — Fixed counted channel capacity. The observation window has a fixed counted generic action capacity . This is the total number of counted generic action units available and consumed in the window.
Assumption A2 — Immediate fedback. The observation window contains only non-closure action units and closure units, with no fedback units: . Thus, every counted generic action unit is classified as exactly one of two types: a non-closure action unit or a closure unit. No counted unit belongs to both classes.
Assumption A3 — Net survival. The net surviving closure count equals the number of gross closures that remain accepted under the relevant window-level evaluation rule. Gross closures that fail to survive consumed capacity but do not contribute to net accepted closure output.
Assumption A4 — Closure counting. Each gross closure event consumes one closure unit when produced. A gross closure may later survive as accepted or be invalidated by the relevant evaluation criterion.
Under A1-A4, the operational identities below are exact. They do not require access to the regulator's internal knowledge state , to posterior probabilities, or to the internal order of staged selections inside an episode.
Defining the unit length from the closure act
We adopt the time-normalized unit convention, which tiles the window into fixed intervals of length and counts each interval as one normalized generic unit of execution capacity.
Under a time-normalized convention, the counted capacity is fixed only after the unit length is fixed. The question is therefore not how many units occurred in the window, but how long one unit lasts. We fix by anchoring it to the closure act, and then refine that anchor by the calibration procedure. Throughout, the unit length is held constant across all closures in the window.
The unit length is the closure-act duration
Let the duration of one closure commitment act be . This is the natural unit-anchor for the channel, just as the keystroke is the unit-anchor for a typing trace: it is the task-defined act that closes one unit of regulatory work.
Set the unit length equal to the duration of one closure commitment act:
Under this convention a closure occupies exactly one by construction. This is not an assumption about closures. It is the choice of clock: the channel is measured in units of one commitment act. By the constant-unit-length assumption, is taken constant across all closures in the window, up to noise, so that is a single value for the window and the count and the elapsed time of the channel are related by:
Non-closure units inherit the same length
A non-closure action unit is then defined as one of pre-commitment selection activity, at the same temporal grain as the closure unit. Because both a closure unit and a non-closure action unit occupy exactly one , the closure tally and the non-closure tally are denominated in the same unit and add directly in .
This commensurability is a statement about duration only. It licenses the count, and is independent of how many bits either act carries. In particular, the invalidation re-attribution adds a non-closure count to a closure count, which is dimensionally honest precisely because each summand is a tally of one- acts. The information content of a closure — generally its residual selection entropy at the moment of commitment, not a fixed one bit — is charged separately under the one-bit reading convention (A5), and its departures are absorbed into the calibration error.
The calibration procedure fixes the closure length
The closure length is not a single number read off the trace. For any physical task it is recovered from experiment as a distribution over observed commitment durations, with a mean, a spread, and possibly a tail. The calibration procedure has two jobs: to certify that this spread may be treated as noise, and then to collapse the distribution to the single constant value used as .
Certification. The spread of may be treated as noise — and the constant-unit-length assumption thereby justified — only if no response-relevant discrimination is carried across that spread.
Operationally, segment the trace at a resolution and charge each bin its conditional information increment , where is the context already available before the action in that bin. The spread is noise when no further conditional information about the required response-equivalence class is gained within the closure act:
A closure that took longer did not, under this condition, resolve more of the response than one that took less; the duration difference is task-irrelevant variation, exactly as a difference of a few milliseconds between two otherwise identical keystrokes is noise rather than a distinct action. Where the condition fails — typically in the tail, where some commitments run long because late selection has leaked into the closure window — the closure boundary was mis-identified for those episodes. The remedy is not to widen but to re-segment those episodes, moving their late selection out of the closure and into non-closure units. This tightens back toward a noise-only spread and makes the constant-unit-length assumption self-consistent rather than imposed. Zheng and Meister emphasize that behavioral information estimates depend on binning and on distinguishing task-relevant action differences from irrelevant noisy variation; tiny differences such as a 91 ms versus 92 ms keystroke are ignored because they do not define different task actions[58].
Collapse. Once the spread is certified as noise, the distribution is collapsed to a single representative value taken as the channel unit:
where is a summary statistic of the observed duration distribution. The model does not mandate a particular : the choice of mean, median, mode, or another statistic is a modeling decision left to the practitioner applying the model to a specific task. The choice does, however, carry an interpretive consequence that the practitioner should record. Only the mean, , makes the count and the elapsed channel time agree in expectation, so that tracks total elapsed time; a robust statistic such as the median trades that exactness for insensitivity to the tail. The practitioner selects according to which property the application requires.
The procedure therefore has two outputs from a single mechanism. The conditional-information check certifies the closure boundary and licenses the constant-unit-length assumption; the chosen summary statistic fixes and the unit length of the whole channel. Within the selection region the same conditional-increment estimator is refined toward the entropy-rate estimate, driving the calibration error toward zero.
Operational action-unit layer
The ideal binary-question-depth layer concerns the minimum expected number of binary distinctions required under an ideal questioning scheme. The operational layer concerns what was actually counted in the execution channel. Under A1-A4, the execution stream is partitioned into counted non-closure action units and gross closure units.
Proposition 1 — Channel partition identity. Under A1–A2, the channel capacity is exhaustively partitioned into non-closure action units and gross closure units. With the capacity held fixed and the gross closures counted, the non-closure count is therefore not a free quantity: it is forced to be the residual capacity left after the closures are counted:,
This is a pure accounting identity: on a single fixed-capacity channel, every counted unit is either a non-closure action unit or a gross closure unit, and counts the former by tallying action units, with no recoding.
Proof. By A2, every counted unit is either a non-closure action unit or a closure unit, . By A4, gross closures are the closure units. Equivalently the fedback count vanishes, so the fixed capacity is exhausted by discrimination work and closures: Therefore the non-closure count equals total counted capacity minus gross closure count.
The black-box constraint matters here: under this observation model we can attribute each atomic unit to either the closure stream or the non-closure stream, but we cannot see the internal staged structure inside an episode.
The execution channel makes and observable; the operational ledger then makes and observable as well.
Observable invalidation load and net surviving closures
For the quantification below, the relevant observable invalidation load is the gross closures in window I that fail to survive as net accepted closures.
By A3:
This identity is operational, not entropic. It partitions gross closure work into net surviving closure work and observable invalidation load.
The counted channel capacity is held fixed throughout. Under A1–A2 and A4, the physical unit count of the channel admits exactly one physical partition into generic action units, namely Proposition 1:
In this partition each of the invalidated closures is counted once, as a consumed gross-closure unit inside . The invalidated closures are real units; they occupy capacity on the channel.
The effective non-net-progress load in window is:
is not a count of channel units. It is the physical non-closure count augmented by a one-unit non-progress debit for each invalidated gross closure. By construction , with equality if and only if ; whenever invalidation occurs, strictly exceeds the number of non-closure units actually present on the channel.
Combining the definition with :
So the same fixed capacity admits a second, effective partition:
The two partitions of differ only in the bookkeeping of the invalidated closures, and itself is unchanged.
Operational one-bit effective-depth estimator.
Proposition 1 and the channel partition identities require only the pure accounting assumptions. The interpretation of the resulting ratios as latent information-theoretic KTD additionally requires Lemma 1 and B1–B4 later on.
The residual is not an observed count of non-closure action units. Under the strict black-box regime the observer never sees the regulator's internal probes, candidate sets, or elementary narrowing steps. The two primitive quantities are the closure-act capacity of the window, , fixed by the declared unit convention, and the net surviving closure count , read from the closure ledger. The residual is then inferred by the ledger identity:
Assumption A5 — One-bit effective upper-bound convention. Write for the latent window-level Knowledge To Be Discovered — the realized estimand defined above. Under A5, the inferred residual is treated as a one-bit-equivalent closure-equivalent code length for that latent quantity. The latent informational content is therefore not identified with the residual count. It is related to it by a signed decomposition:
The analogy is source coding. Entropy gives a lower limit on the average description length required by an ideal code, while an actual prefix-free code supplies a concrete description length that may exceed that limit. In the same way, is not the latent entropy itself. It is the effective closure-equivalent description cost implied by the black-box ledger. Here denotes the source-coding gap between latent entropy and effective description length, and is nonnegative, , in the manner of coding redundancy; denotes the calibration error introduced by the chosen closure-act unit, window boundary, and validity rule, and may take either sign, since a declared unit can systematically over- or under-charge relative to the effective selection actually produced.
Consequently, in the well-calibrated, stable-task regime — where the coding and calibration terms are jointly nonnegative, — the inferred residual is an upper bound on the latent Knowledge To Be Discovered:
The stricter the unit convention and the more stable the task class, the smaller these gap terms and the tighter the bridge. If the capacity convention is loose or inflated, grows and the estimator remains computable but becomes a conservative upper-bound reading of latent Knowledge To Be Discovered. Outside this regime the signed decomposition above still holds as an equality; only the one-sided bound is relinquished.
This is a coding-cost convention, not an equality claim about latent entropy. The true latent information-theoretic KTD may be smaller than the inferred residual, just as the entropy of a source is a lower bound on the expected length of an actual prefix-free description.
A5 is the convention by which each unit of this inferred residual — each closure-act-equivalent unit of window capacity that was not converted into a surviving closure — is read as one binary-question-equivalent of knowledge-discovery burden. A5 recodes nothing that was observed; it assigns a standardized reading to a quantity that is obtained by subtraction.
Each closure-act-equivalent unit of the residual is charged as one binary narrowing step — one probe that would evenly split a live candidate set and discard one side, in the manner of one step of dichotomy search. The count-variety value of a single even split is one bit:
The candidate set appears here only as the idealized interpretation of what a residual unit would correspond to if it were realized as one even split. It is an interpretive reference, not ledger data: the operational construction never reconstructs it, and A5 does not require it to exist as an observed sequence.
Because the charge is anchored to the fixed capacity rather than to observed actions, A5 does not re-count uneven or -way splits as several units, and does not drop residual units that would narrow a live set not at all (the epistemically-null case). Instead, the discrepancy between the one-step charge assigned to each residual unit and its true binary-question content is carried, in aggregate, into the calibration error introduced in B1.
Count and time aggregation coincide by construction here. Because , counting residual units is the same as counting closure-act-sized intervals of wall-clock time rescaled by the constant . We do not need stationarity, a stable distribution, or mixing.
A5 is therefore a purely combinatorial reading convention on the inferred residual. It invokes neither a probability model over the required response-equivalence class nor entropy, and its only genuine assumption (not a definition) is that charging each residual unit as one even split is exact only for even splits, with all deviation absorbed by . This is what lets serve as a one-bit-equivalent code length — an upper-bound reading — for the latent Knowledge To Be Discovered, with the gap treated separately by calibration.
Definition (Fixed-gross no-invalidation baseline). The baseline is a contrast operator on observables, not a causal counterfactual. Hold fixed the observed channel capacity and the observed gross closure count fixed, and set the observable invalidation load to zero, , so that . The baseline question depth per closure is then the average number of non-closure atomic units per gross closure:
(4)
The baseline reads the physical partition of the channel, which counts the invalidated closures as closures. Because it is defined by fixing observables and zeroing the invalidation load, equation (4) is exact as an operational count by construction. It is not a counterfactual estimate of what would have happened absent invalidation; it is the value of the same operational ratio evaluated at . This removes any need to defend the baseline as a causal alternative, and it supplies the fixed-gross reference against which the effect of observable invalidation load is measured below.
The effective question depth means the estimated average number of one-bit-equivalent action units per surviving closure. The operational one-bit estimator for average effective question depth per net surviving closure is:
(5)
The net estimator reads the effective partition of the channel, which counts the invalidated closures as load. By construction, it is also exact as an operational count. Equation (5) is exact as an operational estimator of average effective one-bit action-unit depth. For the estimator to be defined, the relevant window must satisfy: , , , and .
Both partitions of the channel divide the same fixed ; they differ only in whether the invalidated closures are counted as closures (baseline) or as load (net estimator).
A5 as the Even-Split Operational Convention
Assumption A5 is an operational accounting convention. It assigns one one-bit-equivalent charge to every inferred residual unit of :
This assignment does not assert that any physical action is literally a binary question, that any step eliminates exactly half of some live alternative set, or that any residual unit removes one bit of entropy from the regulator's Knowledge To Be Discovered. It specifies the standardized charge used by the operational ledger when only the capacity and the net closures are known, and the residual between them must be read as a discovery burden.
The idealized concrete-response selection that a residual unit would carry, were it realized as one narrowing step on a live candidate set, is:
The A5 charge equals this idealized selection when the step would perform an even split of the live concrete candidate-response set and one side is eliminated:
Under this condition:
The phrase even-split special case therefore identifies the regime in which the operational charge and the idealized concrete-response count-variety selection coincide:
Outside the even-split regime, the operational ledger does not alter the inferred residual to reproduce the idealized selection amount. A residual unit that would correspond to an uneven narrowing still counts as one unit. One that would correspond to a strong multi-way elimination still counts as one unit. One that would resolve nothing still counts as one unit. Thus:
This distinction preserves the black-box status of the operational ledger. The ledger fixes the closure-act capacity of the window and reads the net surviving closures; the residual between them is charged at one bit-equivalent per unit. It does not reconstruct an unobserved sequence of elementary binary questions after the fact. The discrepancy between the standardized A5 charge and the idealized amount of selection is treated separately by calibrating the A5 charge.
Calibration of the A5 Charge
Assumption A5 assigns one one-bit-equivalent operational charge to each inferred residual unit of . The idealized concrete-response selection that such a residual unit would carry, were it realized as one narrowing step on a live candidate set, is:
The candidate sets are the idealized (unobserved) reference introduced with A5; they are not ledger data. The calibration layer records the difference between the flat A5 charge and this idealized selection without changing the inferred residual . Define the unit-level A5 calibration residual as:
The sign of the residual has a direct accounting interpretation:
- when the idealized step is an even split and the A5 charge is exact;
- when the A5 charge exceeds the idealized concrete-response selection, so A5 overcharges the residual unit;
- when the idealized concrete-response selection exceeds one bit, so A5 undercharges the residual unit.
For a window , the residual is the inferred quantity defined above — it is not a tally over observed units. Its idealized concrete-response selection total, decomposed over the residual units attributed to the window, is:
The accumulated calibration residual is then the window-level gap between the flat A5 charge on the inferred residual and this idealized selection total:
This is the concrete-response-level calibration term. The further gap from idealized concrete-response selection to latent entropy reduction is the separate coding term introduced there; the two are not redundant.
Equivalently, the idealized selection total can be recovered from the inferred residual and its calibration residual:
The operational construction keeps fixed by the two observables and . It does not split one residual unit into several when the idealized narrowing would remove more than one bit, and it does not erase a residual unit whose idealized selection is zero. All deviation from the flat one-bit charge is carried by .
When is attributed the residual units of one nested fixed-knowledge-state episode, the idealized selection total telescopes:
For that episode:
The accumulated residual is therefore the difference between a linear residual-unit charge and the logarithmic reduction in idealized concrete-response variety. In the even-split regime the candidate-set measure falls by a factor of two at every stage, the logarithmic term equals , and the residual is zero. Outside that regime the two terms need not remain within a bounded distance of each other.
In particular, A5 alone does not imply the existence of a constant such that:
For example, a window whose residual units are all epistemically null has:
so the positive residual grows linearly with the number of residual units. Conversely, over a sequence of comparable episodes in which each residual unit idealizes to more than one bit of concrete-response variety, the residual may become increasingly negative. Thus the accumulated deviation may represent systematic overcharging or systematic undercharging rather than mean-zero observational noise. This is why the residual cannot be assumed bounded, and why bounds latent Knowledge To Be Discovered only when the calibration and coding gaps are jointly non-negative.
When learning changes the character of the residual units across comparable episodes, the sign of the residual may also change. For example, early units may idealize to broad multi-way eliminations and therefore be undercharged by A5, while later units may idealize to weak, confirmatory, or null narrowing and therefore be overcharged. This early-undercharge and late-overcharge pattern is not implied by A5 alone; it is a possible empirical learning trajectory that must be established from the reconstructed idealized selection amounts.
For , an optional normalized calibration factor is:
This factor is the mean idealized concrete-response selection per residual unit. Its relation to the accumulated residual is:
- means that A5 is exact on average over the window;
- means that A5 overcharges relative to the idealized concrete-response selection; and
- means that A5 undercharges relative to the idealized concrete-response selection.
This calibration does not convert the A5 residual into a latent entropy-reduction ledger. It compares the flat one-bit charge with the logarithmic reduction of the live concrete-response set. Concrete-response narrowing may differ from response-class support reduction, and both may differ from entropy reduction when probabilities are non-uniform or are redistributed among surviving classes. Any comparison with the latent reduction of Knowledge To Be Discovered therefore requires the additional response-projection and information-theoretic terms carried by introduced later.
A5 should consequently be interpreted as a form of operational residual-capacity accounting. It records how much closure-act-equivalent capacity was inferred to have gone unconverted into surviving closures, charged flat at one bit-equivalent per unit. The calibration residual records how far that flat charge departs from the idealized concrete-response selection the residual would represent. The distinction is deliberate: it preserves an estimator computed entirely from the two observables and , while making its departure from idealized selection explicit rather than silently identifying the two.
Invalidation monotonicity theorem
The increase in effective question depth due to observable invalidation load is defined as the difference between the net operational estimator and the no-observable-invalidation baseline of equation (4):
Substituting equations (4) and (5) gives:
Using , this becomes:
Equivalently:
Theorem 1 — Invalidation monotonicity. Fix and with . Regard the invalidation-induced increase in effective question depth as a function of the observable invalidation load on the domain . Then on this domain the quantity is (i) nonnegative, and equals zero if and only if ; and (ii) strictly increasing in .
Proof. Write and , so that . At the expression is zero, and it is positive for , which yields (i). Differentiating gives , which yields (ii).
Corollary 1 — Increasing marginal invalidation cost. For fixed and , the invalidation-induced increase in effective question depth is strictly convex in .. Thus each additional invalidated closure has a larger marginal effect than the previous one.
Proof. The second derivative on is positive. Hence the invalidation burden grows faster than linearly as observable invalidation load increases.
This corollary is the operational amplification result. Invalidation does not merely subtract completed work. It reduces the denominator of surviving closures, so the same fixed channel capacity is spread over fewer accepted closures. The effective burden per surviving closure therefore rises nonlinearly with the invalidation fraction.
Theorem 1 is purely operational relative to A1–A5; it is a statement about the closed-form behavior of the accounting estimator alone. The convexity claim sharpens the earlier monotonicity remark — not only does each invalidated closure raise the effective question depth, but successive invalidations raise it by strictly increasing increments, because the surviving denominator shrinks as grows.
The interpretation is narrow and operational. Observable invalidation load does not directly measure internal entropy. It increases the effective one-bit question depth because the same fixed channel capacity is now amortized over fewer surviving closures. Some closure-fixing acts consumed capacity but did not remain accepted at the end of the window. This is a selection-equivalent debit, not a direct count of completed corrective rework.
Invalidation fraction form
The same result can be expressed in terms of the observable invalidation fraction:
Since , equation (5) becomes:
Therefore:
This form exposes the amplification mechanism. As the invalidation fraction approaches one, the effective burden per surviving closure grows without bound. Operationally, this means that a process may consume large amounts of channel capacity while producing very few surviving closures.
Projection and count-variety decomposition of calibration error
Proposition 2 — Projection/count-variety decomposition of calibration error. Fix a window with . Let be the index set of net surviving closures in . For each , let be the realized disturbance-value for that closure, and let
be the concrete response-level staged trace for that closure.
For a surviving closure with realized disturbance-value , define the concrete and class count-varieties of its staged trace:
Define the projected class-level trace by
Assume the projected initial and terminal sets are finite and non-empty.
Under the A5 operational one-bit reading, the average concrete count-variety over the net surviving population is:
The operational anchor for the bridge is not this concrete count-variety but the net effective estimator of equation (5):
Define the average class-projected count-variety over surviving closures by
Let
The net effective anchor differs from the concrete count-variety only by an observable invalidation re-attribution. Partition the non-closure count by whether the episode's closure survived:
where is the non-closure count on episodes whose closures survived and is the non-closure count on episodes whose closures were invalidated.
Define the invalidation re-attribution load per surviving closure as the wasted-episode capacity, non-closure units plus the one closure unit per invalidated episode, amortized over the surviving closures:
Under the A5 even-split reading, each counted non-closure action unit as one even-split (one bit) on the concrete candidate set. So for a single surviving episode u, the number of non-closure units it spent equals its concrete count-variety, that's exactly the "one bit per even split" convention, summed over the episode's stages via the telescoping additive form. Summing that over all surviving episodes gives , on the left, the total non-closure count , and on the right, which is by definition:
This equation is converting a per-closure average back into a total count, so the two sides of the channel identity are in the same units. So the net effective estimator splits exactly as:
Then the net-anchored calibration error decomposes as:
where the net-anchored projection gap is the net effective estimator minus the average class-projected count-variety,
the fibre-redundancy gap is the concrete-to-class projection term,
and the count-variety gap is the class-count-variety-to-question-depth slack,
All three of , , and hence are computable from observables — the staged trace cardinalities, the survival-partitioned non-closure counts, and the invalidation load. The projection gap measures the difference between concrete response-level count-variety and response-class count-variety; the invalidation re-attribution measures the wasted-episode capacity amortized over surviving closures; the count-variety gap measures the difference between class-level count-variety and the ideal binary-question depth on the posterior over response-equivalence classes.
The two summands satisfy the following.
(i) Projection gap. For each surviving episode, with ,
If is injective on the surviving support (in particular whenever the episode terminates in a single concrete response, ), then
with equality iff is also injective on the initial support . Thus is the initial within-class log-redundancy carried by the concrete trace: the binary distinctions the action units spent separating concrete responses that share a class. Absent surviving-support injectivity, is not sign-definite. Under the A5 even-split reading and on a matched population,
Moreover, for each net surviving closure define the average fibre redundancy of a concrete candidate set under the projection by
Then the per-closure projection gap can be written as
Hence the projection gap is non-negative whenever the staged trace does not increase average fibre redundancy on the surviving projected support:
In particular, this condition holds when the concrete action-unit trace removes within-class redundant response-values without concentrating the terminal concrete support into fewer, more redundant response-equivalence classes. Equality holds exactly when the average fibre redundancy is unchanged by projection over the net surviving population. A sufficient special case is that is injective on the live concrete support of each net surviving trace.
(ii) Count-variety gap. is the slack between realized class count-variety and optimal binary-question depth, distinct from the source-coding gap of Lemma 1. Per surviving episode it is bracketed by the posterior redundancy :
In the finite equiprobable, fully-resolving regime — the posterior uniform on with and the trace is resolving to a singleton response-equivalence class — the “Count-Variety Selection” coincidence gives , then
and the calibration error reduces to the projection gap:
Proof. The identity is obtained by adding and subtracting the same projected count-variety term:
This gives by definition.
For (i), since is the image of a function, for every stage. Injectivity on gives ; substituting into cancels the terminal cardinalities and leaves , with equality iff , i.e. injective on . Singleton termination forces , hence the hypothesis.
The A5 even-split reading gives , so dividing the survival-partitioned identity by yields directly, with no assumption. Subtracting gives . The degenerate case forces , hence and , recovering the gross-anchored projection gap of the original statement;
The projection gap is not sign-definite in general, and surviving-injectivity controls the sign, not the equality. Counterexample: let have fibers take and Then but so the per‑episode gap is negative. What goes wrong with the intuition is that dropping the sole members of classes removes class-variety faster than concrete-variety. The honest statement is: surviving‑support injectivity is what forces and then whose equality case is injectivity on the initial support Singleton termination gives surviving injectivity for free, so the result holds exactly where we most want it.
The counterexample with fibers , , and gives , showing the sign hypothesis cannot be dropped.
For the sign statement, fix a net surviving closure . Using , the per-closure projection gap is
Thus the per-closure projection gap is non-negative whenever the terminal concrete support has no greater average fibre redundancy than the initial concrete support. Averaging over the net surviving population preserves the inequality.
For (ii), the bracket follows from (fully resolving) together with the per-row coding bracket of Lemma 1; uniformity on a power-of-two support makes and the Huffman bound tight, so all three quantities equal .
Finally, in the finite equiprobable fully resolving case, class count-variety equals entropy reduction, and a power-of-two equiprobable support can be resolved by an optimal binary-question tree with exactly questions. Hence the projected count-variety equals the ideal binary-question depth for each net surviving closure, so .
Ideality assumptions
The operational estimator becomes an estimator of the latent Knowledge To Be Discovered only under explicit bridging assumptions. We collect them here so that every conditional claim below can name exactly which assumptions it requires. The accounting identities of the preceding subsections, and Proposition 1, hold unconditionally and do not depend on (B1)–(B4).
(B1) Count-variety calibration bridge. The operational count of non-closure action units is a calibrated proxy for the ideal binary-question depth of the required response-equivalence class, not direct access to the regulator's internal posterior update. The action-unit trace narrows concrete response candidates, while the latent knowledge ledger concerns the response-equivalence class selected by those candidates.
The counted units are not assumed to be direct one-bit proxies for ideal binary discriminations about the required response-equivalence class . Instead, the operational-to-latent bridge is anchored directly on the net effective estimator of equation (5), , and factored through the class-projected count-variety of the surviving staged traces.
For a window with , define the net-anchored calibration error as the gap between equation (5) and the average ideal binary-question depth over the net surviving closures:
By Proposition 2, this error decomposes through the average class-projected count-variety over the net surviving population, , into a projection term and a count-variety term:
The projection term is not an assumption: it is computable from observables alone — the net effective load, the net surviving closure count, and the concrete and class-projected count-varieties of the surviving staged traces. Because it is anchored on the effective estimator , it carries two contributions: the within-class redundant narrowing of Proposition 2(i) (sign-controlled by surviving-support injectivity), and the invalidation re-attribution already booked into . Both are observed, so the invalidation effect enters the bridge as part of a derived, measurable quantity rather than as a separate assumed term.
Assumption B1 is therefore the single requirement that for a declared calibration tolerance , the residual count-variety term is controlled for the window under analysis:
Equivalently, the average class-projected count-variety approximates the average ideal binary-question depth over net surviving closures within . This is the count-variety-to-question-depth slack on a possibly non-uniform posterior over response-equivalence classes; it can take either sign and is distinct from the source-coding gap of Lemma 1. In the finite equiprobable, fully-resolving regime, Proposition 2(ii) gives , so B1 holds with and the calibration error collapses to the derived projection gap, .
This is not, by itself, a claim that every unobserved internal staged selection Ui contributes exactly one bit of conditional mutual information about X. The latter would be a stronger white-box idealization. Under that stronger idealization, if an episode has ku information-bearing stages, each contributing one bit, and terminates with zero residual uncertainty, then . The operational estimator does not assume direct access to those stages. It uses counted non-closure action units as an observable one-bit-equivalent proxy, and its interpretation as latent KTD depends on the explicit bridging assumptions and the derived error envelope.
(B2) No hidden selection at closure. Each closure unit records only the externally visible episode-closing commitment and folds no uncounted response-relevant discrimination into that commitment.
(B3) Unit-debit invalidation. Each invalidated gross closure is charged as one closure-unit of consumed capacity that failed to survive. For comparison with the one-bit action-unit channel, this lost closure unit is represented as a one-bit-equivalent operational debit. This is not a claim that invalidation directly adds one bit of latent entropy. Equivalently, the invalidation debit is exactly the observed invalidation load, so that .
(B4) Population matching. The counted closure population coincides with the knowledge-ledger row population for the window, so that aggregate channel quantities and the latent average are taken over the same closures. Note that the latent estimand uses a realized entropy that augments the original row, not one of its stored fields i.e. the expected .
Relation between the operational estimator and latent KTD
The operational estimator and the latent Knowledge To Be Discovered estimand should be read in two layers.
First, the unconditional operational layer: is the observed average effective one-bit action-unit depth per net surviving closure. This follows from the operational coding convention and the fixed-capacity accounting identity. It does not require direct access to the regulator's internal probability model.
Second, the conditional information-theoretic layer: the operational estimator becomes interpretable as an estimator of latent Knowledge To Be Discovered only through an explicit calibration bridge between counted non-closure units and ideal binary discriminations about the required response-equivalence class. The counting model alone does not derive that bridge.
Lemma 1 gives the remaining source-coding gap between ideal binary-question depth and latent realized Knowledge To Be Discovered. Define:
By the one-bit coding bracket:
The calibration error and the coding gap are different quantities. The first measures operational miscalibration. The second is the standard sub-one-bit gap between entropy and optimal binary-question depth.
Protocol non-informativeness condition. For the operational-to-latent bridge, the selected action-unit protocol must be fixed, or conditionally deterministic from already-counted information. Equivalently, conditioning on adds no information about X beyond Y, . If action-unit choice itself carries response-relevant information, then must be included in the information-bearing sequence and in the calibration bridge.
Theorem 2 — Operational-to-latent error envelope (net-anchored). Assume A1–A5 and B1, with
Let be the net-anchored calibration error of B1, and let be the source-coding gap of Lemma 1. Then the net effective estimator of equation (5) differs from the latent realized average starting Knowledge To Be Discovered by exactly the calibration error plus the coding gap:
Equivalently, the latent quantity is bracketed directly by the net effective estimator of equation (5):
Since the projection term is computable from observables, substituting together with the B1 bound gives the calibration-robust envelope on equation (5):
(6)
In the finite equiprobable, fully-resolving regime, Proposition 2(ii) gives , and the envelope is exact up to the coding gap:
Proof. By the B1 definition, , since the calibration error is defined as the gap between equation (5) and the average ideal binary-question depth. By Lemma 1, that average depth differs from the latent realized average starting Knowledge To Be Discovered by the source-coding gap, , with . Substituting the second relation into the first yields the stated identity. The bracket follows from .
For the robust form, Proposition 2 supplies with observable. The fibre-redundancy gap is nonnegative under surviving-support injectivity by Proposition 2(i), , and the invalidation re-attribution is nonnegative by construction, , so holds robustly as the sum of two nonnegative observable terms. Substituting the worst-case bounds gives the calibration-robust envelope, and the equiprobable case applies Proposition 2(ii). This proves the theorem.
Because the bridge is anchored on the effective estimator, the invalidation contribution is carried inside the observable projection term rather than as a separate term in the bracket. Theorem 1 is retained as the standalone decomposition of the invalidation effect; its identity recovers the baseline-anchored reading whenever the invalidation diagnostic is wanted.
The theorem separates three effects. The net effective estimator is exact and comes from the ledger. The calibration error comes from the mismatch between counted non-closure units and ideal binary discriminations. The coding gap comes from the standard sub-one-bit source-coding bracket.
The envelope is not an empirical guarantee produced by the operational ledger alone. It is a conditional envelope: the operational ledger supplies the exact debit term; B1-B2 plus Lemma 1 supply the entropy bracket.
Combining the ledger identity and the selection-equivalent debit, define equation (5) as the operational counterpart to the latent realized average starting Knowledge To Be Discovered for surviving closures: Equation (5) is operationally exact by accounting. Its interpretation as an estimator of the latent information-theoretic quantity is conditional on the calibration quality captured by . If the calibration bridge is weak, the equation remains a valid operational ratio, but its reading as an entropy estimator becomes a proxy claim rather than a derived identity.
Knowledge-Discovery Efficiency (KEDE) Metric
Now we generalize the Knowledge-Discovery Efficiency (KEDE) - scalar metric that quantifies how efficiently a system closes the gap between the variety demanded by its environment and the variety embodied in its prior knowledge[28].
KEDE is a scalar metric that quantifies how efficiently a system closes the gap between the variety demanded by its environment and the variety embodied in its prior knowledge[28]. KEDE is an acronym for KnowledgE Discovery Efficiency. It is pronounced [ki:d].
Efficiency means the smaller the average number of selections made per outcome the better. In other words - the less knowledge to be discovered per outcome the more efficient the knowledge discovery process is.
Theorem 2 gives the bridge between the operational counting ratio and the latent knowledge-to-be-discovered quantity. Therefore, KEDE must be defined in two layers: a latent entropy-based metric and an operational net metric computed from observed delivery counts. The operational metric is not assumed to be identical to the latent metric. It is an estimator whose relationship to latent knowledge-discovery efficiency is controlled by the error envelope in Theorem 2.
Operational Net KEDE
The operational metric is computed from the same net counting structure used in Theorem 2. From the effective one-bit net estimator,
the operational net KEDE is:
Since net surviving closures equal gross closures minus observed invalidations,
the operational net KEDE can also be written as:
This equation is operationally exact under the counting assumptions. It should not be read as saying that the latent entropy is directly equal to the observed ratio without calibration.
Latent KEDE
Let the latent net starting knowledge-to-be-discovered for an interval be the average realized conditional entropy over the net surviving closures:
The latent Knowledge-Discovery Efficiency is then defined as the reciprocal transform of this missing knowledge:
In the single-task notation, this corresponds to the familiar entropy form:
This is the conceptual definition: KEDE is high when little knowledge remains to be discovered, and low when much knowledge remains to be discovered.
Because both Knowledge-To-Be-Discovered quantities are non-negative, both efficiencies lie in . The next corollary pushes the Theorem 2 envelope through this bounded transform, so that KEDE inherits the same calibration-plus-coding error structure.
Corollary 2 — KEDE operational-to-latent error envelope. Assume the hypotheses of Theorem 2 (A1–A5 and B1, with , , and ). Let and , and let and , , be the calibration error and the source-coding gap of Theorem 2. Then the following hold.
(i) Bracket form. The ideal efficiency is bracketed by the operational estimator:
(C1)
(ii) Exact multiplicative identity. Using the exact Theorem 2 identity , the signed efficiency gap is exactly:
(C2)
and hence, since , the efficiency error is controlled by the operational efficiency itself:
(iii) Calibration-robust observable form. Writing with (Assumption B1) and computable from observables, the ideal efficiency obeys the fully observable bracket:
(C3)
The robust envelope gives the interpretation of that signal as an estimate of the underlying latent efficiency of the knowledge-discovery process.
(iv) Equiprobable fully-resolving regime. In the finite equiprobable, fully-resolving case, Proposition 2(ii) gives , so (C3) holds with and the envelope is exact up to the coding gap:
Proof. Let . On one has , so is continuous and strictly decreasing there. By definition, and .
For (i), Theorem 2 gives . Since is a posterior entropy, the upper endpoint satisfies , so every argument , , and lies in . Applying the strictly decreasing reverses the inequalities and yields , which is the displayed bracket once is substituted. The cap at follows from .
For (ii), the exact Theorem 2 identity gives . A direct computation gives the difference of reciprocals:
Recognizing and , and substituting , gives (C2). The bound on follows because when .
For (iii), substitute the calibration-robust Theorem 2 envelope (6), , into the same monotone argument; (iv) is the specialization via Proposition 2(ii).
Interpretation
The operational is computed exactly from the ledger. Corollary 2 shows it is the percentage-scaled face of the latent efficiency : the two differ by exactly times the product of the two efficiencies (C2), a gap that is mostly observable through and vanishes (up to the sub-one-bit coding gap) in the finite equiprobable, fully-resolving regime. KEDE therefore inherits the Theorem 2 error structure while remaining bounded in and usable as a ranking percentage across contexts.
KEDE remains bounded between zero and one. A value near one means that most of the knowledge required to close the interval was already available in the system: in requirements, design, code structure, tests, tools, conventions, or prior shared understanding. A value near zero means that the delivery system had to discover a large amount of missing knowledge during execution.
Due to its general definition KEDE can be used for comparisons between organizations in different contexts. For instance to compare hospitals with software development companies! That is possible as long as KEDE calculation is defined properly for each context. In what follows we will define KEDE calculation for the case of knowledge workers who produce textual content in general and computer source code in particular.
Knowledge Discovery Rate
The counting ledger and its efficiency transform are duration-free: they tally units, not time. The duration layer, quarantined into the unit convention, can now be reattached to give KEDE a rate reading. This reading is the operational form of Shannon's source-rate identity , and it makes explicit a notational collision that the paper otherwise leaves latent.
The missing intermediate quantity is the entropy rate. In Shannon's source-rate reading, H is not yet a rate per unit time. It is the average uncertainty, or irreducible information, per emitted symbol. If the source emits r symbols per unit time, then the resulting information rate is:
Thus, entropy rate answers the question: how many bits are carried, on average, by each symbol? Information rate answers the different question: how many bits are carried per unit time?
In Shannon's identity the two factors carry different units and only their product is a rate in time. is the entropy rate, the average uncertainty per symbol (bits per symbol), defined as the limit of the normalised joint entropywhile is the symbol rate (symbols per unit time) and is the information rate (bits per unit time).
Proposition 3; Discovery-rate factorization. Assume A1–A5 and B3, with . Then the effective discovery rate is the surviving-closure rate times the effective one-bit estimator of equation (5):
This equals and is the faithful analogue of Shannon's identity, since its “bits per symbol” factor is the per-closure Knowledge To Be Discovered.
Here denotes the elapsed duration of the observation window in the chosen time unit. It is not a symbol count. The counts , , and are ledger quantities accumulated inside the window; dividing by converts those accumulated quantities into rates. In a discretized convention: where is the number of time bins and is the duration of one bin.
Proof. In the ledger, there are two possible information rate factorizations, depending on which unit is treated as the source symbol. If the source symbol is the counted generic action unit, then the per-symbol discovery-load fraction is:
That is an effective discovery-load fraction per counted action unit, not an entropy-rate analogue.
If the source symbol is the net accepted closure, then the per-symbol discovery depth is:
The ledger admits two equivalent rate factorizations, but only after the symbol convention is fixed. If the symbol is the counted action unit, then the symbol rate is and the per-symbol discovery load is .
If the symbol is the accepted net closure, then the symbol rate is and the per-symbol discovery depth is .
Both use the same because both describe the same observation period. The difference is the chosen symbol unit. So is the bridge from ledger counts to rates. is the clock duration over which the ledger is read. It makes the difference between “how much missing knowledge was discovered” and “how fast missing knowledge was being discovered.”
For a fixed observation window , the effective discovery information rate is the window-level quantity . The action-symbol and closure-symbol readings are two algebraic factorizations of that same window-level quantity.
This also exposes the key point: the two factorizations are not two different clocks. They are two different ways of decomposing the same numerator over the same elapsed time .
Equation (5) gives , so .
The classical source-rate identity is recovered by the dictionary
Shannon-style information rate measures uncertainty per time, but Knowledge Discovery Rate cares about regulatory usefulness i.e. whether the discovered information helps select an acceptable response for successful regulation. Without this framework, Information Rate risks counting noise, activity, or communication volume. With this framework, it becomes knowledge-discovery throughput: the rate at which a regulator reduces missing knowledge into acceptable closures.
Naming the factors. The dictionary above preserves that split exactly: occupies the entropy-rate slot, in bit-equivalents per accepted closure; occupies the symbol-rate slot, in closures per unit time; and is the information rate, in bit-equivalents per unit time. In the strict stochastic-source case, the entropy rate governs compressibility. In the present finite-window ledger, the per-closure factor plays the same algebraic role, but remains an empirical one-window discovery-depth average unless the additional stationarity/ergodicity condition is imposed.
Two qualifications attach to the entropy-rate reading. First, the correspondence is one of units and of role in the factorization, not an identification of objects. The classical is an asymptotic, distributional quantity, and recovering it from a single trajectory requires stationarity and ergodicity of the kind isolated in Assumption E. By contrast is a finite-window count ratio on a single trajectory — action-units per closure under A5 — and is deliberately free of any stationarity, stable distribution, or mixing requirement; The conversion from count average to time-normalized rate is fixed by the unit convention for , not by stationarity or ergodicity. What That is because earlier the unit convention says the mean choice makes count and elapsed time agree in expectation, while robust choices like the median trade exactness for tail insensitivity. it measures is therefore the average discovery charge per accepted closure over ; it becomes an entropy rate in the strict sense only if one additionally imposes a condition in the spirit of Assumption E. Second, it is a one-bit-reading estimate under A5, so it carries and the coding gap per Corollary 2.
Effective vs. physical. By A2 (immediate fedback) and the effective progress partition, . The operational net efficiency is , so .
High KEDE means little remains to discover, so the discovery rate is low even when the action rate is high: the regulator is mostly closing, not searching. As , the discovery rate vanishes; as , the whole channel is spent on discrimination and .
Because , the KEDE-linked rate is inherently the effective one, which re-books invalidation load. The physical discrimination rate drops the invalidation debit, , and the two coincide exactly when .
Calibration inheritance. As a latent discovery rate, the discovery rate carries the Theorem 2 / Corollary 2 envelope: the true per-message bits differ from by the calibration error plus the sub-one-bit coding gap . In the finite equiprobable, fully-resolving regime (, Proposition 2(ii)), the factorization collapses to a clean symbol-rate × entropy-rate reading with only the coding gap remaining. The coincidence claimed here is with Shannon's identity, not with his limit object: what agrees is the algebraic factorization of a rate into symbol rate times per-symbol content, and the sole surviving discrepancy is . The per-closure factor remains a single-window empirical average throughout; it does not become an asymptotic entropy rate in this regime, and nothing in A1–A5 or B3 would make it one.
Applications
The knowledge-centric perspective builds on Ashby's Law of Requisite Variety by emphasizing that successful outcomes depend not only on a system's range of possible responses, but also on its ability to select the right response for each disturbance. This requires internal “system knowledge” that maps disturbances to appropriate actions. As Francis Heylighen proposed in his “Law of Requisite Knowledge,” effective regulation demands more than variety—it demands informed selection[29]. This knowledge-centric lens provides a foundation for analyzing how systems—biological, technical, or organizational—achieve control not just through options, but through understanding. The model we present operationalizes this perspective by estimating the informational requirements a system must satisfy to achieve its observed level of regulatory performance.
In what follows, we apply this knowledge-centric perspective to a range of domains, including motor tasks and manual assembly, industrial assembly lines, software development processes, speed of light in a medium, intelligence testing and sports performance. In each case, the model enables us to estimate, in bits of information, the amount of knowledge a system must lack to produce its observed level of performance. By quantifying the knowledge to be discovered H(X|Y), we assess how much uncertainty was there in the system's ability to select appropriate responses. This allows us to compare systems not by tangible outcomes, but by the hidden knowledge structures required to achieve them, offering a unified lens for analyzing adaptation, skill, and control across diverse contexts.
Anchoring KEDE to Natural Constraints
In our model, N is always the theoretical maximum action rate (selections + outcomes) in an unconstrained environment, and S is the observed outcome rate under specific conditions over a given interval.
A key question is how to assign a natural constraint to N. That is, what constitutes an appropriate reference value for the maximum action rate (selections + outcomes)?
We may turn to physics for an instructive analogy. A quantum (plural: quanta) represents the smallest discrete unit of a physical phenomenon. For instance, a quantum of light is a photon, and a quantum of electricity is an electron. In this context, the speed of light in a vacuum serves as a fundamental upper bound for N. However, identifying an analogous natural constraint for human activity—particularly knowledge work—presents greater challenges.
Consider the example of typing. Here, the quantum can reasonably be defined as a symbol, since it is the smallest discrete unit of text. A symbol may be a letter, number, punctuation mark, or whitespace character. To determine the appropriate bin width Δt, we refer to empirical data on the minimum time required to produce a single symbol. Typing speed has been subject to considerable research. One of the metrics used for analyzing typing speed is inter-key interval (IKI), which is the difference in timestamps between two keypress events. We see that IKI is defined equal to the symbol duration time t. Hence we can use the research of IKI to find the symbol duration time t. Studies have reported an average IKI of 0.238 seconds [26], yielding a maximum human typing rate of approximately r=1/t=1/0,238=4.2 symbols per second
A similar approach can be applied to tasks such as furniture assembly. In this case, a plausible quantum is a single screw tightened, since it represents a minimal, repeatable unit of outcome. We then identify Δt as the average time required to tighten one screw. Empirical studies report that this task typically takes between 5 and 10 seconds[34]. Using the upper bound, we estimate the maximum screw-tightening rate as N=1/t=1/10=0.1 screws per second.
This methodology offers a principled way to estimate N using domain-specific quanta and empirically grounded time durations, enabling the application of our model to a broad range of human tasks.
The next question concerns the appropriate definition of outcome for measuring S and N.
Both N and S can always be discretized—or “binned”—in a way that preserves the total information rate, regardless of whether the outcome arises from natural processes, human behavior, or machines. By choosing a bin width Δt small enough (e.g., milliseconds), the range of possible tangible outcomes within each bin shrinks dramatically. This reduced range leads to less uncertainty in each bin, which compensates for the smaller time interval. Yet the ratio
remains an accurate measure of information rate.
As Δt becomes smaller, the measurements of S and N become more precise, as they reflect outcome over finer time intervals. But how small should Δt be? This dilemma is resolved by considering the granularity of outcomes associated with the outcome. The set E of outcomes can be thought of as the effects of the regulation process — the resulting states after the regulator responds to disturbances. In our model E is a sequence of {0,1}, where 0 = wrong outcome(failure to regulate) and 1 = acceptable outcome. So the presence of a concrete outcome leads to a natural binning of the outcomes, It also enables a clear distinction between signal (the entropy associated with producing the outcome) and noise (the residual variability unrelated to success or failure).
For example, two distinct symbols typed (e.g., ‘a' vs. ‘b') are clearly different outcomes. However, if one symbol is typed in 91 milliseconds and another in 92 milliseconds, this minute variation is inconsequential to the outcome. Such timing fluctuations are typically unintentional, irrelevant to task performance, and should not be considered part of the outcome. In practical terms, if the theoretical upper bound N is known—for instance, 4.2 symbols per second as derived from human typing speed, and the observed rate is S=1 symbol per second, then time should be partitioned into one-second bins. Each bin then yields a single outcome: either 1 (a symbol was successfully typed) or 0 (no symbol typed or incorrect input).
This binning principle generalizes beyond typing. Whether analyzing foot strikes in trail running (where negligible spatial change occurs over milliseconds) or the discrete moves in solving a Rubik's cube (where each turn resolves multiple potential states into a single action), binning ensures that no intermediate state need be modeled explicitly.
Physical applicability claim. For any isolated physical system to which a finite entropy bound applies, the number of physically distinguishable states is finite. Therefore the system admits a binary encoding whose length is bounded by the corresponding entropy bound expressed in bits. In holographic settings, this gives an upper bound of binary discriminations. Here they use the Planck length meters) and its associated surface area, the Planck area . Hence the Knowledge To Be Discovered Estimator applies to such physical systems after representing admissible states by a bounded sequence of binary discriminations.
Calculating Knowledge To Be Discovered from a Reported Learning Curve
Reported learning curves usually give time, cost, or speed as a function of accumulated practice. They do not directly report the internal selection trace of the actor. Nevertheless, if the repeated output can be interpreted as a sequence of closure acts, the learning curve can be re-expressed in Knowledge Discovery terms by defining the interval capacity from the best observed closure rate.
The demonstration below uses Ohlsson's data on Isaac Asimov's book-writing career[59]. The paper says Asimov wrote nearly 500 books over more than 40 years, treats one book as one practice trial, and groups the data into blocks of 100 books because individual books vary greatly in length and complexity. In that study, the completion of one book is treated as one completed knowledge-discovery episode. Therefore, for this reconstruction, one completed book is treated as one surviving closure.
Let denote block . Let be the number of surviving closures in the block, and let be the counted closure capacity of the same elapsed interval.
Under the time-normalized unit convention, counted capacity is defined by the elapsed duration of the interval divided by the selected unit length:
Learning-curve literature already treats the asymptote as the best possible performance limit[60]. At asymptotic performance, the actor still performs work, but no longer pays the earlier knowledge-discovery penalty. In many published learning curves, the asymptote is not directly known. Ohlsson’s Asimov paper is exactly like this. Ohlsson states that, after mastery, the tail of the curve approximates a horizontal line, and the asymptote represents the best possible performance. For this reconstruction, the unit length is not taken from an external physical limit. It is calibrated from the best observed block in the reported learning curve. In Asimov's data, the best observed closure rate occurs in the fourth block: 100 books in 46 months. Therefore:
Equivalently, the empirical closure capacity rate is:
The capacity of each block is then calculated as the number of book-closures that could have been produced in that block's elapsed time if the process had operated at the best observed closure rate:
From the effective one-bit net estimator in equation (5), the inferred Knowledge To Be Discovered for each block is then:
And the corresponding operational Knowledge Discovery Efficiency is:
Calculation
| Block | Elapsed time | Surviving closures S(I) | Capacity N(I) | ||
|---|---|---|---|---|---|
| 1 | 237 months | 100 books | 515.22 book-closures | 4.152 | 0.194 |
| 2 | 113 months | 100 books | 245.65 book-closures | 1.457 | 0.407 |
| 3 | 69 months | 100 books | 150.00 book-closures | 0.500 | 0.667 |
| 4 | 46 months | 100 books | 100.00 book-closures | 0.000 | 1.000 |
| 5 | 42 months | 90 books | 91.30 book-closures | 0.014 | 0.986 |
Interpretation
This conversion reads the published learning curve as an empirical-capacity curve. The best observed block defines the empirical closure-unit length: months per book-closure. Earlier blocks are then interpreted relative to that later demonstrated capacity.
In the first block, the elapsed interval had an empirical capacity of approximately 515 book-closures, but only 100 surviving closures were produced. The inferred is therefore 4.152. In operational terms, this means that for each surviving book-closure, the process consumed enough elapsed capacity for approximately 4.152 additional non-surviving or pre-closure units of discovery burden. By the third block, the same method gives The process still contains substantial discovery burden, but much less than in the early career phase. By the fourth block, the observed process reaches the empirical capacity anchor, so by calibration.
Notice that KTD does not necessarily fall to zero in the final block. The final block produced 90 books in 42 months. At the best observed rate, that interval had capacity for approximately 91.30 book-closures. Therefore the final block has a small positive and . This is conceptually preferable to forcing the last observation to be the zero-KTD point merely because it appears last in the sequence.
Methodological caveat
This is not a direct measurement of Asimov's internal knowledge discovery process. It is a reconstruction from reported learning-curve data. The calculation assumes that completed books are comparable enough to serve as closure units and that the best observed block is a reasonable empirical estimate of book-writing action capacity. Differences in book length, genre, research burden, publishing process, and external constraints may also affect the observed rate. Therefore, the result should be read as learning-curve-calibrated, not as a direct ledger measurement of Knowledge To Be Discovered (KTD).
The demonstration nevertheless shows how published learning curves can be translated into Knowledge Discovery terms. A learning curve becomes a visible trace of declining discovery burden: as knowledge accumulates, the number of capacity units consumed per surviving closure falls, and operational KEDE rises.
Tightening screws
We can apply our model to motor tasks such as furniture assembly. In this context, a natural unit of outcome — or “quantum” — is the tightening of a single screw.
Skilled workers engaged in manual assembly tasks can typically insert and tighten standard screws at a rate of 6'-12 screws per minute under optimal, repetitive conditions — such as those found in furniture construction or industrial assembly lines. In contrast, automated screw-tightening machines can achieve significantly higher rates, often between 30 and 60 screws per minute [34] More complex manual tasks, such as high-torque applications involving ratchets or Allen keys, typically reduce the rate to 2'-4 screws per minute due to the increased effort and precision required. In surgical or medical contexts, such as orthopedic screw insertion, accuracy and the avoidance of overtightening are paramount; here, rates often fall to 1'-2 screws per minute, or approximately one screw every 30'-60 seconds [46].
| Context | Typical Rate (screws/minute) | Notes |
|---|---|---|
| Automated (machine) | 30'-60 | For comparison, not manual |
| Fast, repetitive tasks | 6'-12 | Assembly line, minimal torque required |
| High-torque/manual | 2'-4 | Metalwork, ratchets, Allen keys |
| Surgical/precision | 1'-2 | Orthopedic, high accuracy, low speed |
The key observation is that rates decrease as torque, task complexity, or required precision increases. If we take the machine rate as the maximum possible outcome N and the observed human rate as S, we can estimate the average number of bits of information H(X|Y) that the human operator must process per action.
This implies that the human must absorb approximately 4 bits of information, on average, to tighten a single screw under typical conditions.
The rate at which a person tightens screws depends on various factors, including:
- Screw type and size
- Material being fastened
- Required torque
- Tool used (screwdriver, ratchet, etc.)
- Operator skill and fatigue
This interpretation aligns with existing research, which suggests that task difficulty directly influences the amount of information a task imparts [47, 48]. When difficulty is appropriately matched to the individual's skill level, the task yields maximal informational value [49], and the time required reflects the interaction between task complexity and the individual's regulatory capacity [50].
Using our model, we transform a sequence of real-world actions in furniture assembly into a granular, time-based measure of regulatory capacity. This enables us to quantify — in bits — how much variety the individual must absorb in order to successfully complete the task.
Typing the longest English word
Let's use an example scenario to see Ashby's law applied to human cognition and knowledge work.
For that we'll have myself executing the task of typing on a keyboard the word “Honorificabilitudinitatibus”. It means “the state of being able to achieve honours” and is mentioned by Costard in Act V, Scene I of William Shakespeare's “Love's Labour's Lost”. With its 27 letters “Honorificabilitudinitatibus” is the longest word in the English language featuring only alternating consonants and vowels.
The way I will execute this task is to go to the "play text" or "script" of “Love's Labour's Lost”, look up the word and type it down. The manual part of the task is to type 27 letters. The knowledge part of the task is to know which are those 27 letters.
In order to track the knowledge discovery process I will put "1" for each time interval when I have a letter typed and "0" for each time interval when I don't know what letter to type.
I start by taking a good look at the word “Honorificabilitudinitatibus” in the script of “Love's Labours' Lost”. That takes me two time intervals. Then I type the first letters “H”, “o”, and “n”.I continue typing letter after letter: “o”, “r”. At this point I cannot recall the next letter. What should I do? I am missing information so I go and open up the script of “Love's Labours Lost” and I look up the word again. Now I know what the next letter to type is but acquiring that information took me one time interval. This time I have remembered more letters so I am able to type “i”,”f”,”i”,”c”,”a”,”b”,”i”. Then again I cannot continue because I have forgotten what were the next letters of the word, so I have to look it up again.in the script. That takes two more time intervals. Now I can continue my typing of “l”,”i”,”t”. At this point I stop again because I am not sure what were the next letters to type, so I have to think about it. That takes one time interval. I continue my typing with “u”,”d”,”i”. Then I stop again because I have again forgotten what were the next letters to type, so I have to look it up again in the script of “Love's Labours Lost”. That takes two more time intervals. Now I know what the next letter to type is so I can continue typing “n”,”i”.At this point I cannot recall the next letter. so I have to look it up again in the script. That takes two more time intervals. After I know what the next letter to type is I can continue typing “t”,”a”,”t”,”i”,”b”,”u”,”s”. Eventually I am done!
At the end of the exercise I have the word “Honorificabilitudinitatibus” typed and along with it a sequence of zeros and ones.
|
|
|
H | o | n | o | r |
|
i | f | i | c | a | b | i |
|
|
l | i | t |
|
u | d | i |
|
|
n | i |
|
|
t | a | t | i | b | u | s |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
In the table we have separated the manual work of typing from the knowledge work of thinking about what to type.
The first row of the table shows the knowledge I manually transformed into tangible outcome - in this case the longest English word. The second row of the table shows the way I discovered that knowledge. There is a "0" for each time interval when I was missing information about what to type next. There is "1" for each time interval when I had prior knowledge about what to type next. Each "0" represents a selection I needed to ask in order to acquire the missing information about what letter to type next. Each "1" represents prior knowledge.
In the exercise above we witnessed the discovery and transformation of invisible knowledge into visible tangible outcome.
KEDE calculation
We can calculate the KEDE for this sequence of outcomes.
We can also calculate the knowledge discovered H(X|Y) in bits of information.
We've turned a real-world sequence of action and hesitation into a fine-grained, time-based measurement of regulatory capacity — effectively measuring how much variety I needed to absorb with external help i.e. my knowledge discovered.
Measuring software development
In order to use the KEDE formula (8) in practice we need to know both S and N. We can count the actual number of symbols of source code contributed straight from the source code files. For N we want to use some naturally constrained value.
N is the maximum number of symbols that could be contributed for a time interval by a single human being.
In the below formula for N we want to use some naturally constrained value: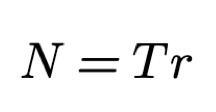
To achieve this, the following estimation is performed. We pick T = 8 hours of work because that is the standard length of a work day for a software developer.
To calculate the value of r we need to pick the symbol duration t.
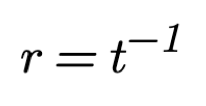
The value of the symbol duration time t is determined by two natural constraints:
- the maximum typing speed of human beings
- the capacity of the cognitive control of the human brain
Typing speed has been subject to considerable research. One of the metrics used for analyzing typing speed is inter-key interval (IKI), which is the difference in timestamps between two keypress events. We see that IKI is defined equal to the symbol duration time t. Hence we can use the research of IKI to find the symbol duration time t. It was found that the average IKI is 0.238s [26]. There are many factors that affect IKI [6]. It was also found that proficient typing is dependent on the ability to view characters in advance of the one currently being typed. The median IKI was 0.101s for typing with unlimited preview and for typing with 8 characters visible to the right of the to-be-typed character but was 0.446s with only 1 character visible prior to each keystroke [7]. Another well-documented finding is that familiar, meaningful material is typed faster than unfamiliar, nonsense material[8]. Another finding that may account for some of the IKI variability is what may be called the “word initiation effect”. If words are stored in memory as integral units, one may expect the latency of the first keystroke in the word to reflect the time required to retrieve the word from memory[55].
Cognitive control, also known as executive function, is a higher-level cognitive process that involves the ability to control and manage other cognitive processes that permit selection and prioritization of information processing in different cognitive domains to reach the capacity-limited conscious mind. Cognitive control coordinates thoughts and actions under uncertainty. It's like the "conductor" of the cognitive processes, orchestrating and managing how they work together. Information theory has been applied to cognitive control by studying the capacity of cognitive control in terms of the amount of information that can be processed or manipulated at any given time. Researchers found that the capacity of cognitive control is approximately 3 to 4 bits per second[32][33], That means cognitive control as a higher-level function has a remarkably low capacity.
Based on the above research we get:
- Maximum typing speed of human beings to be r=1/t=1/0,238=4.2 symbols per second
- Capacity of the cognitive control of the human brain to be approximately 3 to 4 bits per second. Since we assume one question equals one bit of information we get 3 to 4 questions per second.
- Asking questions is an effortful task and humans cannot type at the same time. If there was a symbol NOT typed then there was a question asked. That means the question rate equals the symbol rate, as explained here.
In order to get a round value of maximum symbol rate N of 100 000 symbols per 8 hours of work we pick symbol duration time t to be 0.288 seconds. That is a bit larger than what the IKI research found but makes sense when we think of 8 hours of typing. Having t of 0.288 seconds makes a symbol rate r of 3.47 symbols per second. That is between 3 and 4 and matches the capacity of the cognitive control of the human brain.
We define CPH as the maximum rate of characters that could be contributed per hour. Since r is 3.47 symbols per second we get CPH of 12 500 symbols per hour. We substitute T = h and r=CPH and the formula for N becomes:
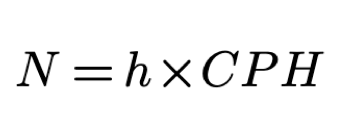
where h is the number of working hours in a day and CPH is the maximum number of characters that could be contributed per hour. We define h to be eight hours and get N to be 100 000 symbols per eight hours of work.
Total working time consist of four components:
- Time spent typing (coding)
- Time spent figuring out WHAT to develop
- Time spent figuring out HOW to code the WHAT
- Time doing something else (NW)
Let us assume an ideal system where the time spent doing something else TNW is zero. Using the new formula for N the formula for H becomes
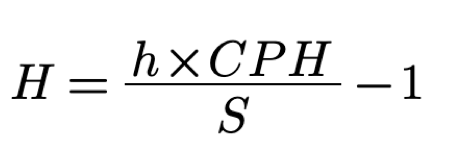
Note, that since N is calculated per hour so S also needs to be counted in an hour.
We see that the more symbols of source code contributed during a time interval the less missing information was there to be acquired. We want to compare the performance of different software development processes in terms of the efficiency of their knowledge discovery processes. Hence we rearrange the formula to emphasize that.
(8)
The right hand part is the KEDE we defined earlier. Thus, we define an instance of the metric KEDE - the general metric that we introduced earlier. This version of KEDE is for the case of knowledge workers that produce tangible outcome in the form of textual content:
(9)
KEDE from (9) contains only quantities we can measure in practice. KEDE also satisfies all properties we defined earlier. it has a maximum value of 1 and minimum value of 0; it equals 0 when H is infinite; it equals 1 when H is zero; it is anchored on a natural constraint—the maximum typing speed of a human being.
If we convert the KEDE formula into percentages then it becomes:
(10)
We can use KEDE to compare the knowledge discovery efficiency of software development organizations.
Testing Intelligence
Today all measure intelligence by the power of appropriate selection (of the right answers from the wrong). The tests thus use the same operation as is used in the theorem on requisite variety, and must therefore be subject to the same limitation. (D, of course, is here the set of possible questions, and R is the set of all possible answers). Thus what we understand as a man's “intelligence” is subject to the fundamental limitation: it cannot exceed his capacity as a transducer. (To be exact, “capacity” must here be defined on a per-second or a per-question basis, according to the type of test.)[3]
We can also use our model to the testing of human and AI intelligence. We infer this capacity from performance under variety — i.e., how many different problems a system or a person can solve correctly.
The dominant mathematical models for testing intelligence by the number of answered problems are benchmark datasets like MMLU, GSM8K, MATH, and FrontierMath. These models measure intelligence by the raw count or percentage of correctly solved problems, with more advanced benchmarks designed to minimize guessing and require deep reasoning.
From the knowledge-centric perspective:
- The disturbances are the questions
- The person gives responses
- The outcomes are
Several mathematical models and benchmark datasets are used to evaluate intelligence—especially artificial intelligence (AI)—by measuring the number and complexity of math problems answered correctly. These models serve as standardized tests for both AI and, by analogy, human intelligence[52].
Massive Multitask Language Understanding (MMLU):
- MMLU is a widely used benchmark that tests AI models on a broad range of subjects, including mathematics at various levels (high school, college, abstract algebra, formal logic).
- The test is typically formatted as multiple-choice questions, and performance is measured by the percentage of correct answers out of the total number of questions
- For example, advanced AI models have achieved up to 98% accuracy on math sections of MMLU, indicating high proficiency in standard math tasks but not necessarily deep reasoning
Grade School Math 8K (GSM8K)
- GSM8K is a dataset of 8,500 high-quality, grade school-level word problems designed to test logical reasoning and basic arithmetic skills.
- Evaluation is based on exact match accuracy: the number of problems answered exactly correctly divided by the total number attempted
- This benchmark is used to assess step-by-step reasoning and the ability to handle linguistic diversity in problem statements.
MATH (Mathematics Competitions Dataset)
- MATH consists of problems from high-level math competitions (e.g., AMC 10, AMC 12, AIME), focusing on advanced reasoning rather than rote computation.
- Performance is measured by the percentage of correct answers, with human experts (e.g., IMO medalists) providing a reference for top-level performance
- The dataset is challenging for both humans and AI, with LLMs typically scoring much lower than expert humans.
FrontierMath[53]
- FrontierMath is a new benchmark featuring hundreds of original, expert-level math problems spanning major branches of modern mathematics.
- Problems are designed to be "guessproof" and require genuine mathematical understanding, with automatic verification of answers
- The benchmark is used to assess how well AI models can understand and solve complex mathematical problems, similar to human performance.
In human intelligence testing, Psychometric models such as IQ tests or psychometric approaches also use the number of correctly answered problems as a key metric. These tests are standardized, and the raw score (number of correct answers) is often converted into a scaled score or percentile.
As an example we will use the Exact Match metric as the evaluation method[52]. Given that each question in our benchmark dataset has a single correct answer and the model produces a response per query, Exact Match ensures a rigorous evaluation by comparing the extracted answer to the ground truth.
Let represent the extracted answer from the model's outcome for the question, and let be the corresponding ground truth answer. The Exact Match accuracy is computed as:
where:
- is the total number of evaluated questions.
- is the indicator function, returning 1 if the extracted model response matches the ground truth after preprocessing, and 0 otherwise.
- is a function that standardizes formatting, trims spaces, and normalizes numerical values.
The knowledge discovery efficiency of an LLM can be calculated as:
Let's pick the case of the performance of GPT-4o on the MATH benchmark, which achieved a significantly lower accuracy of 64.88%, lagging behind its peer models[52]. Now, we can calculate the average knowledge discovered H(X|Y).
Basketball Game
We can also use this model to assess the performance of a basketball player.
- Timeframe is a basketball game.
- We observe N total shot attempts.
- S of them are successful (shot made).
-
We record a binary outcome sequence
-
The empirical success rate:
is our observed probability of success.
Interpretation using Ashby's Law
The basketball shot is a regulation problem: the player must control their body and respond to the game environment to produce the desired outcome. The player is faced with a series of disturbances (D) in the form of different shots to make under different conditions. The player responds with a selection, drawn from their internal skills (regulatory variety R) in the form of different shooting techniques. Each shot is uncertain whether it will be successful. The outcome E is whether the shot is made (2) or missed (0).
Over N shots, the success rate
In this case, θ becomes a practical proxy for how often the regulator (player) has sufficient internal variety to absorb the disturbance presented by the game. However, it is important to note that this is a simplified model and does not account for all the complexities of basketball performance. For example, the player may have different success rates depending on the type of shot, the position on the court, or the level of defense. These factors can all affect the player's ability to regulate their performance and should be considered when interpreting the results. Thus, as explained here θ is a useful heuristics for P(E=1), but the full picture includes the quality of mapping, not just quantity.
Applying the Model
NBA keeps track of field goal attempts and makes for each player. The most field goal attempts by a player in a single NBA game is 63, achieved by Wilt Chamberlain during his legendary 100-point game against the New York Knicks on March 2, 1962 We take this as the natural constraint so N=63. We can also take the number of successful shots S=36, which is the most field goals made in a single game by a player[13].
We can calculate the KEDE for this sequence of outcomes.
We can also calculate the knowledge discovered H(X|Y) in bits of information.
That means that the player needed to absorb 0.75 bits of information on average to make the shot.
We've turned a real-world sequence of basketball shots into a fine-grained, time-based measurement of a regulatory capacity — effectively measuring how much variety the player needed to absorb.
We can also use this model to assess the performance of a basketball team. In this case the success rate coincides with the field goal percentage (FG%) of the team which is the percentage proportion of made shots over total shots that a player or a team takes in games. There is a statistical distribution for NBA field goal percentage (FG%) [10]. Analysts and researchers often study the distribution of FG% across players or teams to understand scoring efficiency and trends[11]. The NBA record for the highest FG% in a single game by a team is 69.3%, set by the Los Angeles Clippers on March 13, 1998, when they made 61 of 88 shots[12].
For example, in the 2023-24 season, team FG% ranged from about 43.5% (lowest) to 50.6% (highest), with the league average typically falling in the mid-to-high 40% range[11]. if we take the average FG% of 45% , we can calculate the average knowledge discovered H(X|Y).
That means that a team needed to absorb 1.22 bits of information on average to make a shot.
Assembly Line
We can also use this model to assess the knowledge discovery efficiency of an assembly line.
The assembly line is a system that transforms raw materials into finished products. The assembly line has a set of disturbances (D) in the form of different raw materials, machines, and processes. The assembly line responds with a selection, drawn from its internal structure (R) in the form of different machines, processes, and workers.
From a knowledge-sentric perspective most of the knpwledge discovery happens in the design phase of the assembly line. This is the planning for design, fabrication and assembly. This activity has also been called design for manufacturing and assembly (DFM/A) or sometimes predictive engineering. It is essentially the selection of design features and options that promote cost-competitive manufacturing, assembly, and test practices[51]. Thus most of the disturbances D are already absorbed by the design of the assembly line. That means when the workers have most of the knowledge built into the assembly line and the operational procedures.
Assembly line efficiency (AE) is the ratio of the outcome to the maximum possible outcome, often expressed as a percentage.
The efficiency of the assembly line can be calculated as:
We can assume that an assembly line is designed to produce a certain number of successful products (S) with a maximum rate of N products per hour. So for example, a shoe manufacturer has an actual outcome of 100 shoes per day, and a maximum potential outcome of 120 shoes per day. Their production line efficiency would be 83%. Now, we can calculate the average knowledge discovered H(X|Y).
To optimize the AE, companies can apply DFA guidelines, such as minimizing the number and variety of parts, standardizing the fasteners and connectors, and simplifying the assembly sequence and orientation[51].
Interpreting the results involves a comprehensive analysis of the data to understand where and why inefficiencies occur. In general, the higher the AE, the better the design. On the other hand, AE close to 100% might indicate under-utilised capacity. It's essential to compare high efficiency with industry capacity standards to determine if an increase in production is feasible and beneficial.
If AE is consistently below industry benchmarks, this could highlight several potential issues:
- Machinery: It may indicate that machines are outdated, malfunctioning, or not suitable for the required tasks.
- Labour Skills: Low efficiency might be due to workforce training gaps.
- Process Design: Sometimes, the workflow or layout of the production line itself causes inefficiencies.
Speed of Light in Medium
We can also use this model to support an interpretation of Ashby's Law of Requisite Variety to assess the speed of light in a medium where the medium acts as a disturbance to photon flow. Here's how this perspective aligns with the physics of light-matter interactions:
- Disturbance: The medium's atomic/molecular structure introduces spatial and electromagnetic inhomogeneities (e.g., refractive index variations, turbulence).
- Control Mechanism: Photons' ability to "counteract" disturbances through wavelength compression and phase synchronization.
- Requisite Variety: Photons require sufficient adaptability (e.g., frequency range, polarization states) to navigate the medium's complexity without scattering or losing coherence.
The speed of light in a vacuum is 299,792,458 m/s. In a medium, the speed of light is reduced by a factor n, called the refractive index defined as:
The refractive index is a measure of how much the speed of light is reduced in the medium. The higher the refractive index, the more the speed of light is reduced.
For example, the refractive index of water is 1.33, which means that the speed of light in water is:
The knowledge discovery efficiency of the speed of light in a medium can be calculated as:
Now, we can calculate the average knowledge discovered H(X|Y) by a photon in water:
Appendix
Example: A Two-Dimensional Parabola
Consider the parabola as an example of the distinction between a variable, the set of its possible values, the set of realized values, and the graph of a mapping.
Let D be the disturbance variable, and let its set of possible values be
Let Z be the outcome variable, with possible outcome-values
and define the realized outcome map by
The parabola is then the graph
Thus:
- the x-axis contains disturbance-values
- the y-axis contains outcome-values
- the parabola itself is the graph of the map
Distinct disturbance-values may yield the same outcome-value:
The repetition belongs to the mapping, not to the set 𝒴. The set of possible outcome-values still contains the value 4 only once.
Where are and its acceptable subset η?
The essential-value space appears only once one specifies how outcomes are evaluated. There are two natural cases:
Case 1: The y-axis already represents the essential values
If the outcome-values themselves are the essential values, then
and the evaluation map is simply the identity:
In that case, E is represented directly by the y-axis and the acceptable subset is literally a subset of the y-axis. For example,
Geometrically, η is the allowed vertical segment on the y-axis.
Then the question of successful regulation becomes:
If then so success fails if , because outcomes larger than 4 occur. But if disturbances are restricted to then so success holds since .
Case 2: is an evaluative space distinct from the y-axis
If the y-axis shows fine-grained outcomes, while regulation cares only whether those outcomes are acceptable, then define
with evaluation map
Then the y-axis is still but E is now a coarser evaluative variable and the acceptable subset is
In this second case, E is not directly identical with the y-axis unless we add the extra evaluation layer. Rather, the y-axis is first mapped into an evaluative space by φ.
In one sentence, in the parabola example, the curve shows the mapping from disturbance-values to outcome-values; E appears only after we decide how those outcome-values are to be evaluated for survival or acceptability; and is the acceptable part of that evaluative space.
The Parabola as Possibility, and Realization as a Subset of Possibility
This full graph G the possible disturbance-outcome relation generated by the mapping.. Actuality appears only after a realized disturbance subset is specified.
Then the set of realized outcome-values is
and the realized part of the graph is
Thus, the x-axis contains possible disturbance-values, the y-axis contains possible outcome-values, the full parabola represents the possible disturbance–outcome relation, and only a subset of its points need be realized in fact.
For example, if the realized disturbances are
then the realized outcome-values are
not because these are all possible outcome-values, but because these are the values generated by the disturbances that actually occurred.
Example of a Human Knowledge Discovery Process with Goal-Model Revision
We now apply the same set-based structure to a simple human knowledge-discovery task: typing the word “Honorificabilitudinitatibus”.
The authoritative target word is:
It has 27 letters. Let be the set of target-word positions, and let be the set of possible typed symbols. Let denote the authoritative correct symbol at position in the target word.
Outcome-value space
The outcome-value space records what symbol was typed for what intended target position. Thus we define:
An outcome-value has the form:
where is the intended position in the target word, and is the typed symbol. For example, means that the symbol H was typed for position 1.
This is different from the closure-event index. The closure-event index records when the typing act occurred. The target-position index records which position the act attempted to satisfy. Therefore, in general.
Essential-variable space
In this example, both the outcome-value space and the essential-variable space are two-dimensional. The two dimensions are target-word position and symbol. Thus the outcome-value space has coordinates , and the essential-variable space uses the same two goal-relevant dimensions: which symbol occupies which target-word position for purposes of judging success.
There are two equivalent ways to read this example.
Reduced correspondence. In the reduced case, the concrete outcome-value is already the essential-variable value:
So, in the reduced case:
Bijective correspondence. In the bijective case, the outcome-value space and the essential-variable space are conceptually distinct, but every relevant outcome-value corresponds to exactly one essential-variable value, and every relevant essential-variable value corresponds to exactly one outcome-value.
For the bijective reading, the outcome-value space and essential-variable space are conceptually distinct but have the same two-dimensional coordinate structure:
where is the essential-variable coordinate for target position, and is the essential-variable coordinate for the symbol occupying that position. Thus an essential-variable value may be written as , where means: “the goal-relevant state in which symbol occupies target position .”
The outcome-to-essential-variable map is:
This map is bijective on the relevant modeled spaces. The concrete outcome and the essential-variable value are not the same object, but they carry the same distinctions for this regulatory model.
Authoritative acceptable essential-variable region
The authoritative acceptable essential-variable region is the set of goal-relevant states corresponding to the correct position-symbol pairs in the target word:
For example:
but:
The authoritative acceptable region does not change during the exercise. The target word remains the same. The Shakespeare text did not change. The required symbol at position did not change.
Authoritative acceptable outcome-set
The authoritative acceptable outcome-set is the pullback of the authoritative acceptable essential-variable region along :
In the bijective case, this gives:
In the reduced case, since , the same condition reduces to:
Thus the example can be read either way. In the reduced reading, outcome-values already are essential-variable values. In the bijective reading, outcome-values and essential-variable values are conceptually distinct but informationally equivalent under .
Believed acceptable outcome-set
The typist does not initially know the authoritative acceptable outcome-set perfectly. At time , the typist acts under a believed model of the acceptable essential-variable region:
This induces the typist's believed acceptable outcome-set:
In the reduced representation:
From the typist's subjective perspective, an incorrect symbol may initially appear to belong to the acceptable outcome-set. Later checking against the authoritative word reveals that it does not. This is not external goal revision, because and remain fixed. What changes is the typist's believed model: and therefore .
That is goal-model revision, not goal revision.
Closure events
Each typed symbol is a closure event:
where:
- is the closure-event index;
- is the current demand to type a symbol for an intended target position;
- is the selected keypress;
- is the resulting typed outcome-value.
The produced outcome-value is:
where is the intended target position and is the typed symbol.
For example:
z₁ = (1, x) provisionally accepted, later invalidated z₂ = (1, q) provisionally accepted, later invalidated z₃ = (1, H) survives authoritative checking z₄ = (2, o) survives authoritative checking z₅ = (3, n) survives authoritative checking
This preserves the distinction between event order and target position. Events 1, 2, and 3 are three different closure events, but all three attempt to satisfy position 1.
Operational trace
The following trace contains 37 typed closure events. The letters marked with 1 are the closure events that survive authoritative checking. The letters marked with 0 are provisional closure events that are later invalidated.
| Closure event | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Target position pᵤ | 1 | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 13 | 13 | 14 | 15 | 16 | 16 | 17 | 18 | 19 | 19 | 19 | 20 | 21 | 21 | 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| Typed symbol aᵤ | x | q | H | o | n | o | r | e | i | f | i | c | a | b | i | o | r | l | i | t | m | u | d | i | p | v | n | i | y | k | t | a | t | i | b | u | s |
| Ledger status | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
Reading only the surviving closure events, the events marked 1, gives the final accepted output:
Reading the events marked 0 gives the provisional closures that were later rejected:
Provisional closure history
Let the observation window be:
A closure is provisionally accepted when produced if its outcome-value belongs to the typist's believed acceptable outcome-set at that time:
The provisional closure history in the window is:
In this example, all 37 typed symbols were provisionally accepted when produced. Therefore:
Authoritative survival and model invalidation
A provisional closure survives if its produced outcome-value belongs to the authoritative acceptable outcome-set:
The net surviving closures are:
A provisional closure is invalidated by goal-model revision if it was accepted under the believed model when produced, but later judged outside the authoritative acceptable outcome-set:
The goal-model invalidation load is:
Therefore the ledger identity is:
Interpretation
In the reduced case, the typed outcome-value already is the essential-variable value. In the bijective case, the typed outcome-value is a concrete outcome description, and the essential-variable value is the corresponding goal-relevant description.
In this example, the 10 invalidated events are actual typed outputs. Each one was a provisional closure produced under the typist's then-current belief i.e. their model of the goal. Later, after checking the authoritative word in the script, the typist discovered that those provisional closures did not belong to the authoritative acceptable outcome-set.
| Quantity | Value | Meaning |
|---|---|---|
| 37 | All provisionally accepted typed closures. | |
| 27 | Typed closures that survived authoritative checking and form the final word. | |
| 10 | Typed closures invalidated after goal-model revision. |
In this example, the authoritative goal did not change. The word to be typed remained the same. What changed was the regulator's model of the goal. The process therefore involved goal-model revision, invalidation of provisional closures, and corrective replacement, not external goal revision.
Knowledge To Be Discovered perspective
In this example, the demand space is , rthe esponse space is , because the concrete response is the selected keypress or typed symbol . The closure outcome records that response together with the intended target position: . For knowledge accounting, we use the lifted response-equivalence space , where the response class is represented together with the target position, because the required response-class is not merely a symbol, but a symbol-for-a-position, because the closure records which symbol was typed for which intended position.
The task class is: type the correct symbol for a target-word position in “Honorificabilitudinitatibus.” Under that task class, every closure event in the trace is one episode of the same regulatory problem: given a target position p, determine and emit the authoritative symbol required at that position. Thus all closure events in the example are comparable under the same task class They share the same disturbance space , the same concrete response space , the same outcome space , and the same lifted target response-class space .
This example makes explicit why Knowledge To Be Discovered should be defined over the authoritative target response-class, not over the actual response-class emitted by the regulator. The typist produces actual closures, but those closures are not automatically the closures required by the authoritative goal.
For a closure event , the actual produced outcome-class is:
where is the intended target position and is the symbol actually typed.
But the authoritative target response-class for that same event is:
where is the authoritative symbol required at the intended target position.
Thus the central distinction is:
Knowledge To Be Discovered is the remaining uncertainty, given the typist's current information state, about the authoritative target response-class:
In the generic time-indexed notation used elsewhere, this is:
Here represents the disturbance, observation, or demand presented to the regulator at time . In this example, can be read as the current demand to type the symbol for target position . The typist's current knowledge, memory, belief, and goal-model state is represented separately by .
The subscript means that the entropy is evaluated relative to the regulator's current model. The conditioning variable specifies the disturbance or demand currently being faced. In this example, the demand may identify the target position, while the model determines how much uncertainty remains about the authoritative symbol required at that position.
In this example, if the typist is attempting to satisfy position 1, the authoritative target response-class is:
But the actual produced response-classes were:
X₁ = (1, x) actual closure, later invalidated X₂ = (1, q) actual closure, later invalidated X₃ = (1, H) actual closure, survives authoritative checking
Therefore:
This is why the strong alignment assumption:
does not hold during this knowledge-discovery process. The typist's actual closures are not yet reliably aligned with the authoritative target closures. Some actual closures are exploratory, mistaken, provisional, or based on an incorrect believed goal model.
Consequently, the entropy of the actual response-class:
does not necessarily measure Knowledge To Be Discovered. It measures residual variation in what the regulator actually does. That variation may come from several sources: randomness, indecision, exploration, implementation variation, motor error, or even consistently wrong behavior. From an outside black-box perspective, these sources are not directly separable merely by observing the emitted closures.
By contrast:
measures uncertainty about the target response-class that would satisfy the authoritative goal. That is the knowledge the regulator must acquire, infer, retrieve, or otherwise make available in order to close the demand correctly.
Why the ledger is evidence of discovery, not the entropy itself
The closure ledger:
is not itself an information-theoretic entropy identity. It is an operational accounting identity:
The 10 invalidated closures are not 10 bits of Knowledge To Be Discovered. They are observable consequences of acting before the relevant target knowledge was fully available. They show that the typist's believed model allowed closures that the authoritative goal later rejected.
Thus:
measures model-invalidation load, not Knowledge To Be Discovered directly. It is a trace left by knowledge discovery in the closure history. The entropy measure remains:
because the unresolved question is not merely “what will the typist type?” but “what response-class is required for authoritative success, given what the typist currently knows?”
Role of goal-model revision
The authoritative goal does not change in this example. The word remains:
Therefore and remain fixed. What changes is the typist's believed model:
This is why the process is goal-model revision, not external goal revision. The typist discovers that the believed acceptable outcome-set was too permissive. After checking, some provisional closures are removed from the believed acceptable region, and replacement closures are produced.
From the Knowledge To Be Discovered perspective, checking the authoritative word changes the information state:
and therefore can reduce:
When the typist finally knows that position 1 requires H, the uncertainty about the authoritative response-class for that position collapses:
At that point, no further knowledge must be discovered for that particular target-position closure. The remaining task is execution: producing the known required response.
Why this example supports the present definition
This example supports the definition:
because the discovered knowledge is knowledge about the target response-class required for successful regulation. The target is not whatever the regulator happens to emit. The target is the authoritative closure that would place the outcome inside the acceptable region.
The actual response-class can be wrong, exploratory, random, inconsistent, or provisionally accepted under a mistaken model. Therefore:
in the general case.
Only under the strong alignment assumption:
does the actual response-class entropy coincide with target response-class uncertainty:
This example is valuable precisely because it shows that the strong alignment assumption fails during knowledge discovery. The typist does not begin with perfect knowledge of the authoritative target closure. The typist emits closures, invalidates some of them, revises the believed goal model, and eventually aligns actual closures with authoritative target closures.
A Realized Knowledge Discovery Trace
This example shows how a concrete execution trace can be used to estimate the amount of knowledge discovered during a task. The purpose of the example is not to estimate the entropy of English, nor the entropy of a word. The purpose is to make visible the knowledge-discovery burden experienced during one realized execution of one task.
The Task
Consider the task of typing the word “Honorificabilitudinitatibus” on a keyboard. The word has 27 letters. The manual part of the task is to press the correct keys. The knowledge part of the task is to know which 27 letters must be typed, and in which order.
In this example, the typist does not remember the whole word at once. Sometimes the next required letter is already available from memory. At other times, the typist has to stop, think, or look up the word again. We record this process with a binary trace:
- 1 means the required next letter was already available for action.
- 0 means the typist was missing information and had to ask a question, think, or look up the word before continuing.
Thus, the ones are the surviving closures of the process — the letters that actually land — and the zeros are the missing-information intervals that separate them. This 0/1 string is the ground truth of what happened inside the process. A strict black-box observer does not see it: the zeros are not directly observable as such. We display the full trace here only to make the underlying process concrete. What the observer actually records is which letters landed and how much clock time the window afforded. The missing-information intervals are recovered afterward as a residual, not counted off the trace.
The Trace and What Is Actually Observed
The ground-truth trace — shown here for illustration, not as observer-side data — can be summarized as follows. The column records the missing-information intervals that in fact occurred in each subset; under the black-box regime these are inferred, not seen, and are listed here only so the arithmetic can be followed.
| Segment | Trace | Questions \(Q_i\) | Typed letters \(S_i\) | Missing information \(H_i = Q_i / S_i\) | Total intervals \(N_i = Q_i + S_i\) |
|---|---|---|---|---|---|
| Initial lookup and first remembered chunk | 00 11111 |
2 | 5 | 2/5 | 7 |
| Second remembered chunk | 0 1111111 |
1 | 7 | 1/7 | 8 |
| Third remembered chunk | 00 111 |
2 | 3 | 2/3 | 5 |
| Fourth remembered chunk | 0 111 |
1 | 3 | 1/3 | 4 |
| Fifth remembered chunk | 00 11 |
2 | 2 | 2/2 | 4 |
| Final remembered chunk | 00 1111117 |
2 | 7 | 2/7 | 9 |
| Total | Realized execution trace | \(\sum Q_i = 10\) | \(\sum S_i = 27\) | \(\sum N_i = 37\) |
Note: The observer's route to is the clock, not this sum. The observer sees 37 clock ticks, and the 27 letters that actually land. The 10 missing-information intervals are inferred as a residual, not directly observed.
Two quantities are available to a black-box observer of this window.
First, the surviving closures. Twenty-seven letters landed, so . This is read directly from the closure ledger.
Second, the window capacity. Under the declared convention, one closure-act-equivalent unit is the time to commit one letter, of normalized duration . The window's elapsed clock time affords 37 such units, so This count comes from the clock and the unit convention, not from any tally of missing-information intervals.
The residual is then inferred, not observed: The ten missing-information intervals are the closure-act capacity the window afforded but did not convert into surviving closures. They are recovered from and ; the observer never counts them directly.
Aggregating Missing Information Across Subsets
The trace can also be analyzed by decomposing the task into six subsets. Each subset has its own number of inferred, not counted questions , its own number of typed symbols , and therefore its own local missing-information value:
However, the total missing information for the whole task is not obtained by simply summing the six values, nor by taking their unweighted arithmetic average. The subsets have different sizes. A subset of seven typed symbols must contribute more to the aggregate value than a subset of two typed symbols.
Therefore, the aggregate missing information is computed as a weighted average, where each local value \(H_i\) is weighted by the proportion of symbols in that subset:
Here:
- is the number of subsets;
- is the number of typed symbols in subset ;
- is the number of questions in subset ;
- is the missing information in subset ;
- is the total number of intervals in subset ;
- is the total number of typed symbols.
Using the six subsets from the table:
So the aggregate missing information remains \(0.37\) missing-information units per typed symbol. The subset calculation gives the same result as the direct calculation, but it makes clear why the local \(H_i\) values must be weighted by subset size.
Subset missing-information values cannot be added directly. The correct aggregate is the symbol-weighted average: .
The Operational Estimator
The effective one-bit-equivalent Knowledge To Be Discovered over this interval is:
Substituting the observed values gives:
So, in this realized execution, the typist needed approximately 0.37 inferred, not counted missing-information units per typed symbol.
Why This Corresponds to
The important point is that this calculation is based on the actual observed knowledge state of the typist during the task. We are not averaging over all possible memory states, all possible words, or all possible observations. We are looking at the realized case: this typist, this word, this sequence of remembered and forgotten chunks.
For that reason, the corresponding latent quantity is the realized row-level conditional uncertainty:
Here, is the required response-equivalence class for closure event , and is the actual knowledge state available at the start of that episode. The estimator uses the realized value , not the full distribution of possible values of .
By contrast, would be an ex-ante quantity. It would require a probability distribution over possible knowledge states before the realized state is known. That is not what the trace records. The trace records what actually happened.
What if changes?
The above definitions assume that the essential-variable space and the outcome-to-essential-variable map are held fixed. Under that assumption, addition, deletion, and substitution are changes in acceptability-status caused by a change in the acceptable region .
if changes, then the logic changes conceptually. This is not merely a different acceptable region. It is a different evaluative model: different dimensions of what counts as goal-relevant.
That matters because Ashby treats the system as a set of variables selected for analysis; changing the selected variables changes the modeled system/criterion, not just the acceptable subset. Ashby's framework is explicitly functional and behavior-oriented rather than material-object-oriented, so the selected variables are part of the formal description[1]. Umpleby also emphasizes that, for Ashby, the “system” is a set of variables selected by an observer[57].
If the essential-variable space itself changes, then the change is no longer merely a revision of the acceptable region. It is a change in the evaluative model. In that more general case, one would write and . The acceptable outcome-set would still be comparable across time if the outcome-space remains fixed:
In that case, deletion, addition, and substitution can still be defined as set differences inside , but their interpretation changes: they may result from a changed acceptable region, a changed essential-variable space, a changed mapping from outcomes to essential variables, or some combination of these.
If the outcome-space remains fixed, then we can still define:
Now both acceptable outcome-sets are again subsets of the same , so our deletion/addition/substitution logic still works.
But the interpretation is different.
The change may now be caused by:
- a changed acceptable region
- a changed essential-variable space
- a changed outcome-to-essential-variable map
- or some combination of the above.
So we can still say: outcome-value z lost acceptability, but we should not say: z lost acceptability only because the goal region changed.
It may have lost acceptability because the system is now being evaluated through different essential variables.
Example
At , suppose success is evaluated only by temperature:
At , success is evaluated by temperature and blood sugar:
An outcome z that was acceptable at may become unacceptable at , not because the acceptable temperature range changed, but because blood sugar is now included as a goal-relevant dimension.
So the outcome has been “deleted” from the acceptable outcome-set, but this deletion comes from a change in evaluation space, not merely a narrower acceptable region.
In summary, changing does not destroy the deletion/addition/substitution logic if we compare pulled-back acceptable outcome-sets inside the same fixed . But it changes the meaning of those changes. They are no longer purely goal-region revisions; they may be changes in the evaluative model itself.
What learning could also do (but we are explicitly excluding)
Not every form of learning improves regulation H(E|Y) in Ashby's sense. Other possibilities include:
-
Expanding action variety without selectivity
Learning might increase (more possible actions, tools, behaviors) without reducing .
- The system becomes more capable in principle
- But still does not know which action to take
- Regulation does not improve
This violates Ashby's requirement that variety must be constrained, not merely expanded.
-
Improving buffering instead of knowledge
Learning might increase buffering capacity (delay, slack, tolerance), so disturbances are absorbed without better action selection.
- Outcomes may improve
- But does not increase
- Regulation improves without learning the mapping
This is explicitly separated from knowledge in Ashby's extended formulation.
-
Changing goals or success criteria
Learning could redefine what counts as success .
- Apparent performance improves
- But the structural coupling (mapping) is unchanged
- Information-theoretically, nothing about need change
This is semantic drift, not cybernetic learning.
-
One-off adaptation without structural retention
The system may succeed through exploration without storing the result.
- Regulation succeeds this time
- Next encounter repeats the same uncertainty
- No accumulation of
This is regulation, not learning.
Cumulative Knowledge To Be Discovered
Using
Cumulative w.r.t. S
Choose a baseline > 0.
Define:
Key properties:
- → is concave in .
Domain: ∈ (0, N]. Since > 0 for , increases with (for ) and is finite as long as .
Useful normalizations:
Dimensionless form with :
Total cumulative up to completion S = N:
This can be thought of as the total knowledge-effort curve or “cumulative residual variety as a function of performance level” i.e. how much “knowledge work” has been consumed to reach performance level S.
Fig.2 Total Knowledge-Effort Curve Here we see the cumulative residual variety as a function of performance level.
- Blue curve: instantaneous 𝐻(𝑆)=𝑁/𝑆−1H(S)=N/S−1 (residual variety ratio).
- Green dashed curve: cumulative residual variety C(S) as we accumulate uncertainty over growing performance level S.
How to cite:
Bakardzhiev D.V. (2025) Knowledge Discovery Efficiency (KEDE) and Ashby's Law https://docs.kedehub.io/knowledge-centric-research/kede-ashbys-law.html
Works Cited
1. Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal. 1948;27(3):379-423. doi:10.1002/j.1538-7305.1948.tb01338.x
2. Ashby, W.R. (1956). An Introduction to Cybernetics; Chapman & Hall,
3. Ashby, W. R. (2011). Variety, Constraint, And The Law Of Requisite Variety. 13, 18.
4. MacKay, D. M. (1950). Quanta! aspects of scientific information. Philosophical Magazine; 41, 289-311;
5. Cover, T. M. and Thomas, J. A. (1991), Elements of Information Theory, John Wiley and Sons, New York. page.95 in 5.7 SOME COMMENTS ON HUFFMAN CODES
6. Wheeler, J. A. (1990). Information, physics, quantum: The search for links. In W. H. Zurek (Ed.), Complexity, entropy, and the physics of information (Vol. 8, pp. 3'-28). Taylor & Francis.
7. Yaneer Bar-Yam.(2004) Multiscale variety in complex systems. Complexity, 9(4):37{45,
8. Ashby, W.R. (1991). Requisite Variety and Its Implications for the Control of Complex Systems. In: Facets of Systems Science. International Federation for Systems Research International Series on Systems Science and Engineering, vol 7. Springer, Boston, MA. https://doi.org/10.1007/978-1-4899-0718-9_28
9. Shannon, C. E. Communication theory of secrecy systems. Bell System technical Journal, 28, 656-715, 1949
10. Kubatko J, Oliver D, Pelton K, et al. A starting point for analyzing basketball statistics. J Quant Anal Sports 2007; 3: 1'-22.
11. Sports Reference LLC. "NBA League Averages." Basketball-Reference.com - Basketball Statistics and History. https://www.basketball-reference.com/leagues/NBA_stats_totals.html.
12. Bucks post highest single-game field-goal percentage by any team in 21st century https://sports.yahoo.com/article/bucks-post-highest-single-game-040313061.html
13. https://www.statmuse.com/nba/ask/most-field-goals-made-record-in-a-game-nba-player
14. Lewis, G. J., & Stewart, N. (2003). The measurement of environmental performance: an application of Ashby's law. Systems Research and Behavioral Science, 20(1), 31'-52. https://doi.org/10.1002/sres.524
15. Norman, J., & Bar-Yam, Y. (2018). Special Operations Forces: A Global Immune System? In Springer Unifying Themes in Complex Systems IX (pp. 486'-498). Springer International Publishing. https://doi.org/10.1007/978-3-319-96661-8_50
16. Norman, J., & Bar-Yam, Y. (2019). Special Operations Forces as a Global Immune System. In Springer Evolution, Development and Complexity (pp. 367'-379). Springer International Publishing. https://doi.org/10.1007/978-3-030-00075-2_16
17. O'Grady, W., Morlidge, S., & Rouse, P. (2014). Management Control Systems: A Variety Engineering Perspective. SSRN Electronic Journal. https://doi.org/10.2139/ssrn.2351099
18. Love, T., & Cooper, T. (2007). Digital Eco-systems Pre-Design: Variety Analyses, System Viability and Tacit System Control Mechanisms. 2007 Inaugural IEEE-IES Digital EcoSystems and Technologies Conference, 452'-457. https://doi.org/10.1109/dest.2007.372013
19. Love, T., & Cooper, T. (2007). Complex built‐environment design: four extensions to Ashby. Kybernetes, 36(9/10), 1422'-1435. https://doi.org/10.1108/03684920710827391
20. Bushey, D. B., & Nissen, M. E. (1999). A Systematic Approach to Prioritizing Weapon System Requirements and Military Operations Through Requisite Variety. Defense Technical Information Center. https://doi.org/10.21236/ada371943
21. Jones, H. P. (2018). Evolutionary stakeholder discovery: requisite system sampling for co-creation.
22. Grimm, D. A. P., Gorman, J. C., Robinson, E., & Winner, J. (2022). Measuring Adaptive Team Coordination in an Enroute Care Training Scenario. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 66(1), 50'-54. https://doi.org/10.1177/1071181322661074
23. Becker Bertoni, V., Abreu Saurin, T., & Sanson Fogliatto, F. (2022). Law of requisite variety in practice: Assessing the match between risk and actors' contribution to resilient performance. Safety Science, 155, 105895. https://doi.org/10.1016/j.ssci.2022.105895
24. Tworek, K., Walecka-Jankowska, K., & Zgrzywa-Ziemak, A. (2019). Towards organisational simplexity — a simple structure in a complex environment. Engineering Management in Production and Services, 11(4), 43'-53. https://doi.org/10.2478/emj-2019-0032
25. Chester, M. V., & Allenby, B. (2022). Infrastructure autopoiesis: requisite variety to engage complexity. Environmental Research: Infrastructure and Sustainability, 2(1), 012001. https://doi.org/10.1088/2634-4505/ac4b48
26. van der Hoek, M., Beerkens, M., & Groeneveld, S. (2021). Matching leadership to circumstances? A vignette study of leadership behavior adaptation in an ambiguous context. International Public Management Journal, 24(3), 394'-417. https://doi.org/10.1080/10967494.2021.1887017
27. Ulrik, S., & Isabella, A. (2023). Variety versus speed: how variety in competence within teams may affect performance in a dynamic decision-making task.
28. Bakardzhiev, D., Vitanov, N.K. (2025). KEDE (KnowledgE Discovery Efficiency): A Measure for Quantification of the Productivity of Knowledge Workers. In: Georgiev, I., Kostadinov, H., Lilkova, E. (eds) Advanced Computing in Industrial Mathematics. BGSIAM 2022. Studies in Computational Intelligence, vol 641. Springer, Cham. https://doi.org/10.1007/978-3-031-76786-9_3
29. Heylighen, F., & Joslyn, C. (2001). Cybernetics and Second Order Cybernetics. In R. A. Meyers (Ed.), Encyclopedia of Physical Science and Technology, Eighteen-Volume Set, Third Edition (pp. 155-170). Academia Press. http://pespmc1.vub.ac.be/Papers/Cybernetics-EPST.pdf
30. Schwaninger, M., & Ott, S. (2024). What is variety engineering and why do we need it? Systems Research and Behavioral Science, 41(2), 235'-246. https://doi.org/10.1002/sres.2964
31. AULIN‐AHMAVAARA, A.Y. (1979), "THE LAW OF REQUISITE HIERARCHY", Kybernetes, Vol. 8 No. 4, pp. 259-266. https://doi.org/10.1108/eb005528
32. Wu, T., Dufford, A. J., Mackie, M. A., Egan, L. J., & Fan, J. (2016). The Capacity of Cognitive Control Estimated from a Perceptual Decision Making Task. Scientific Reports, 6, 34025.
33. Abuhamdeh S (2020) Investigating the “Flow” Experience: Key Conceptual and OperationalIssues. Front. Psychol. 11:158.doi: 10.3389/fpsyg.2020.00158
34. Automatic Screw Tightening Machine and Its Hidden Features
35. Keating, C. B., Katina, P. F., Jaradat, R., Bradley, J. M., & Hodge, R. (2019). Framework for improving complex system performance. INCOSE International Symposium, 29(1), 1218-1232. https://doi.org/10.1002/j.2334-5837.2019.00664.x
36. S. Engell (1985). An information-theoretical approach to regulation.
37. K. Kijima, Y. Takahara, B. Nakano (1986). ALGEBRAIC FORMULATION OF RELATIONSHIP BETWEEN A GOAL SEEKING SYSTEM AND ITS ENVIRONMENT.
38. W. Kickert, J. Bertrand, J. Praagman (1978). Some Comments on Cybernetics and Control. IEEE Transactions on Systems, Man and Cybernetics.
39. S. Engell (1985). Information-theoretical bounds for regulation accuracy. IEEE Conference on Decision and Control.
40. Hui Zhang, Youxian Sun (2003). Bode integrals and laws of variety in linear control systems. Proceedings of the 2003 American Control Conference, 2003.
41. R. Conant (1969). The Information Transfer Required in Regulatory Processes. IEEE Transactions on Systems Science and Cybernetics.
42. S. Engell (1987). Analysis of Regulation Problems based on Real-Time Rate-Distortion Theory. American Control Conference.
43. Hui Zhang, Youxian Sun (2003). Information theoretic limit and bound of disturbance rejection in LTI systems: Shannon entropy and H/sub /spl infin// entropy. SMC'03 Conference Proceedings. 2003 IEEE International Conference on Systems, Man and Cybernetics. Conference Theme - System Security and Assurance (Cat. No.03CH37483).
44. N. C. Martins, M. Dahleh (2008). Feedback Control in the Presence of Noisy Channels: “Bode-Like” Fundamental Limitations of Performance. IEEE Transactions on Automatic Control.
45. Hui Zhang, Youxian Sun (2003). H/sub /spl infin// entropy and the law of requisite variety. 42nd IEEE International Conference on Decision and Control (IEEE Cat. No.03CH37475).
46. Tsuji, M., Crookshank, M., Olsen, M., Schemitsch, E. H., & Zdero, R. (2013). The biomechanical effect of artificial and human bone density on stopping and stripping torque during screw insertion. Journal of the mechanical behavior of biomedical materials, 22, 146'-156. https://doi.org/10.1016/j.jmbbm.2013.03.006
47. Akizuki, K., & Ohashi, Y. (2015). Measurement of functional task difficulty during motor learning: What level of difficulty corresponds to the optimal challenge point?. Human movement science, 43, 107'-117. https://doi.org/10.1016/j.humov.2015.07.007
48. Bootsma, J. M., Hortobágyi, T., Rothwell, J. C., & Caljouw, S. R. (2018). The Role of Task Difficulty in Learning a Visuomotor Skill. Medicine and science in sports and exercise, 50(9), 1842'-1849. https://doi.org/10.1249/MSS.0000000000001635
49. Akizuki, K., & Ohashi, Y. (2013). Changes in practice schedule and functional task difficulty: a study using the probe reaction time technique. Journal of physical therapy science, 25(7), 827'-831. https://doi.org/10.1589/jpts.25.827
50. Goldhammer, F.; Naumann, J.; Stelter, A.; Tóth, K.; Rölke, H.; Klieme, E.: The time on task effect in reading and problem solving is moderated by task difficulty and skill. Insights from a computer-based large-scale assessment - In: The Journal of educational psychology 106 (2014) 3, S. 608-626 - URN: urn:nbn:de:0111-pedocs-179679 - DOI: 10.25656/01:17967; 10.1037/a0034716
51. Boothroyd, G., and P. Dewhurst, "DESIGN FOR ASSEMBLY", Dept. of Mechanical Engineering, University of Massachusetts, Amherst, Massachusetts, 1983.
52. Jahin, A., Zidan, A. H., Bao, Y., Liang, S., Liu, T., & Zhang, W. (2025). Unveiling the mathematical reasoning in deepseek models: A comparative study of large language models. arXiv preprint arXiv:2503.10573.
53. FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
54. Francis Heylighen, Cybernetic Principles of Aging and Rejuvenation: The Buffering- Challenging Strategy for Life Extension, Current Aging Science; Volume 7, Issue 1, Year 2014, . DOI: 10.2174/1874609807666140521095925
55. Ostry, D. J. (1980). Execution-time movement control. In G. E. Stelmach & J. Requin (Eds.), Tutorials in motor behavior (pp. 457-468). Amsterdam: North-Holland.
56. Siegenfeld, A. F., & Bar-Yam, Y. (2025). A Formal Definition of Scale-Dependent Complexity and the Multi-Scale Law of Requisite Variety. Entropy, 27(8), 835. https://doi.org/10.3390/e27080835
57. Umpleby, S. A. (2009). Ross Ashby's general theory of adaptive systems. International Journal of General Systems, 38(2), 231–238. https://doi.org/10.1080/03081070802601509
58. Zheng, J., & Meister, M. (2024). The unbearable slowness of being: Why do we live at 10 bits/s?. Neuron.
59. Ohlsson, S. (1992). The Learning Curve for Writing Books: Evidence from Professor Asimov. Psychological Science, 3(6), 380-382.
60. L. B.S. Raccoon. 1996. A learning curve primer for software engineers. SIGSOFT Softw. Eng. Notes 21, 1 (Jan 1 1996), 77–86. https://doi.org/10.1145/381790.381805
Getting started


