Incremental and Iterative Software Development
A Knowledge-Centric Perspective
Introduction
"Skill to do comes of doing; knowledge comes by eyes always open and working hands." ~ Ralph Waldo Emerson, essay Old Age, included in the collection Society and Solitude (1870)
In software development and beyond, the terms iterative and incremental are often used to describe approaches to building systems or solving problems. Traditionally, these terms are understood from a functionalist perspective: incremental refers to adding new features, while iterative involves refining existing ones. These definitions are rooted in observable outputs, such as software deliverables or product features.
However, from a Knowledge-centric Perspective., the traditional understanding of “development” as 'adding features' becomes insufficient because we focus on acquiring invisible missing knowledge rather than building observable functionality. Here, the focus shifts from what is built to how knowledge evolves. When analyzing data, developing software, or solving problems, practitioners often grapple with incomplete, evolving, or ambiguous information. Understanding how knowledge is constructed - whether incrementally, iteratively, or a combination of both - is essential for improving the efficiency and effectiveness of discovery processes.
This requires a new understanding of the words iterative and incremental and a redefinition from a Knowledge-centric Perspective.. By doing so, we aim to provide a fresh lens through which to view these terms, highlighting their relevance not only to software development but to any field where learning and adaptation are central to success.
Incremental
In the knowledge discovery paradigm, incremental takes on a new meaning: a bit of information is discovered and retained before the next bit is added. It is akin to laying bricks - each brick contributes to the structure without removing or altering the ones already placed. Therefore, when we add knowledge without deleting or invalidating previously discovered knowledge, we are operating in incremental mode.
This idea is best illustrated through a simple example: consider how the longest English word, Honorificabilitudinitatibus, might be typed incrementally. Each letter is added without ever deleting or revising earlier ones, building the complete word step by step.
|
|
|
H | o | n | o | r |
|
i | f | i | c | a | b | i |
|
|
l | i | t |
|
u | d | i |
|
|
n | i |
|
|
t | a | t | i | b | u | s |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
The process demonstrates that incremental discovery focuses on cumulative progress without loss or waste.
A more compelling visualization of this concept is provided by the "Incrementing Mona Lisa" (Source: Jeff Patton)

In this example, imagine that each pixel's color represents a unit of knowledge discovered. The painting begins as an outline and progressively gains detail as each pixel is filled. At no point are earlier pixels erased or replaced. The result is an evolving masterpiece where every new discovery builds on the previous one without discarding or altering established work. This highlights the essence of incremental knowledge discovery: additions enrich the whole while preserving the integrity of what is already known.
Understanding knowledge discovery as an incremental process is crucial because it shifts the focus from building isolated outputs to developing cumulative insights. This perspective minimizes redundancy, avoids rework, and ensures that every new piece of information adds lasting value. Moreover, it encourages practitioners to align their efforts toward progress without waste, fostering a culture of continuous improvement
Iterative
Though incremental knowledge discovery ideally builds without loss, there are cases where incomplete or incorrect knowledge must be adjusted. This is where the iterative process comes in. In iterative mode, prior knowledge is revisited, refined, or replaced with new knowledge.
For example, if I were to type the word Honorificabilitudinitatibus iteratively, the process might unfold as follows:
|
|
|
H | o | n | o | r | X | X |
|
i | f | i | c | a | b | i | X |
|
|
l | i | t | X |
|
u | d | i |
|
|
n | i |
|
|
t | a | t | i | b | u | s |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
After typing "Honor," I added two letters incorrectly, marked as "X." These errors occurred because I believed I had the correct knowledge but didn’t. Later I identified the mistakes and replaced them. This pattern repeated throughout, leading to four corrections. This illustrates the iterative nature of knowledge discovery - correcting and refining based on new information
The concept is further illustrated by the "Iterating Mona Lisa (Source: Jeff Patton)
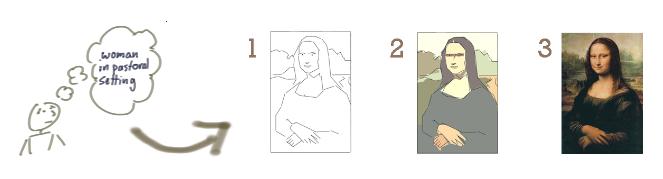
Here, each pixel represents a piece of knowledge. As the painting progresses, previously discovered pixels (knowledge) are revisited and refined based on new information. This way of working resembles the painting technique, called "sfumato," which is to apply many translucent layers (glazes), mainly composed of an organic medium in very thin films, down to a micrometer scale. For instance the flesh tones were usually obtained by superimposing four layers: 1) the priming layer made of lead white, 2) a pink layer based on a mixture of lead white, vermilion, and earth, 3) a shadow layer made with a translucent glaze or an opaque paint (with dark pigments), and 4) varnish. Specialists from the Center for Research and Restoration of the Museums of France found that da Vinci painted up to 30 layers of paint on Mona Lisa[1]. This iterative refinement manifests the way we refine knowledge, layer by layer, until it aligns with our evolving understanding
A similar process can be observed in literature. Leo Tolstoy's epic War and Peace took six years to write, during which he rewrote the manuscript by hand at least eight times. Individual scenes were revised as many as 26 times. This iterative refinement allowed Tolstoy to align his narrative with his deepening insights. The parallels to software development are clear: we constantly refine code to match our evolving knowledge of what to build and how to build it.
Both da Vinci’s and Tolstoy’s iterative approaches illustrate the value of revisiting and refining prior work, ensuring the final product reflects a deeper understanding and mastery - a process mirrored in knowledge discovery as we replace incomplete or incorrect knowledge with refined insights. That is very much what software developers do on a daily basis. We constantly refine the code in order to match the constantly changing knowledge about what to build and how to build it.
An example of that is Scrum, which is both iterative and incremental. The entire Scrum team is accountable for creating a valuable, useful Increment every Sprint. The development team takes a first cut at a system, knowing it is incomplete or weak in perhaps many areas. The team then iteratively refines those areas until the result is satisfactory. With each iteration, the software is improved through the addition of the knowledge discovered.
Another example of an iterative and incremental process is the Rational Unified Process (RUP). The RUP has determined a project life-cycle consisting of four phases. Each phase has one key objective and milestone at the end that denotes the objective being accomplished. Inside each of the phases the development process is iterative.
In iterative knowledge discovery, each cycle builds upon the evolving understanding of what needs to be delivered and how to deliver it. This is especially valuable in complex domains where initial knowledge is incomplete or assumptions may need revising.
Below we have drawing Mona Lisa Iteratively and Incrementally (Source: Steven Thomas)
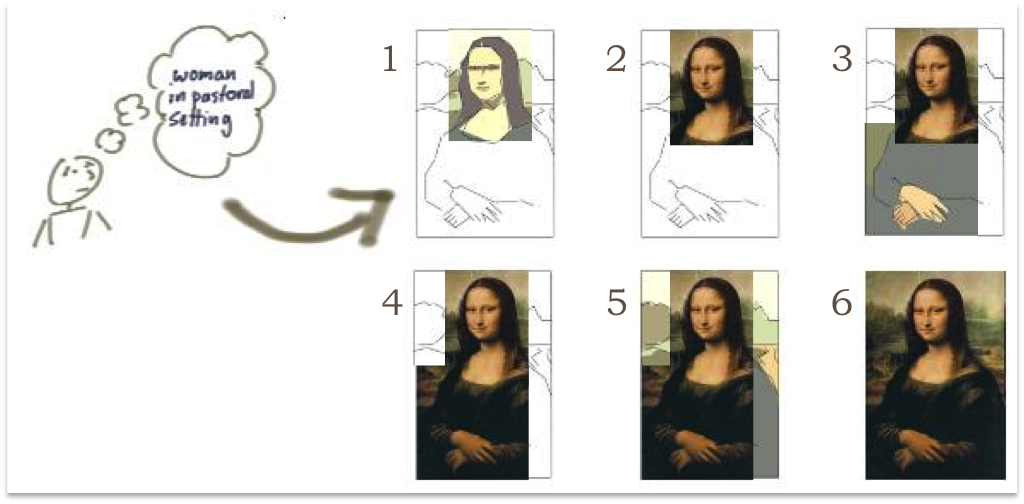
The Increment adds completely new features i.e. expanding the scope of the functionality offered. Each increment is refined iteratively and likely to refine existing functionality. Inside each increment prior knowledge is dropped and replaced by new knowledge.
Yet another example is found in the case of MVP aka Minimum Viable Product. This is different from the three approaches above in that the goal here is to start with the smallest thing that can be put in the hands of real users they can actually use!
Below we have a drawing of the context of MVP (Source: Henrik Kniberg)
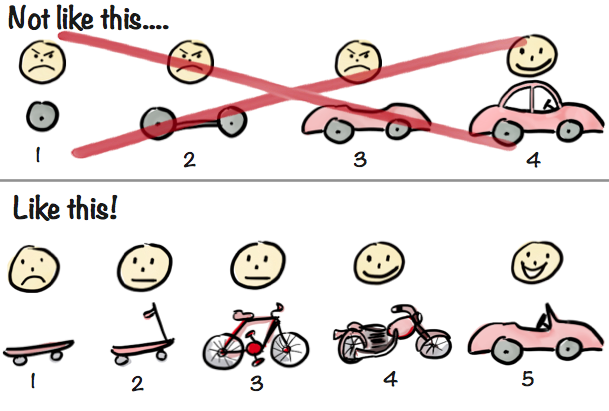
The top scenario (crossed with red lines) is the incremental approach we discussed above. In the context of a new startup business it fails us because we keep delivering stuff that the customer can't use at all. However, from a knowledge discovery perspective it is the most efficient use of software development time. Some may say that this is applicable in a mass production of goods only. That's not correct. This way they produce most of the luxury cars like Rolls-Royce, Ferrari F40 and Mclaren F1 to name a few. Those cars feature numerous proprietary designs and technologies. That means a lot of knowledge is there in them.
The bottom scenario describes what usually happens when the company lacks a lot of knowledge both in regards "What" needs to be delivered and/or "How" to deliver the "What". Such a context is the natural habitat of technology startups. We start with a skateboard and end up with a convertible. Between them we have a scooter, a bike and a motorcycle. Let's not forget that here we look not from a functionalist perspective but from a knowledge discovery perspective. Hence the question is - what can we say about the knowledge discovery process?
We can safely say that to acquire the knowledge to build a bike one needs to ask much less questions than to acquire the knowledge to build a car. That's correct simply because a car has some 59,999 parts and a bile less than 20 parts. Since a skateboard probably has no common parts with a bike we can say that the knowledge acquired to build the skateboard is lost when we decide to build a bike. Hence we could conclude that we have 100% waste on each transformation from a skateboard to a car.
However let's not forget that not all of the knowledge is in the tangible output - a car or a source code. Some of it, and people may say most of it is located in the heads of the knowledge workers. Hence the percentage of waste is never 100%.
By quantifying waste in knowledge work, we can not only validate the principles of approaches like Lean Startup but also identify specific opportunities to optimize the iterative discovery process, making it more efficient and effective.
Though tangible outputs may involve high levels of waste during transformations, iterative processes ensure that intangible knowledge - the skills, insights, and experience gained—is carried forward, minimizing overall inefficiency
Conclusion
The concepts of incremental and iterative discovery, though rooted in traditional software development practices, reveal profound insights when viewed through the lens of the Knowledge-centric Perspective.. By redefining these terms, we uncover new ways to think about how knowledge is acquired, refined, and applied in dynamic environments.
Incremental knowledge discovery emphasizes accumulation without loss - each piece of knowledge builds upon the previous, contributing to a growing repository of understanding. Like laying bricks or filling in pixels on a canvas, it is a process of additive progress, where nothing valuable is wasted or discarded.
Iterative knowledge discovery, on the other hand, embraces refinement and adaptation. It acknowledges that knowledge is rarely perfect or complete on the first pass. By revisiting and revising prior insights, iterative processes allow us to align our understanding with the realities of an ever-changing context. This approach mirrors the layering of translucent glazes in painting or the rewriting of scenes in a novel, reflecting the natural evolution of mastery.
Together, these approaches are not mutually exclusive but complementary. The best practices in knowledge discovery often involve a balance—incrementally building upon reliable knowledge while iteratively refining areas of uncertainty. Frameworks like Scrum and methodologies like Lean Startup demonstrate the power of blending these approaches to navigate complexity, reduce waste, and deliver value.
Ultimately, the Knowledge-centric Perspective. reframes the familiar terms incremental and iterative as tools for understanding how we learn and adapt. Whether building software, creating art, or solving complex problems, this dual lens encourages us to value both steady accumulation and thoughtful revision. It reminds us that progress, whether made brick by brick or layer by layer, is always a journey of discovery.
Works Cited
1. de Viguerie, P. Walter, E. Laval, B. Mottin, and V. A. Solé, “Revealing the sfumato Technique of Leonardo da Vinci by X-Ray Fluorescence Spectroscopy,” Angewandte Chemie International Edition, vol. 49, no. 35, pp. 6125–6128, 2010, doi: 10.1002/anie.201001116
Getting started


